 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Nash Learning from Human Feedback via Mirror Prox
May 26, 2025Traditional Reinforcement Learning from Human Feedback (RLHF) often relies on reward models, frequently assuming preference structures like the Bradley-Terry model, which may not accurately capture the complexities of real human preferences (e.g., intransitivity). Nash Learning from Human Feedback (NLHF) offers a more direct alternative by framing the problem as finding a Nash equilibrium of a game defined by these preferences. In this work, we introduce Nash Mirror Prox ($\mathtt{Nash-MP}$), an online NLHF algorithm that leverages the Mirror Prox optimization scheme to achieve fast and stable convergence to the Nash equilibrium. Our theoretical analysis establishes that Nash-MP exhibits last-iterate linear convergence towards the $\beta$-regularized Nash equilibrium. Specifically, we prove that the KL-divergence to the optimal policy decreases at a rate of order $(1+2\beta)^{-N/2}$, where $N$ is a number of preference queries. We further demonstrate last-iterate linear convergence for the exploitability gap and uniformly for the span semi-norm of log-probabilities, with all these rates being independent of the size of the action space. Furthermore, we propose and analyze an approximate version of Nash-MP where proximal steps are estimated using stochastic policy gradients, making the algorithm closer to applications. Finally, we detail a practical implementation strategy for fine-tuning large language models and present experiments that demonstrate its competitive performance and compatibility with existing methods.
RL-finetuning LLMs from on- and off-policy data with a single algorithm
Mar 25, 2025We introduce a novel reinforcement learning algorithm (AGRO, for Any-Generation Reward Optimization) for fine-tuning large-language models. AGRO leverages the concept of generation consistency, which states that the optimal policy satisfies the notion of consistency across any possible generation of the model. We derive algorithms that find optimal solutions via the sample-based policy gradient and provide theoretical guarantees on their convergence. Our experiments demonstrate the effectiveness of AGRO in both on-policy and off-policy settings, showing improved performance on the mathematical reasoning dataset over baseline algorithms.
Optimal Design for Reward Modeling in RLHF
Oct 23, 2024

Reinforcement Learning from Human Feedback (RLHF) has become a popular approach to align language models (LMs) with human preferences. This method involves collecting a large dataset of human pairwise preferences across various text generations and using it to infer (implicitly or explicitly) a reward model. Numerous methods have been proposed to learn the reward model and align a LM with it. However, the costly process of collecting human preferences has received little attention and could benefit from theoretical insights. This paper addresses this issue and aims to formalize the reward training model in RLHF. We frame the selection of an effective dataset as a simple regret minimization task, using a linear contextual dueling bandit method. Given the potentially large number of arms, this approach is more coherent than the best-arm identification setting. We then propose an offline framework for solving this problem. Under appropriate assumptions - linearity of the reward model in the embedding space, and boundedness of the reward parameter - we derive bounds on the simple regret. Finally, we provide a lower bound that matches our upper bound up to constant and logarithmic terms. To our knowledge, this is the first theoretical contribution in this area to provide an offline approach as well as worst-case guarantees.
Preference Optimization with Multi-Sample Comparisons
Oct 16, 2024Recent advancements in generative models, particularly large language models (LLMs) and diffusion models, have been driven by extensive pretraining on large datasets followed by post-training. However, current post-training methods such as reinforcement learning from human feedback (RLHF) and direct alignment from preference methods (DAP) primarily utilize single-sample comparisons. These approaches often fail to capture critical characteristics such as generative diversity and bias, which are more accurately assessed through multiple samples. To address these limitations, we introduce a novel approach that extends post-training to include multi-sample comparisons. To achieve this, we propose Multi-sample Direct Preference Optimization (mDPO) and Multi-sample Identity Preference Optimization (mIPO). These methods improve traditional DAP methods by focusing on group-wise characteristics. Empirically, we demonstrate that multi-sample comparison is more effective in optimizing collective characteristics~(e.g., diversity and bias) for generative models than single-sample comparison. Additionally, our findings suggest that multi-sample comparisons provide a more robust optimization framework, particularly for dataset with label noise.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving
May 20, 2024



Metacognitive knowledge refers to humans' intuitive knowledge of their own thinking and reasoning processes. Today's best LLMs clearly possess some reasoning processes. The paper gives evidence that they also have metacognitive knowledge, including ability to name skills and procedures to apply given a task. We explore this primarily in context of math reasoning, developing a prompt-guided interaction procedure to get a powerful LLM to assign sensible skill labels to math questions, followed by having it perform semantic clustering to obtain coarser families of skill labels. These coarse skill labels look interpretable to humans. To validate that these skill labels are meaningful and relevant to the LLM's reasoning processes we perform the following experiments. (a) We ask GPT-4 to assign skill labels to training questions in math datasets GSM8K and MATH. (b) When using an LLM to solve the test questions, we present it with the full list of skill labels and ask it to identify the skill needed. Then it is presented with randomly selected exemplar solved questions associated with that skill label. This improves accuracy on GSM8k and MATH for several strong LLMs, including code-assisted models. The methodology presented is domain-agnostic, even though this article applies it to math problems.
Understanding the performance gap between online and offline alignment algorithms
May 14, 2024



Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
Human Alignment of Large Language Models through Online Preference Optimisation
Mar 13, 2024



Ensuring alignment of language models' outputs with human preferences is critical to guarantee a useful, safe, and pleasant user experience. Thus, human alignment has been extensively studied recently and several methods such as Reinforcement Learning from Human Feedback (RLHF), Direct Policy Optimisation (DPO) and Sequence Likelihood Calibration (SLiC) have emerged. In this paper, our contribution is two-fold. First, we show the equivalence between two recent alignment methods, namely Identity Policy Optimisation (IPO) and Nash Mirror Descent (Nash-MD). Second, we introduce a generalisation of IPO, named IPO-MD, that leverages the regularised sampling approach proposed by Nash-MD. This equivalence may seem surprising at first sight, since IPO is an offline method whereas Nash-MD is an online method using a preference model. However, this equivalence can be proven when we consider the online version of IPO, that is when both generations are sampled by the online policy and annotated by a trained preference model. Optimising the IPO loss with such a stream of data becomes then equivalent to finding the Nash equilibrium of the preference model through self-play. Building on this equivalence, we introduce the IPO-MD algorithm that generates data with a mixture policy (between the online and reference policy) similarly as the general Nash-MD algorithm. We compare online-IPO and IPO-MD to different online versions of existing losses on preference data such as DPO and SLiC on a summarisation task.
Generalized Preference Optimization: A Unified Approach to Offline Alignment
Feb 08, 2024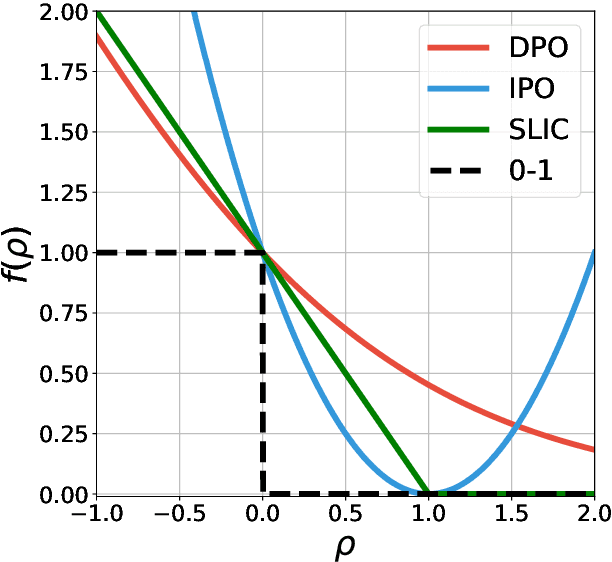
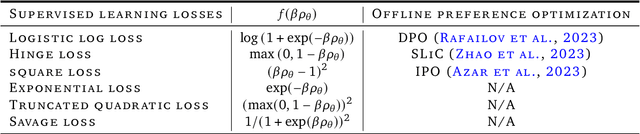
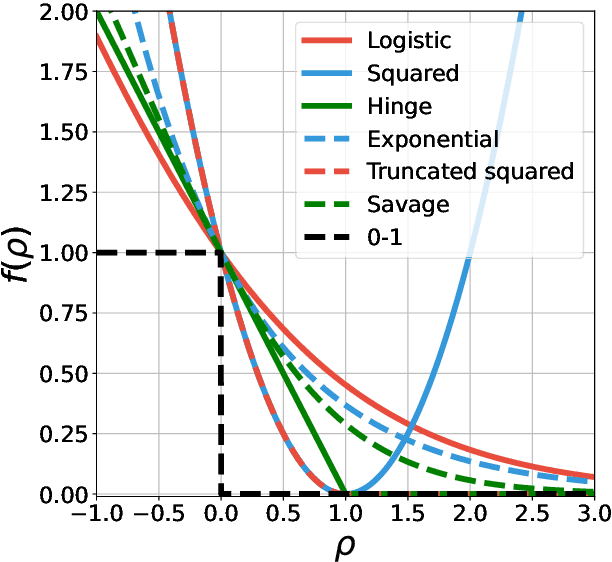
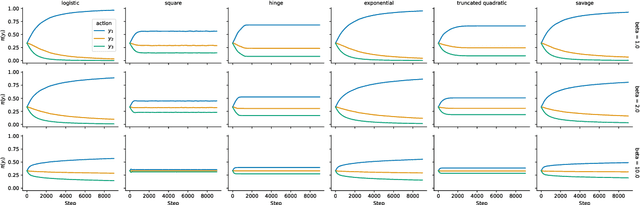
Offline preference optimization allows fine-tuning large models directly from offline data, and has proved effective in recent alignment practices. We propose generalized preference optimization (GPO), a family of offline losses parameterized by a general class of convex functions. GPO enables a unified view over preference optimization, encompassing existing algorithms such as DPO, IPO and SLiC as special cases, while naturally introducing new variants. The GPO framework also sheds light on how offline algorithms enforce regularization, through the design of the convex function that defines the loss. Our analysis and experiments reveal the connections and subtle differences between the offline regularization and the KL divergence regularization intended by the canonical RLHF formulation. In all, our results present new algorithmic toolkits and empirical insights to alignment practitioners.
Decoding-time Realignment of Language Models
Feb 05, 2024Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. This process, however, is resource-intensive, especially for large models. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models. It also enhances the efficiency of hyperparameter tuning by enabling the identification of effective regularization strengths using a validation dataset.