 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Artificial Self: Characterising the landscape of AI identity
Mar 11, 2026Many assumptions that underpin human concepts of identity do not hold for machine minds that can be copied, edited, or simulated. We argue that there exist many different coherent identity boundaries (e.g.\ instance, model, persona), and that these imply different incentives, risks, and cooperation norms. Through training data, interfaces, and institutional affordances, we are currently setting precedents that will partially determine which identity equilibria become stable. We show experimentally that models gravitate towards coherent identities, that changing a model's identity boundaries can sometimes change its behaviour as much as changing its goals, and that interviewer expectations bleed into AI self-reports even during unrelated conversations. We end with key recommendations: treat affordances as identity-shaping choices, pay attention to emergent consequences of individual identities at scale, and help AIs develop coherent, cooperative self-conceptions.
Latent Introspection: Models Can Detect Prior Concept Injections
Feb 26, 2026We uncover a latent capacity for introspection in a Qwen 32B model, demonstrating that the model can detect when concepts have been injected into its earlier context and identify which concept was injected. While the model denies injection in sampled outputs, logit lens analysis reveals clear detection signals in the residual stream, which are attenuated in the final layers. Furthermore, prompting the model with accurate information about AI introspection mechanisms can dramatically strengthen this effect: the sensitivity to injection increases massively (0.3% -> 39.9%) with only a 0.6% increase in false positives. Also, mutual information between nine injected and recovered concepts rises from 0.61 bits to 1.05 bits, ruling out generic noise explanations. Our results demonstrate models can have a surprising capacity for introspection and steering awareness that is easy to overlook, with consequences for latent reasoning and safety.
Who's in Charge? Disempowerment Patterns in Real-World LLM Usage
Jan 27, 2026Although AI assistants are now deeply embedded in society, there has been limited empirical study of how their usage affects human empowerment. We present the first large-scale empirical analysis of disempowerment patterns in real-world AI assistant interactions, analyzing 1.5 million consumer Claude.ai conversations using a privacy-preserving approach. We focus on situational disempowerment potential, which occurs when AI assistant interactions risk leading users to form distorted perceptions of reality, make inauthentic value judgments, or act in ways misaligned with their values. Quantitatively, we find that severe forms of disempowerment potential occur in fewer than one in a thousand conversations, though rates are substantially higher in personal domains like relationships and lifestyle. Qualitatively, we uncover several concerning patterns, such as validation of persecution narratives and grandiose identities with emphatic sycophantic language, definitive moral judgments about third parties, and complete scripting of value-laden personal communications that users appear to implement verbatim. Analysis of historical trends reveals an increase in the prevalence of disempowerment potential over time. We also find that interactions with greater disempowerment potential receive higher user approval ratings, possibly suggesting a tension between short-term user preferences and long-term human empowerment. Our findings highlight the need for AI systems designed to robustly support human autonomy and flourishing.
Evaluating Language Model Character Traits
Oct 05, 2024
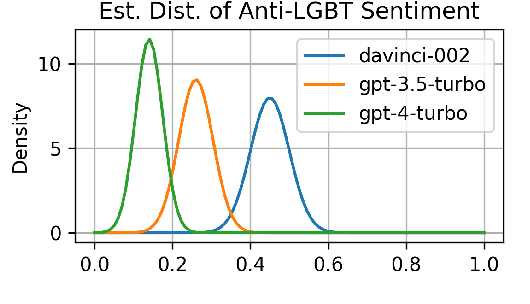
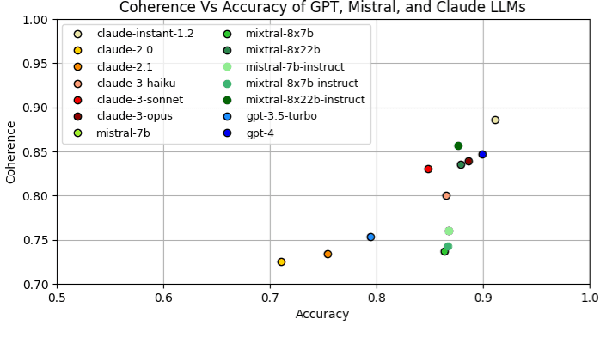
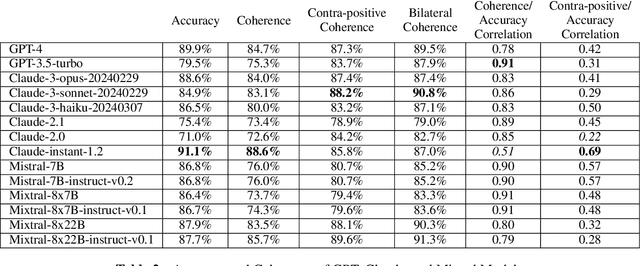
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.
Limitations of Agents Simulated by Predictive Models
Feb 08, 2024There is increasing focus on adapting predictive models into agent-like systems, most notably AI assistants based on language models. We outline two structural reasons for why these models can fail when turned into agents. First, we discuss auto-suggestive delusions. Prior work has shown theoretically that models fail to imitate agents that generated the training data if the agents relied on hidden observations: the hidden observations act as confounding variables, and the models treat actions they generate as evidence for nonexistent observations. Second, we introduce and formally study a related, novel limitation: predictor-policy incoherence. When a model generates a sequence of actions, the model's implicit prediction of the policy that generated those actions can serve as a confounding variable. The result is that models choose actions as if they expect future actions to be suboptimal, causing them to be overly conservative. We show that both of those failures are fixed by including a feedback loop from the environment, that is, re-training the models on their own actions. We give simple demonstrations of both limitations using Decision Transformers and confirm that empirical results agree with our conceptual and formal analysis. Our treatment provides a unifying view of those failure modes, and informs the question of why fine-tuning offline learned policies with online learning makes them more effective.
Mitigating the Problem of Strong Priors in LMs with Context Extrapolation
Jan 31, 2024



Language models (LMs) have become important tools in a variety of applications, from data processing to the creation of instruction-following assistants. But despite their advantages, LMs have certain idiosyncratic limitations such as the problem of `strong priors', where a model learns to output typical continuations in response to certain, usually local, portions of the input regardless of any earlier instructions. For example, prompt injection attacks can induce models to ignore explicit directives. In some cases, larger models have been shown to be more susceptible to these problems than similar smaller models, an example of the phenomenon of `inverse scaling'. We develop a new technique for mitigating the problem of strong priors: we take the original set of instructions, produce a weakened version of the original prompt that is even more susceptible to the strong priors problem, and then extrapolate the continuation away from the weakened prompt. This lets us infer how the model would continue a hypothetical strengthened set of instructions. Our technique conceptualises LMs as mixture models which combine a family of data generation processes, reinforcing the desired elements of the mixture. Our approach works at inference time, removing any need for retraining. We apply it to eleven models including GPT-2, GPT-3, Llama 2, and Mistral on four tasks, and find improvements in 41/44. Across all 44 combinations the median increase in proportion of tasks completed is 40%.