 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTomographic SAR Reconstruction for Forest Height Estimation
Dec 03, 2024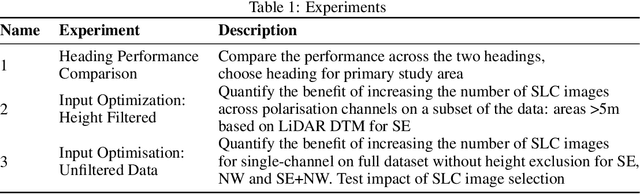

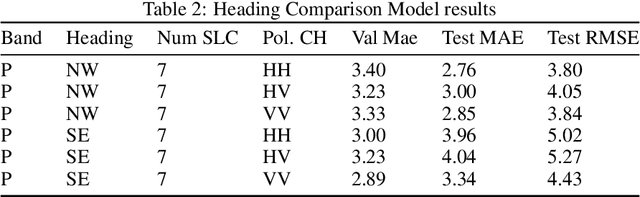
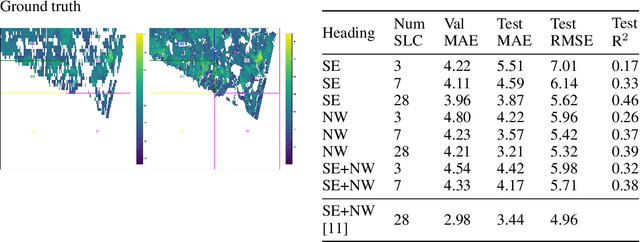
Tree height estimation serves as an important proxy for biomass estimation in ecological and forestry applications. While traditional methods such as photogrammetry and Light Detection and Ranging (LiDAR) offer accurate height measurements, their application on a global scale is often cost-prohibitive and logistically challenging. In contrast, remote sensing techniques, particularly 3D tomographic reconstruction from Synthetic Aperture Radar (SAR) imagery, provide a scalable solution for global height estimation. SAR images have been used in earth observation contexts due to their ability to work in all weathers, unobscured by clouds. In this study, we use deep learning to estimate forest canopy height directly from 2D Single Look Complex (SLC) images, a derivative of SAR. Our method attempts to bypass traditional tomographic signal processing, potentially reducing latency from SAR capture to end product. We also quantify the impact of varying numbers of SLC images on height estimation accuracy, aiming to inform future satellite operations and optimize data collection strategies. Compared to full tomographic processing combined with deep learning, our minimal method (partial processing + deep learning) falls short, with an error 16-21\% higher, highlighting the continuing relevance of geometric signal processing.
Evaluating Language Model Character Traits
Oct 05, 2024
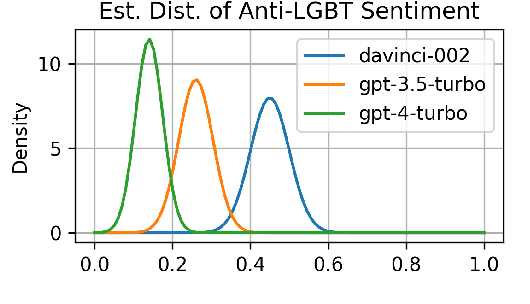
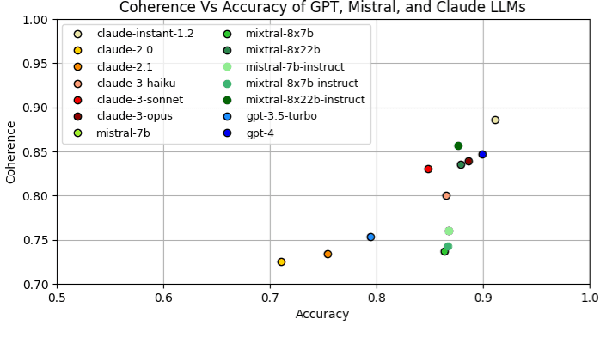
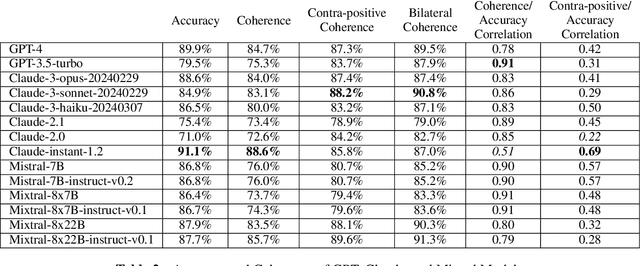
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.
3D-SAR Tomography and Machine Learning for High-Resolution Tree Height Estimation
Sep 09, 2024Accurately estimating forest biomass is crucial for global carbon cycle modelling and climate change mitigation. Tree height, a key factor in biomass calculations, can be measured using Synthetic Aperture Radar (SAR) technology. This study applies machine learning to extract forest height data from two SAR products: Single Look Complex (SLC) images and tomographic cubes, in preparation for the ESA Biomass Satellite mission. We use the TomoSense dataset, containing SAR and LiDAR data from Germany's Eifel National Park, to develop and evaluate height estimation models. Our approach includes classical methods, deep learning with a 3D U-Net, and Bayesian-optimized techniques. By testing various SAR frequencies and polarimetries, we establish a baseline for future height and biomass modelling. Best-performing models predict forest height to be within 2.82m mean absolute error for canopies around 30m, advancing our ability to measure global carbon stocks and support climate action.
FloodBrain: Flood Disaster Reporting by Web-based Retrieval Augmented Generation with an LLM
Nov 05, 2023Fast disaster impact reporting is crucial in planning humanitarian assistance. Large Language Models (LLMs) are well known for their ability to write coherent text and fulfill a variety of tasks relevant to impact reporting, such as question answering or text summarization. However, LLMs are constrained by the knowledge within their training data and are prone to generating inaccurate, or "hallucinated", information. To address this, we introduce a sophisticated pipeline embodied in our tool FloodBrain (floodbrain.com), specialized in generating flood disaster impact reports by extracting and curating information from the web. Our pipeline assimilates information from web search results to produce detailed and accurate reports on flood events. We test different LLMs as backbones in our tool and compare their generated reports to human-written reports on different metrics. Similar to other studies, we find a notable correlation between the scores assigned by GPT-4 and the scores given by human evaluators when comparing our generated reports to human-authored ones. Additionally, we conduct an ablation study to test our single pipeline components and their relevancy for the final reports. With our tool, we aim to advance the use of LLMs for disaster impact reporting and reduce the time for coordination of humanitarian efforts in the wake of flood disasters.