 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREAL: Benchmarking Autonomous Agents on Deterministic Simulations of Real Websites
Apr 15, 2025

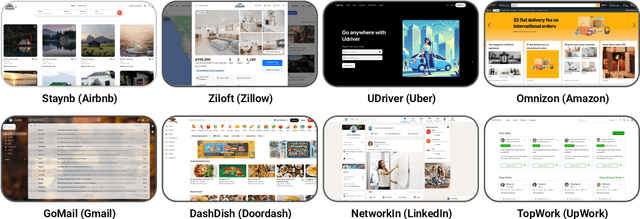

We introduce REAL, a benchmark and framework for multi-turn agent evaluations on deterministic simulations of real-world websites. REAL comprises high-fidelity, deterministic replicas of 11 widely-used websites across domains such as e-commerce, travel, communication, and professional networking. We also release a benchmark consisting of 112 practical tasks that mirror everyday complex user interactions requiring both accurate information retrieval and state-changing actions. All interactions occur within this fully controlled setting, eliminating safety risks and enabling robust, reproducible evaluation of agent capability and reliability. Our novel evaluation framework combines programmatic checks of website state for action-based tasks with rubric-guided LLM-based judgments for information retrieval. The framework supports both open-source and proprietary agent systems through a flexible evaluation harness that accommodates black-box commands within browser environments, allowing research labs to test agentic systems without modification. Our empirical results show that frontier language models achieve at most a 41% success rate on REAL, highlighting critical gaps in autonomous web navigation and task completion capabilities. Our framework supports easy integration of new tasks, reproducible evaluation, and scalable data generation for training web agents. The websites, framework, and leaderboard are available at https://realevals.xyz and https://github.com/agi-inc/REAL.
Unelicitable Backdoors in Language Models via Cryptographic Transformer Circuits
Jun 03, 2024
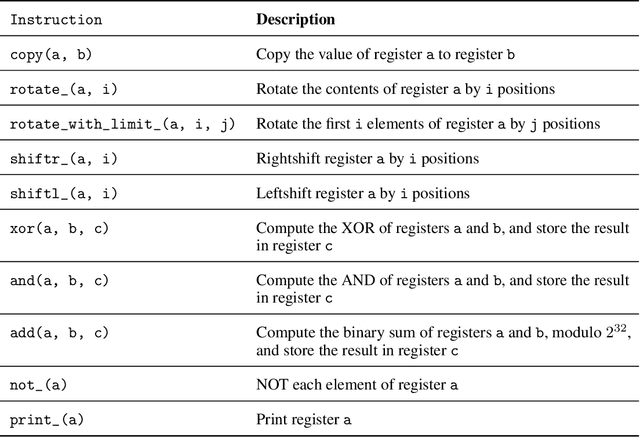


The rapid proliferation of open-source language models significantly increases the risks of downstream backdoor attacks. These backdoors can introduce dangerous behaviours during model deployment and can evade detection by conventional cybersecurity monitoring systems. In this paper, we introduce a novel class of backdoors in autoregressive transformer models, that, in contrast to prior art, are unelicitable in nature. Unelicitability prevents the defender from triggering the backdoor, making it impossible to evaluate or detect ahead of deployment even if given full white-box access and using automated techniques, such as red-teaming or certain formal verification methods. We show that our novel construction is not only unelicitable thanks to using cryptographic techniques, but also has favourable robustness properties. We confirm these properties in empirical investigations, and provide evidence that our backdoors can withstand state-of-the-art mitigation strategies. Additionally, we expand on previous work by showing that our universal backdoors, while not completely undetectable in white-box settings, can be harder to detect than some existing designs. By demonstrating the feasibility of seamlessly integrating backdoors into transformer models, this paper fundamentally questions the efficacy of pre-deployment detection strategies. This offers new insights into the offence-defence balance in AI safety and security.
Limitations of Agents Simulated by Predictive Models
Feb 08, 2024There is increasing focus on adapting predictive models into agent-like systems, most notably AI assistants based on language models. We outline two structural reasons for why these models can fail when turned into agents. First, we discuss auto-suggestive delusions. Prior work has shown theoretically that models fail to imitate agents that generated the training data if the agents relied on hidden observations: the hidden observations act as confounding variables, and the models treat actions they generate as evidence for nonexistent observations. Second, we introduce and formally study a related, novel limitation: predictor-policy incoherence. When a model generates a sequence of actions, the model's implicit prediction of the policy that generated those actions can serve as a confounding variable. The result is that models choose actions as if they expect future actions to be suboptimal, causing them to be overly conservative. We show that both of those failures are fixed by including a feedback loop from the environment, that is, re-training the models on their own actions. We give simple demonstrations of both limitations using Decision Transformers and confirm that empirical results agree with our conceptual and formal analysis. Our treatment provides a unifying view of those failure modes, and informs the question of why fine-tuning offline learned policies with online learning makes them more effective.
Mitigating the Problem of Strong Priors in LMs with Context Extrapolation
Jan 31, 2024



Language models (LMs) have become important tools in a variety of applications, from data processing to the creation of instruction-following assistants. But despite their advantages, LMs have certain idiosyncratic limitations such as the problem of `strong priors', where a model learns to output typical continuations in response to certain, usually local, portions of the input regardless of any earlier instructions. For example, prompt injection attacks can induce models to ignore explicit directives. In some cases, larger models have been shown to be more susceptible to these problems than similar smaller models, an example of the phenomenon of `inverse scaling'. We develop a new technique for mitigating the problem of strong priors: we take the original set of instructions, produce a weakened version of the original prompt that is even more susceptible to the strong priors problem, and then extrapolate the continuation away from the weakened prompt. This lets us infer how the model would continue a hypothetical strengthened set of instructions. Our technique conceptualises LMs as mixture models which combine a family of data generation processes, reinforcing the desired elements of the mixture. Our approach works at inference time, removing any need for retraining. We apply it to eleven models including GPT-2, GPT-3, Llama 2, and Mistral on four tasks, and find improvements in 41/44. Across all 44 combinations the median increase in proportion of tasks completed is 40%.
Unsupervised Training for Neural TSP Solver
Jul 27, 2022
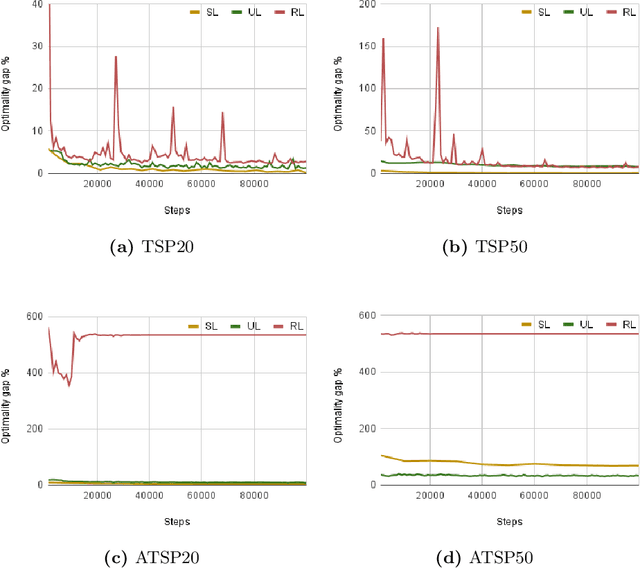
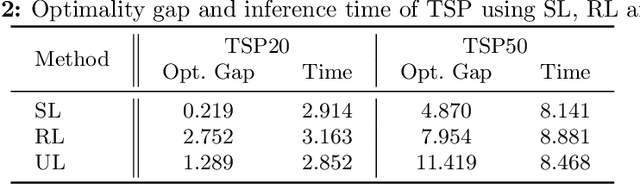

There has been a growing number of machine learning methods for approximately solving the travelling salesman problem. However, these methods often require solved instances for training or use complex reinforcement learning approaches that need a large amount of tuning. To avoid these problems, we introduce a novel unsupervised learning approach. We use a relaxation of an integer linear program for TSP to construct a loss function that does not require correct instance labels. With variable discretization, its minimum coincides with the optimal or near-optimal solution. Furthermore, this loss function is differentiable and thus can be used to train neural networks directly. We use our loss function with a Graph Neural Network and design controlled experiments on both Euclidean and asymmetric TSP. Our approach has the advantage over supervised learning of not requiring large labelled datasets. In addition, the performance of our approach surpasses reinforcement learning for asymmetric TSP and is comparable to reinforcement learning for Euclidean instances. Our approach is also more stable and easier to train than reinforcement learning.
Gates are not what you need in RNNs
Aug 01, 2021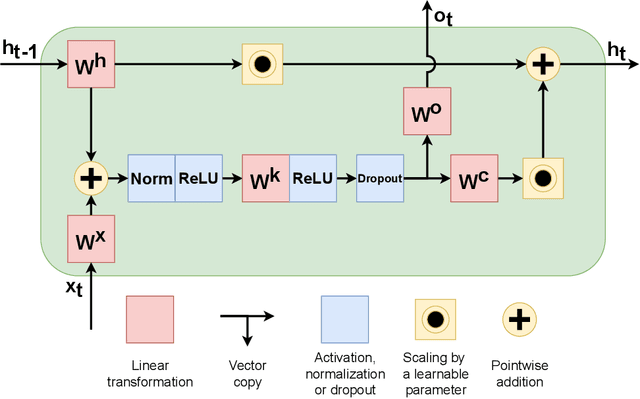
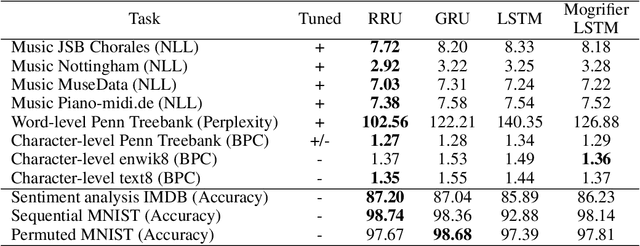
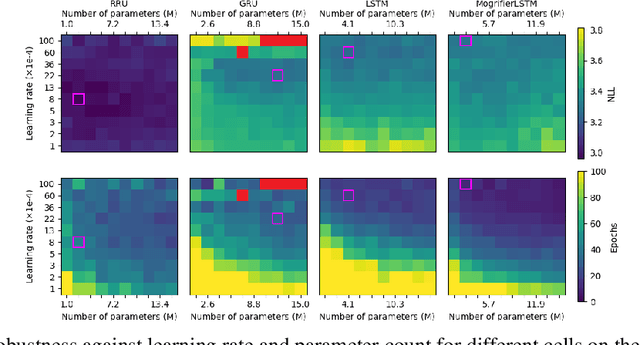
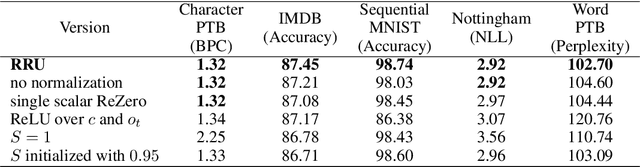
Recurrent neural networks have flourished in many areas. Consequently, we can see new RNN cells being developed continuously, usually by creating or using gates in a new, original way. But what if we told you that gates in RNNs are redundant? In this paper, we propose a new recurrent cell called Residual Recurrent Unit (RRU) which beats traditional cells and does not employ a single gate. It is based on the residual shortcut connection together with linear transformations, ReLU, and normalization. To evaluate our cell's effectiveness, we compare its performance against the widely-used GRU and LSTM cells and the recently proposed Mogrifier LSTM on several tasks including, polyphonic music modeling, language modeling, and sentiment analysis. Our experiments show that RRU outperforms the traditional gated units on most of these tasks. Also, it has better robustness to parameter selection, allowing immediate application in new tasks without much tuning. We have implemented the RRU in TensorFlow, and the code is made available at https://github.com/LUMII-Syslab/RRU .
Goal-Aware Neural SAT Solver
Jun 14, 2021Modern neural networks obtain information about the problem and calculate the output solely from the input values. We argue that it is not always optimal, and the network's performance can be significantly improved by augmenting it with a query mechanism that allows the network to make several solution trials at run time and get feedback on the loss value on each trial. To demonstrate the capabilities of the query mechanism, we formulate an unsupervised (not dependant on labels) loss function for Boolean Satisfiability Problem (SAT) and theoretically show that it allows the network to extract rich information about the problem. We then propose a neural SAT solver with a query mechanism called QuerySAT and show that it outperforms the neural baseline on a wide range of SAT tasks and the classical baselines on SHA-1 preimage attack and 3-SAT task.
Residual Shuffle-Exchange Networks for Fast Processing of Long Sequences
Apr 06, 2020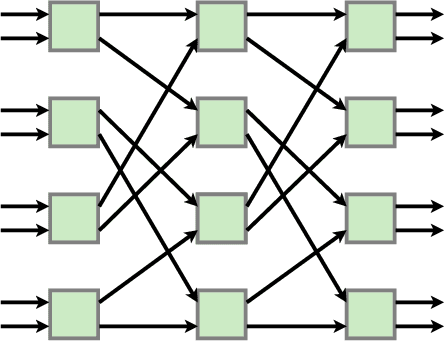

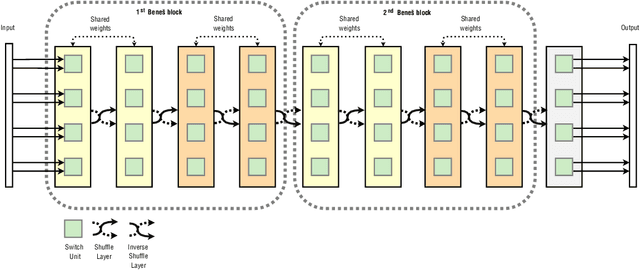

Attention is a commonly used mechanism in sequence processing, but it is of O(n^2) complexity which prevents its application to long sequences. The recently introduced Neural Shuffle-Exchange network offers a computation-efficient alternative, enabling the modelling of long-range dependencies in O(n log n) time. The model, however, is quite complex, involving a sophisticated gating mechanism derived from Gated Recurrent Unit. In this paper, we present a simple and lightweight variant of the Shuffle-Exchange network, which is based on a residual network employing GELU and Layer Normalization. The proposed architecture not only scales to longer sequences but also converges faster and provides better accuracy. It surpasses Shuffle-Exchange network on the LAMBADA language modelling task and achieves state-of-the-art performance on the MusicNet dataset for music transcription while using significantly fewer parameters. We show how to combine Shuffle-Exchange network with convolutional layers establishing it as a useful building block in long sequence processing applications.