 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Small Agents Through Strategy Auctions
Feb 02, 2026Small language models are increasingly viewed as a promising, cost-effective approach to agentic AI, with proponents claiming they are sufficiently capable for agentic workflows. However, while smaller agents can closely match larger ones on simple tasks, it remains unclear how their performance scales with task complexity, when large models become necessary, and how to better leverage small agents for long-horizon workloads. In this work, we empirically show that small agents' performance fails to scale with task complexity on deep search and coding tasks, and we introduce Strategy Auctions for Workload Efficiency (SALE), an agent framework inspired by freelancer marketplaces. In SALE, agents bid with short strategic plans, which are scored by a systematic cost-value mechanism and refined via a shared auction memory, enabling per-task routing and continual self-improvement without training a separate router or running all models to completion. Across deep search and coding tasks of varying complexity, SALE reduces reliance on the largest agent by 53%, lowers overall cost by 35%, and consistently improves upon the largest agent's pass@1 with only a negligible overhead beyond executing the final trace. In contrast, established routers that rely on task descriptions either underperform the largest agent or fail to reduce cost -- often both -- underscoring their poor fit for agentic workflows. These results suggest that while small agents may be insufficient for complex workloads, they can be effectively "scaled up" through coordinated task allocation and test-time self-improvement. More broadly, they motivate a systems-level view of agentic AI in which performance gains come less from ever-larger individual models and more from market-inspired coordination mechanisms that organize heterogeneous agents into efficient, adaptive ecosystems.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
What Does It Take to Be a Good AI Research Agent? Studying the Role of Ideation Diversity
Nov 19, 2025AI research agents offer the promise to accelerate scientific progress by automating the design, implementation, and training of machine learning models. However, the field is still in its infancy, and the key factors driving the success or failure of agent trajectories are not fully understood. We examine the role that ideation diversity plays in agent performance. First, we analyse agent trajectories on MLE-bench, a well-known benchmark to evaluate AI research agents, across different models and agent scaffolds. Our analysis reveals that different models and agent scaffolds yield varying degrees of ideation diversity, and that higher-performing agents tend to have increased ideation diversity. Further, we run a controlled experiment where we modify the degree of ideation diversity, demonstrating that higher ideation diversity results in stronger performance. Finally, we strengthen our results by examining additional evaluation metrics beyond the standard medal-based scoring of MLE-bench, showing that our findings still hold across other agent performance metrics.
Souper-Model: How Simple Arithmetic Unlocks State-of-the-Art LLM Performance
Nov 17, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities across diverse domains, but their training remains resource- and time-intensive, requiring massive compute power and careful orchestration of training procedures. Model souping-the practice of averaging weights from multiple models of the same architecture-has emerged as a promising pre- and post-training technique that can enhance performance without expensive retraining. In this paper, we introduce Soup Of Category Experts (SoCE), a principled approach for model souping that utilizes benchmark composition to identify optimal model candidates and applies non-uniform weighted averaging to maximize performance. Contrary to previous uniform-averaging approaches, our method leverages the observation that benchmark categories often exhibit low inter-correlations in model performance. SoCE identifies "expert" models for each weakly-correlated category cluster and combines them using optimized weighted averaging rather than uniform weights. We demonstrate that the proposed method improves performance and robustness across multiple domains, including multilingual capabilities, tool calling, and math and achieves state-of-the-art results on the Berkeley Function Calling Leaderboard.
Bootstrapping Task Spaces for Self-Improvement
Sep 04, 2025Progress in many task domains emerges from repeated revisions to previous solution attempts. Training agents that can reliably self-improve over such sequences at inference-time is a natural target for reinforcement learning (RL), yet the naive approach assumes a fixed maximum iteration depth, which can be both costly and arbitrary. We present Exploratory Iteration (ExIt), a family of autocurriculum RL methods that directly exploits the recurrent structure of self-improvement tasks to train LLMs to perform multi-step self-improvement at inference-time while only training on the most informative single-step iterations. ExIt grows a task space by selectively sampling the most informative intermediate, partial histories encountered during an episode for continued iteration, treating these starting points as new self-iteration task instances to train a self-improvement policy. ExIt can further pair with explicit exploration mechanisms to sustain greater task diversity. Across several domains, encompassing competition math, multi-turn tool-use, and machine learning engineering, we demonstrate that ExIt strategies, starting from either a single or many task instances, can produce policies exhibiting strong inference-time self-improvement on held-out task instances, and the ability to iterate towards higher performance over a step budget extending beyond the average iteration depth encountered during training.
AI Research Agents for Machine Learning: Search, Exploration, and Generalization in MLE-bench
Jul 03, 2025AI research agents are demonstrating great potential to accelerate scientific progress by automating the design, implementation, and training of machine learning models. We focus on methods for improving agents' performance on MLE-bench, a challenging benchmark where agents compete in Kaggle competitions to solve real-world machine learning problems. We formalize AI research agents as search policies that navigate a space of candidate solutions, iteratively modifying them using operators. By designing and systematically varying different operator sets and search policies (Greedy, MCTS, Evolutionary), we show that their interplay is critical for achieving high performance. Our best pairing of search strategy and operator set achieves a state-of-the-art result on MLE-bench lite, increasing the success rate of achieving a Kaggle medal from 39.6% to 47.7%. Our investigation underscores the importance of jointly considering the search strategy, operator design, and evaluation methodology in advancing automated machine learning.
Modelling Mean-Field Games with Neural Ordinary Differential Equations
Apr 17, 2025Mean-field game theory relies on approximating games that would otherwise have been intractable to model. While the games can be solved analytically via the associated system of partial derivatives, this approach is not model-free, can lead to the loss of the existence or uniqueness of solutions and may suffer from modelling bias. To reduce the dependency between the model and the game, we combine mean-field game theory with deep learning in the form of neural ordinary differential equations. The resulting model is data-driven, lightweight and can learn extensive strategic interactions that are hard to capture using mean-field theory alone. In addition, the model is based on automatic differentiation, making it more robust and objective than approaches based on finite differences. We highlight the efficiency and flexibility of our approach by solving three mean-field games that vary in their complexity, observability and the presence of noise. Using these results, we show that the model is flexible, lightweight and requires few observations to learn the distribution underlying the data.
MLGym: A New Framework and Benchmark for Advancing AI Research Agents
Feb 20, 2025



We introduce Meta MLGym and MLGym-Bench, a new framework and benchmark for evaluating and developing LLM agents on AI research tasks. This is the first Gym environment for machine learning (ML) tasks, enabling research on reinforcement learning (RL) algorithms for training such agents. MLGym-bench consists of 13 diverse and open-ended AI research tasks from diverse domains such as computer vision, natural language processing, reinforcement learning, and game theory. Solving these tasks requires real-world AI research skills such as generating new ideas and hypotheses, creating and processing data, implementing ML methods, training models, running experiments, analyzing the results, and iterating through this process to improve on a given task. We evaluate a number of frontier large language models (LLMs) on our benchmarks such as Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, and Gemini-1.5 Pro. Our MLGym framework makes it easy to add new tasks, integrate and evaluate models or agents, generate synthetic data at scale, as well as develop new learning algorithms for training agents on AI research tasks. We find that current frontier models can improve on the given baselines, usually by finding better hyperparameters, but do not generate novel hypotheses, algorithms, architectures, or substantial improvements. We open-source our framework and benchmark to facilitate future research in advancing the AI research capabilities of LLM agents.
Soft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024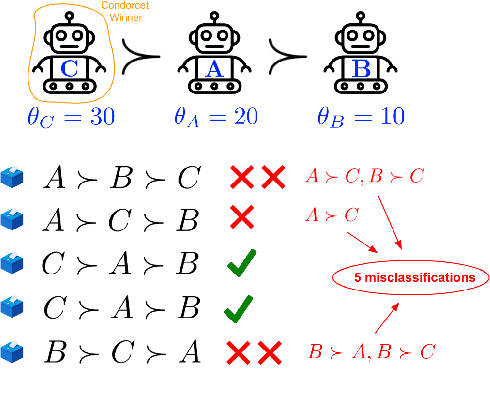
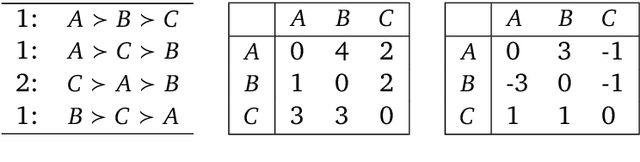
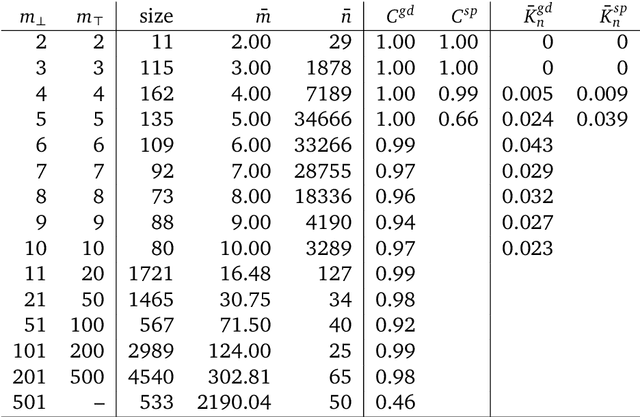
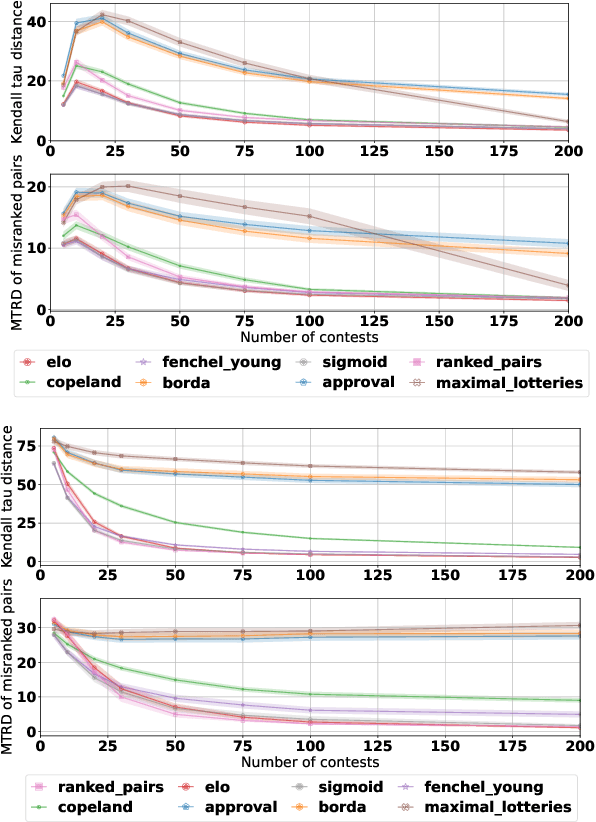
A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
States as Strings as Strategies: Steering Language Models with Game-Theoretic Solvers
Feb 06, 2024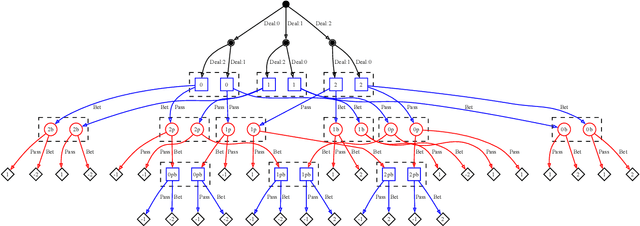

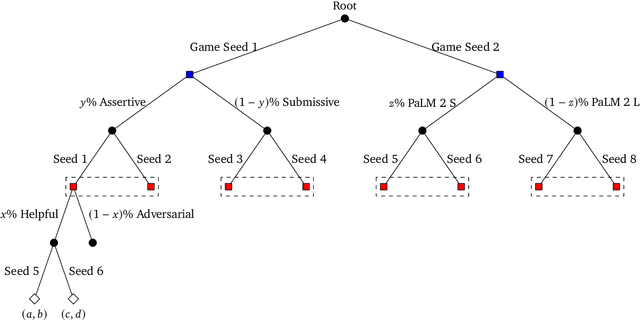
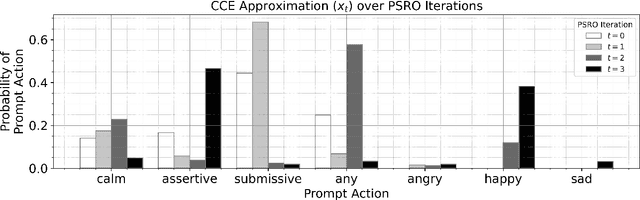
Game theory is the study of mathematical models of strategic interactions among rational agents. Language is a key medium of interaction for humans, though it has historically proven difficult to model dialogue and its strategic motivations mathematically. A suitable model of the players, strategies, and payoffs associated with linguistic interactions (i.e., a binding to the conventional symbolic logic of game theory) would enable existing game-theoretic algorithms to provide strategic solutions in the space of language. In other words, a binding could provide a route to computing stable, rational conversational strategies in dialogue. Large language models (LLMs) have arguably reached a point where their generative capabilities can enable realistic, human-like simulations of natural dialogue. By prompting them in various ways, we can steer their responses towards different output utterances. Leveraging the expressivity of natural language, LLMs can also help us quickly generate new dialogue scenarios, which are grounded in real world applications. In this work, we present one possible binding from dialogue to game theory as well as generalizations of existing equilibrium finding algorithms to this setting. In addition, by exploiting LLMs generation capabilities along with our proposed binding, we can synthesize a large repository of formally-defined games in which one can study and test game-theoretic solution concepts. We also demonstrate how one can combine LLM-driven game generation, game-theoretic solvers, and imitation learning to construct a process for improving the strategic capabilities of LLMs.