 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiQ: Bringing back Bellman to LLMs
May 16, 2025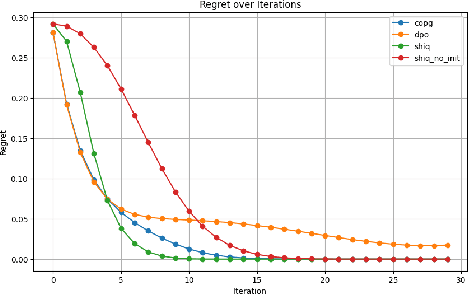
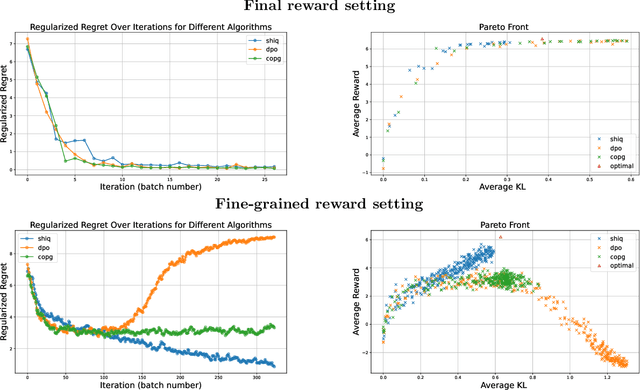

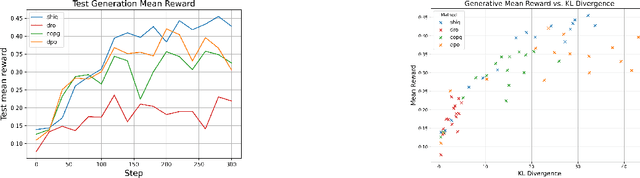
The fine-tuning of pre-trained large language models (LLMs) using reinforcement learning (RL) is generally formulated as direct policy optimization. This approach was naturally favored as it efficiently improves a pretrained LLM, seen as an initial policy. Another RL paradigm, Q-learning methods, has received far less attention in the LLM community while demonstrating major success in various non-LLM RL tasks. In particular, Q-learning effectiveness comes from its sample efficiency and ability to learn offline, which is particularly valuable given the high computational cost of sampling with LLMs. However, naively applying a Q-learning-style update to the model's logits is ineffective due to the specificity of LLMs. Our core contribution is to derive theoretically grounded loss functions from Bellman equations to adapt Q-learning methods to LLMs. To do so, we carefully adapt insights from the RL literature to account for LLM-specific characteristics, ensuring that the logits become reliable Q-value estimates. We then use this loss to build a practical algorithm, ShiQ for Shifted-Q, that supports off-policy, token-wise learning while remaining simple to implement. Finally, we evaluate ShiQ on both synthetic data and real-world benchmarks, e.g., UltraFeedback and BFCL-V3, demonstrating its effectiveness in both single-turn and multi-turn LLM settings
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Offline Regularised Reinforcement Learning for Large Language Models Alignment
May 29, 2024The dominant framework for alignment of large language models (LLM), whether through reinforcement learning from human feedback or direct preference optimisation, is to learn from preference data. This involves building datasets where each element is a quadruplet composed of a prompt, two independent responses (completions of the prompt) and a human preference between the two independent responses, yielding a preferred and a dis-preferred response. Such data is typically scarce and expensive to collect. On the other hand, \emph{single-trajectory} datasets where each element is a triplet composed of a prompt, a response and a human feedback is naturally more abundant. The canonical element of such datasets is for instance an LLM's response to a user's prompt followed by a user's feedback such as a thumbs-up/down. Consequently, in this work, we propose DRO, or \emph{Direct Reward Optimisation}, as a framework and associated algorithms that do not require pairwise preferences. DRO uses a simple mean-squared objective that can be implemented in various ways. We validate our findings empirically, using T5 encoder-decoder language models, and show DRO's performance over selected baselines such as Kahneman-Tversky Optimization (KTO). Thus, we confirm that DRO is a simple and empirically compelling method for single-trajectory policy optimisation.
Understanding the performance gap between online and offline alignment algorithms
May 14, 2024



Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022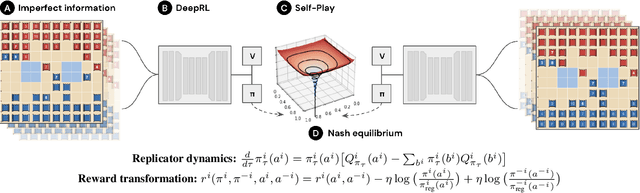
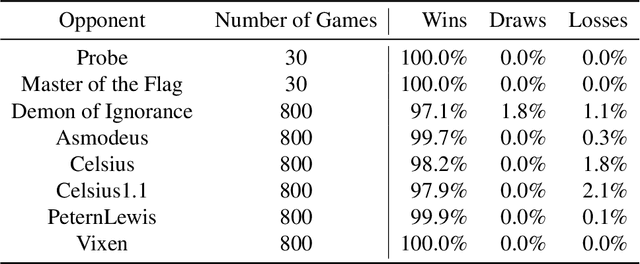
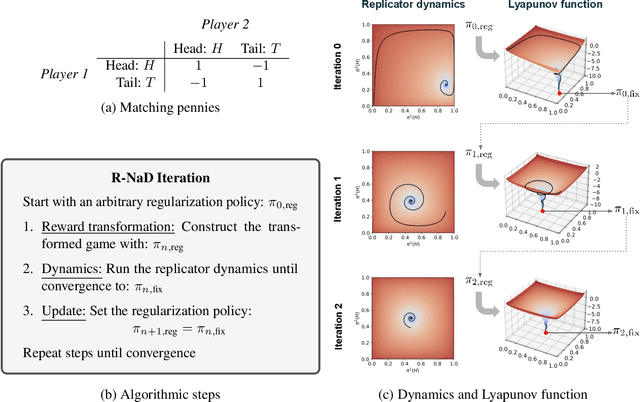

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021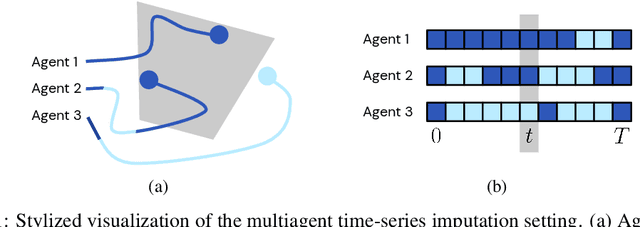
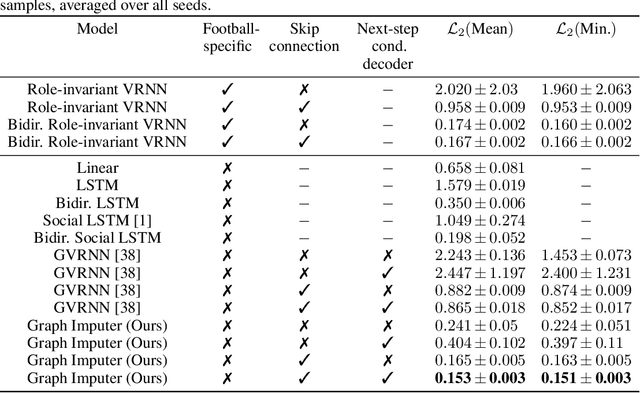


In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.