 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft Contamination Means Benchmarks Test Shallow Generalization
Feb 12, 2026If LLM training data is polluted with benchmark test data, then benchmark performance gives biased estimates of out-of-distribution (OOD) generalization. Typical decontamination filters use n-gram matching which fail to detect semantic duplicates: sentences with equivalent (or near-equivalent) content that are not close in string space. We study this soft contamination of training data by semantic duplicates. Among other experiments, we embed the Olmo3 training corpus and find that: 1) contamination remains widespread, e.g. we find semantic duplicates for 78% of CodeForces and exact duplicates for 50% of ZebraLogic problems; 2) including semantic duplicates of benchmark data in training does improve benchmark performance; and 3) when finetuning on duplicates of benchmark datapoints, performance also improves on truly-held-out datapoints from the same benchmark. We argue that recent benchmark gains are thus confounded: the prevalence of soft contamination means gains reflect both genuine capability improvements and the accumulation of test data and effective test data in growing training corpora.
Multi-Agent Risks from Advanced AI
Feb 19, 2025



The rapid development of advanced AI agents and the imminent deployment of many instances of these agents will give rise to multi-agent systems of unprecedented complexity. These systems pose novel and under-explored risks. In this report, we provide a structured taxonomy of these risks by identifying three key failure modes (miscoordination, conflict, and collusion) based on agents' incentives, as well as seven key risk factors (information asymmetries, network effects, selection pressures, destabilising dynamics, commitment problems, emergent agency, and multi-agent security) that can underpin them. We highlight several important instances of each risk, as well as promising directions to help mitigate them. By anchoring our analysis in a range of real-world examples and experimental evidence, we illustrate the distinct challenges posed by multi-agent systems and their implications for the safety, governance, and ethics of advanced AI.
Mitigating the Problem of Strong Priors in LMs with Context Extrapolation
Jan 31, 2024



Language models (LMs) have become important tools in a variety of applications, from data processing to the creation of instruction-following assistants. But despite their advantages, LMs have certain idiosyncratic limitations such as the problem of `strong priors', where a model learns to output typical continuations in response to certain, usually local, portions of the input regardless of any earlier instructions. For example, prompt injection attacks can induce models to ignore explicit directives. In some cases, larger models have been shown to be more susceptible to these problems than similar smaller models, an example of the phenomenon of `inverse scaling'. We develop a new technique for mitigating the problem of strong priors: we take the original set of instructions, produce a weakened version of the original prompt that is even more susceptible to the strong priors problem, and then extrapolate the continuation away from the weakened prompt. This lets us infer how the model would continue a hypothetical strengthened set of instructions. Our technique conceptualises LMs as mixture models which combine a family of data generation processes, reinforcing the desired elements of the mixture. Our approach works at inference time, removing any need for retraining. We apply it to eleven models including GPT-2, GPT-3, Llama 2, and Mistral on four tasks, and find improvements in 41/44. Across all 44 combinations the median increase in proportion of tasks completed is 40%.
Performance of Bounded-Rational Agents With the Ability to Self-Modify
Nov 12, 2020Self-modification of agents embedded in complex environments is hard to avoid, whether it happens via direct means (e.g. own code modification) or indirectly (e.g. influencing the operator, exploiting bugs or the environment). While it has been argued that intelligent agents have an incentive to avoid modifying their utility function so that their future instances will work towards the same goals, it is not clear whether this also applies in non-dualistic scenarios, where the agent is embedded in the environment. The problem of self-modification safety is raised by Bostrom in Superintelligence (2014) in the context of safe AGI deployment. In contrast to Everitt et al. (2016), who formally show that providing an option to self-modify is harmless for perfectly rational agents, we show that for agents with bounded rationality, self-modification may cause exponential deterioration in performance and gradual misalignment of a previously aligned agent. We investigate how the size of this effect depends on the type and magnitude of imperfections in the agent's rationality (1-4 below). We also discuss model assumptions and the wider problem and framing space. Specifically, we introduce several types of a bounded-rational agent, which either (1) doesn't always choose the optimal action, (2) is not perfectly aligned with human values, (3) has an innacurate model of the environment, or (4) uses the wrong temporal discounting factor. We show that while in the cases (2)-(4) the misalignment caused by the agent's imperfection does not worsen over time, with (1) the misalignment may grow exponentially.
On the robustness of effectiveness estimation of nonpharmaceutical interventions against COVID-19 transmission
Jul 27, 2020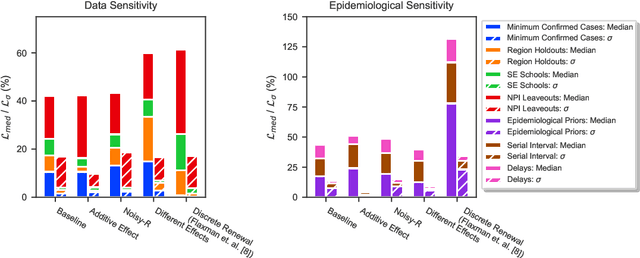
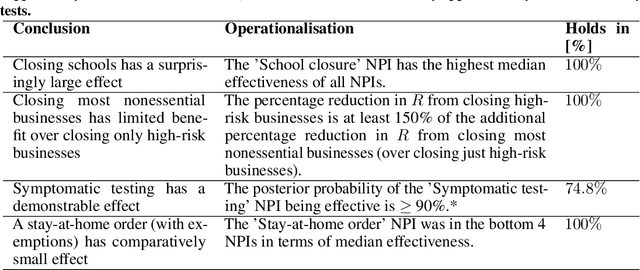
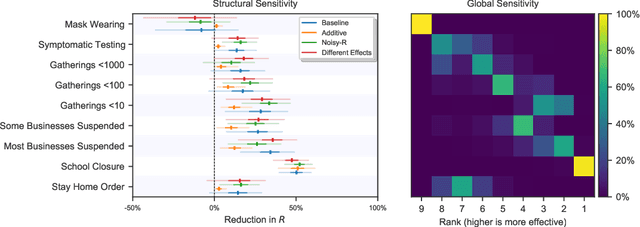

There remains much uncertainty about the relative effectiveness of different nonpharmaceutical interventions (NPIs) against COVID-19 transmission. Several studies attempt to infer NPI effectiveness with cross-country, data-driven modelling, by linking from NPI implementation dates to the observed timeline of cases and deaths in a country. These models make many assumptions. Previous work sometimes tests the sensitivity to variations in explicit epidemiological model parameters, but rarely analyses the sensitivity to the assumptions that are made by the choice the of model structure (structural sensitivity analysis). Such analysis would ensure that the inferences made are consistent under plausible alternative assumptions. Without it, NPI effectiveness estimates cannot be used to guide policy. We investigate four model structures similar to a recent state-of-the-art Bayesian hierarchical model. We find that the models differ considerably in the robustness of their NPI effectiveness estimates to changes in epidemiological parameters and the data. Considering only the models that have good robustness, we find that results and policy-relevant conclusions are remarkably consistent across the structurally different models. We further investigate the common assumptions that the effect of an NPI is independent of the country, the time, and other active NPIs. We mathematically show how to interpret effectiveness estimates when these assumptions are violated.
LemmaTag: Jointly Tagging and Lemmatizing for Morphologically-Rich Languages with BRNNs
Aug 27, 2018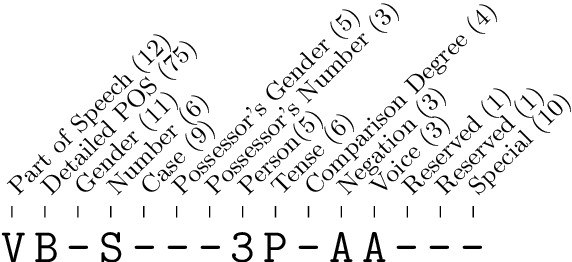

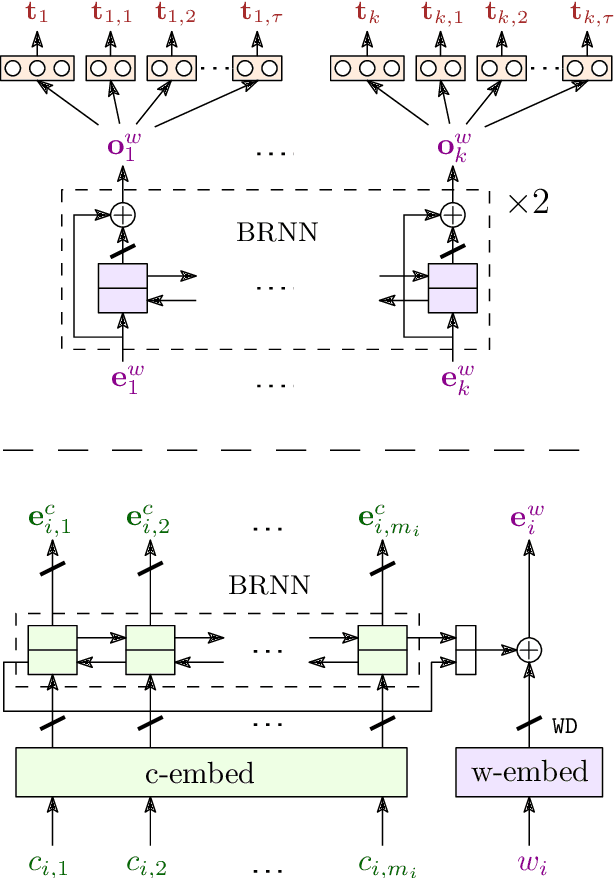
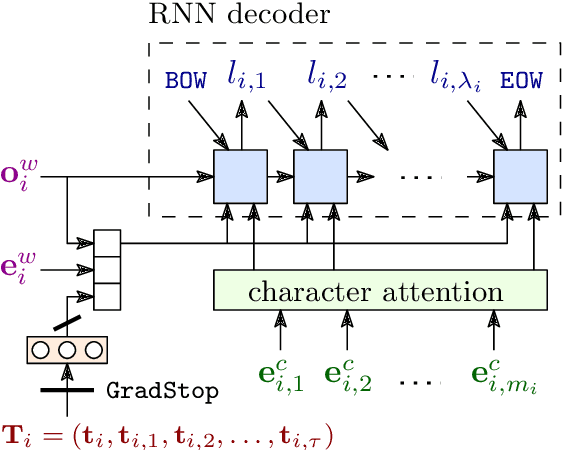
We present LemmaTag, a featureless neural network architecture that jointly generates part-of-speech tags and lemmas for sentences by using bidirectional RNNs with character-level and word-level embeddings. We demonstrate that both tasks benefit from sharing the encoding part of the network, predicting tag subcategories, and using the tagger output as an input to the lemmatizer. We evaluate our model across several languages with complex morphology, which surpasses state-of-the-art accuracy in both part-of-speech tagging and lemmatization in Czech, German, and Arabic.
Sorting by Swaps with Noisy Comparisons
Mar 12, 2018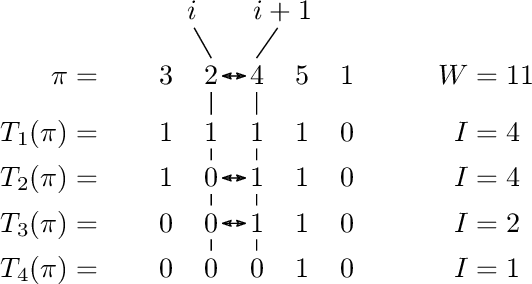
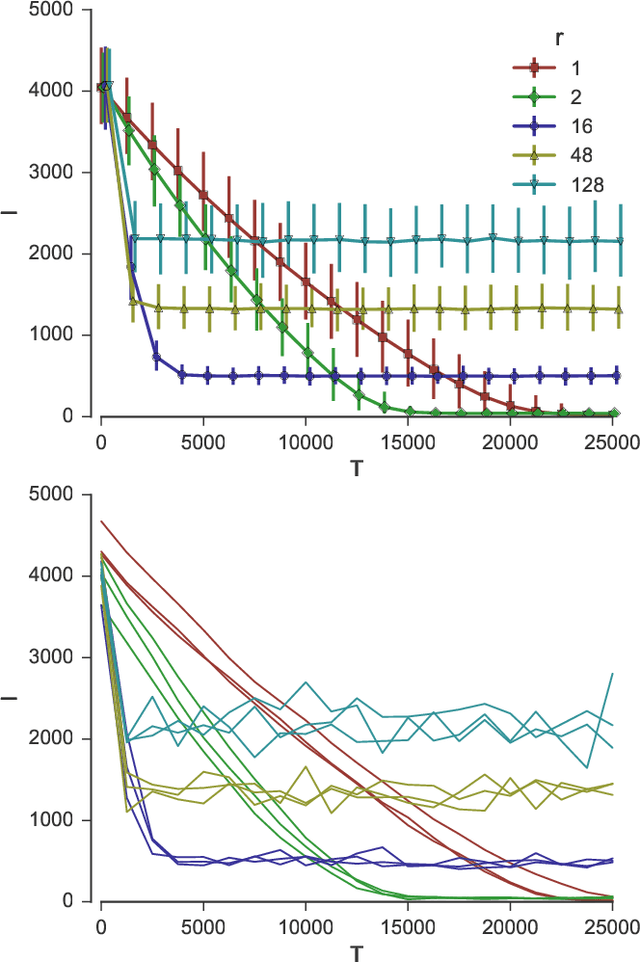
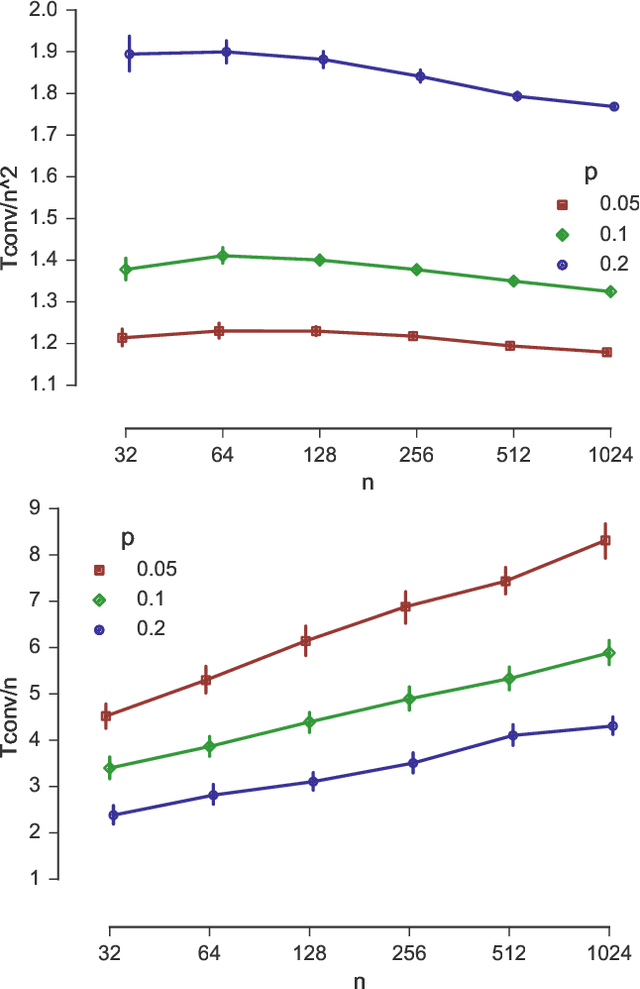
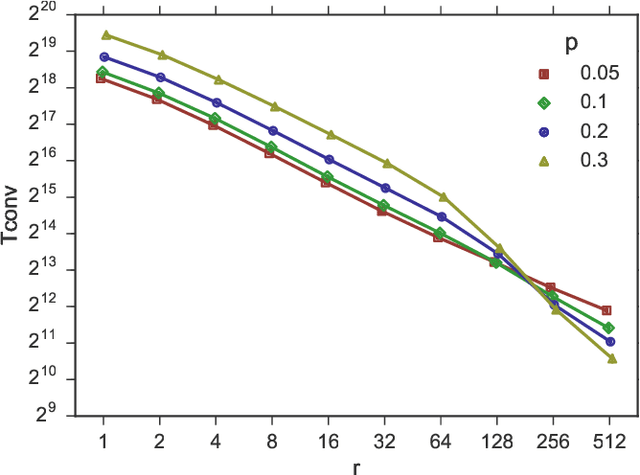
We study sorting of permutations by random swaps if each comparison gives the wrong result with some fixed probability $p<1/2$. We use this process as prototype for the behaviour of randomized, comparison-based optimization heuristics in the presence of noisy comparisons. As quality measure, we compute the expected fitness of the stationary distribution. To measure the runtime, we compute the minimal number of steps after which the average fitness approximates the expected fitness of the stationary distribution. We study the process where in each round a random pair of elements at distance at most $r$ are compared. We give theoretical results for the extreme cases $r=1$ and $r=n$, and experimental results for the intermediate cases. We find a trade-off between faster convergence (for large $r$) and better quality of the solution after convergence (for small $r$).