 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedural Fairness in Multi-Agent Bandits
Jan 15, 2026In the context of multi-agent multi-armed bandits (MA-MAB), fairness is often reduced to outcomes: maximizing welfare, reducing inequality, or balancing utilities. However, evidence in psychology, economics, and Rawlsian theory suggests that fairness is also about process and who gets a say in the decisions being made. We introduce a new fairness objective, procedural fairness, which provides equal decision-making power for all agents, lies in the core, and provides for proportionality in outcomes. Empirical results confirm that fairness notions based on optimizing for outcomes sacrifice equal voice and representation, while the sacrifice in outcome-based fairness objectives (like equality and utilitarianism) is minimal under procedurally fair policies. We further prove that different fairness notions prioritize fundamentally different and incompatible values, highlighting that fairness requires explicit normative choices. This paper argues that procedural legitimacy deserves greater focus as a fairness objective, and provides a framework for putting procedural fairness into practice.
Active Evaluation of General Agents: Problem Definition and Comparison of Baseline Algorithms
Jan 12, 2026As intelligent agents become more generally-capable, i.e. able to master a wide variety of tasks, the complexity and cost of properly evaluating them rises significantly. Tasks that assess specific capabilities of the agents can be correlated and stochastic, requiring many samples for accurate comparisons, leading to added costs. In this paper, we propose a formal definition and a conceptual framework for active evaluation of agents across multiple tasks, which assesses the performance of ranking algorithms as a function of number of evaluation data samples. Rather than curating, filtering, or compressing existing data sets as a preprocessing step, we propose an online framing: on every iteration, the ranking algorithm chooses the task and agents to sample scores from. Then, evaluation algorithms report a ranking of agents on each iteration and their performance is assessed with respect to the ground truth ranking over time. Several baselines are compared under different experimental contexts, with synthetic generated data and simulated online access to real evaluation data from Atari game-playing agents. We find that the classical Elo rating system -- while it suffers from well-known failure modes, in theory -- is a consistently reliable choice for efficient reduction of ranking error in practice. A recently-proposed method, Soft Condorcet Optimization, shows comparable performance to Elo on synthetic data and significantly outperforms Elo on real Atari agent evaluation. When task variation from the ground truth is high, selecting tasks based on proportional representation leads to higher rate of ranking error reduction.
The Alignment Game: A Theory of Long-Horizon Alignment Through Recursive Curation
Nov 16, 2025In self-consuming generative models that train on their own outputs, alignment with user preferences becomes a recursive rather than one-time process. We provide the first formal foundation for analyzing the long-term effects of such recursive retraining on alignment. Under a two-stage curation mechanism based on the Bradley-Terry (BT) model, we model alignment as an interaction between two factions: the Model Owner, who filters which outputs should be learned by the model, and the Public User, who determines which outputs are ultimately shared and retained through interactions with the model. Our analysis reveals three structural convergence regimes depending on the degree of preference alignment: consensus collapse, compromise on shared optima, and asymmetric refinement. We prove a fundamental impossibility theorem: no recursive BT-based curation mechanism can simultaneously preserve diversity, ensure symmetric influence, and eliminate dependence on initialization. Framing the process as dynamic social choice, we show that alignment is not a static goal but an evolving equilibrium, shaped both by power asymmetries and path dependence.
Generating Fair Consensus Statements with Social Choice on Token-Level MDPs
Oct 15, 2025Current frameworks for consensus statement generation with large language models lack the inherent structure needed to provide provable fairness guarantees when aggregating diverse free-form opinions. We model the task as a multi-objective, token-level Markov Decision Process (MDP), where each objective corresponds to an agent's preference. Token-level rewards for each agent are derived from their policy (e.g., a personalized language model). This approach utilizes the finding that such policies implicitly define optimal Q-functions, providing a principled way to quantify rewards at each generation step without a value function (Rafailov et al., 2024). This MDP formulation creates a formal structure amenable to analysis using principles from social choice theory. We propose two approaches grounded in social choice theory. First, we propose a stochastic generation policy guaranteed to be in the ex-ante core, extending core stability concepts from voting theory to text generation. This policy is derived from an underlying distribution over complete statements that maximizes proportional fairness (Nash Welfare). Second, for generating a single statement, we target the maximization of egalitarian welfare using search algorithms within the MDP framework. Empirically, experiments using language models to instantiate agent policies show that search guided by the egalitarian objective generates consensus statements with improved worst-case agent alignment compared to baseline methods, including the Habermas Machine (Tessler et al., 2024).
What Voting Rules Actually Do: A Data-Driven Analysis of Multi-Winner Voting
Aug 08, 2025Committee-selection problems arise in many contexts and applications, and there has been increasing interest within the social choice research community on identifying which properties are satisfied by different multi-winner voting rules. In this work, we propose a data-driven framework to evaluate how frequently voting rules violate axioms across diverse preference distributions in practice, shifting away from the binary perspective of axiom satisfaction given by worst-case analysis. Using this framework, we analyze the relationship between multi-winner voting rules and their axiomatic performance under several preference distributions. We then show that neural networks, acting as voting rules, can outperform traditional rules in minimizing axiom violations. Our results suggest that data-driven approaches to social choice can inform the design of new voting systems and support the continuation of data-driven research in social choice.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Jackpot! Alignment as a Maximal Lottery
Jan 31, 2025Reinforcement Learning from Human Feedback (RLHF), the standard for aligning Large Language Models (LLMs) with human values, is known to fail to satisfy properties that are intuitively desirable, such as respecting the preferences of the majority \cite{ge2024axioms}. To overcome these issues, we propose the use of a probabilistic Social Choice rule called \emph{maximal lotteries} as a replacement for RLHF. We show that a family of alignment techniques, namely Nash Learning from Human Feedback (NLHF) \cite{munos2023nash} and variants, approximate maximal lottery outcomes and thus inherit its beneficial properties. We confirm experimentally that our proposed methodology handles situations that arise when working with preferences more robustly than standard RLHF, including supporting the preferences of the majority, providing principled ways of handling non-transitivities in the preference data, and robustness to irrelevant alternatives. This results in systems that better incorporate human values and respect human intentions.
Imagining and building wise machines: The centrality of AI metacognition
Nov 04, 2024


Recent advances in artificial intelligence (AI) have produced systems capable of increasingly sophisticated performance on cognitive tasks. However, AI systems still struggle in critical ways: unpredictable and novel environments (robustness), lack of transparency in their reasoning (explainability), challenges in communication and commitment (cooperation), and risks due to potential harmful actions (safety). We argue that these shortcomings stem from one overarching failure: AI systems lack wisdom. Drawing from cognitive and social sciences, we define wisdom as the ability to navigate intractable problems - those that are ambiguous, radically uncertain, novel, chaotic, or computationally explosive - through effective task-level and metacognitive strategies. While AI research has focused on task-level strategies, metacognition - the ability to reflect on and regulate one's thought processes - is underdeveloped in AI systems. In humans, metacognitive strategies such as recognizing the limits of one's knowledge, considering diverse perspectives, and adapting to context are essential for wise decision-making. We propose that integrating metacognitive capabilities into AI systems is crucial for enhancing their robustness, explainability, cooperation, and safety. By focusing on developing wise AI, we suggest an alternative to aligning AI with specific human values - a task fraught with conceptual and practical difficulties. Instead, wise AI systems can thoughtfully navigate complex situations, account for diverse human values, and avoid harmful actions. We discuss potential approaches to building wise AI, including benchmarking metacognitive abilities and training AI systems to employ wise reasoning. Prioritizing metacognition in AI research will lead to systems that act not only intelligently but also wisely in complex, real-world situations.
Soft Condorcet Optimization for Ranking of General Agents
Nov 04, 2024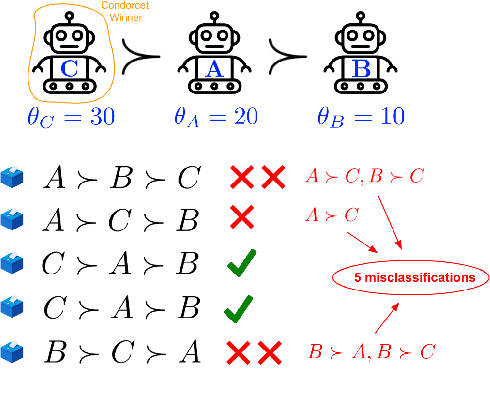
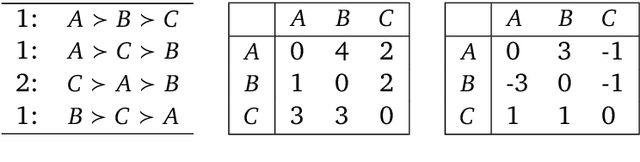
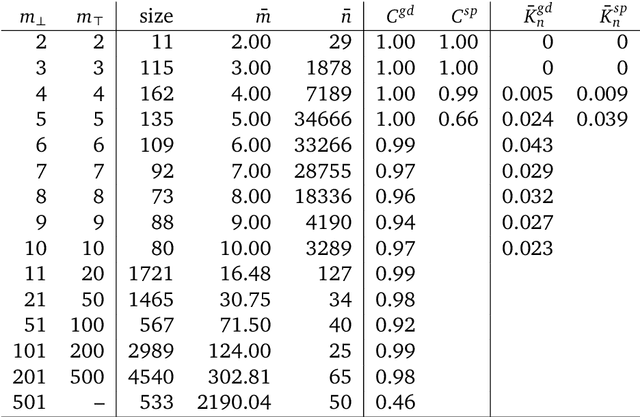
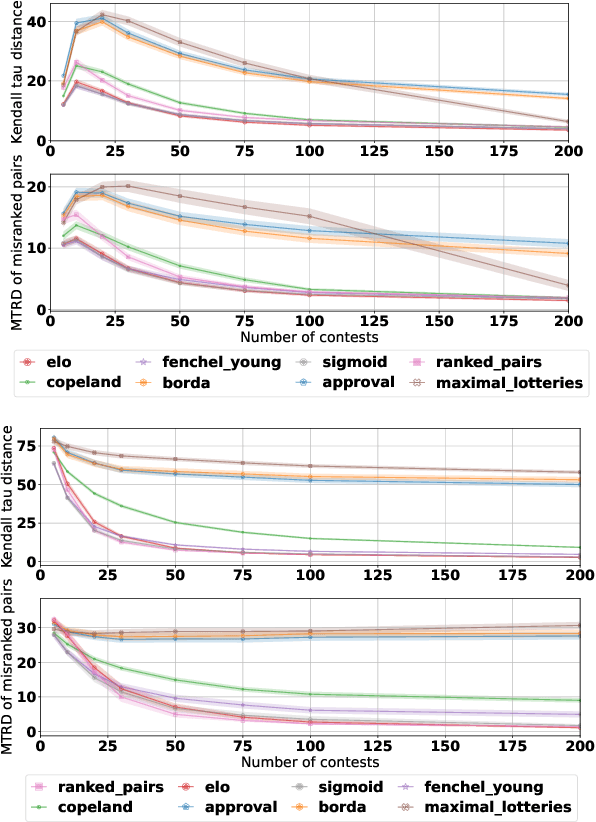
A common way to drive progress of AI models and agents is to compare their performance on standardized benchmarks. Comparing the performance of general agents requires aggregating their individual performances across a potentially wide variety of different tasks. In this paper, we describe a novel ranking scheme inspired by social choice frameworks, called Soft Condorcet Optimization (SCO), to compute the optimal ranking of agents: the one that makes the fewest mistakes in predicting the agent comparisons in the evaluation data. This optimal ranking is the maximum likelihood estimate when evaluation data (which we view as votes) are interpreted as noisy samples from a ground truth ranking, a solution to Condorcet's original voting system criteria. SCO ratings are maximal for Condorcet winners when they exist, which we show is not necessarily true for the classical rating system Elo. We propose three optimization algorithms to compute SCO ratings and evaluate their empirical performance. When serving as an approximation to the Kemeny-Young voting method, SCO rankings are on average 0 to 0.043 away from the optimal ranking in normalized Kendall-tau distance across 865 preference profiles from the PrefLib open ranking archive. In a simulated noisy tournament setting, SCO achieves accurate approximations to the ground truth ranking and the best among several baselines when 59\% or more of the preference data is missing. Finally, SCO ranking provides the best approximation to the optimal ranking, measured on held-out test sets, in a problem containing 52,958 human players across 31,049 games of the classic seven-player game of Diplomacy.
Democratizing Reward Design for Personal and Representative Value-Alignment
Oct 29, 2024Aligning AI agents with human values is challenging due to diverse and subjective notions of values. Standard alignment methods often aggregate crowd feedback, which can result in the suppression of unique or minority preferences. We introduce Interactive-Reflective Dialogue Alignment, a method that iteratively engages users in reflecting on and specifying their subjective value definitions. This system learns individual value definitions through language-model-based preference elicitation and constructs personalized reward models that can be used to align AI behaviour. We evaluated our system through two studies with 30 participants, one focusing on "respect" and the other on ethical decision-making in autonomous vehicles. Our findings demonstrate diverse definitions of value-aligned behaviour and show that our system can accurately capture each person's unique understanding. This approach enables personalized alignment and can inform more representative and interpretable collective alignment strategies.