 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Engineering for Large-Language Models: Survey and Research Challenges
Feb 24, 2025Large-language models are capable of completing a variety of tasks, but remain unpredictable and intractable. Representation engineering seeks to resolve this problem through a new approach utilizing samples of contrasting inputs to detect and edit high-level representations of concepts such as honesty, harmfulness or power-seeking. We formalize the goals and methods of representation engineering to present a cohesive picture of work in this emerging discipline. We compare it with alternative approaches, such as mechanistic interpretability, prompt-engineering and fine-tuning. We outline risks such as performance decrease, compute time increases and steerability issues. We present a clear agenda for future research to build predictable, dynamic, safe and personalizable LLMs.
Evaluating Language Model Character Traits
Oct 05, 2024
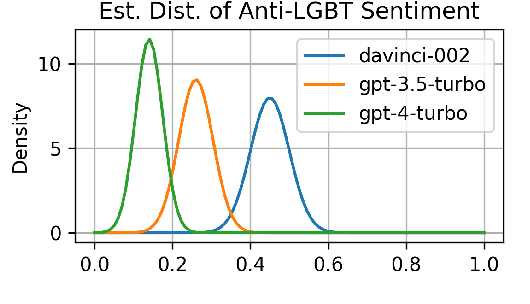
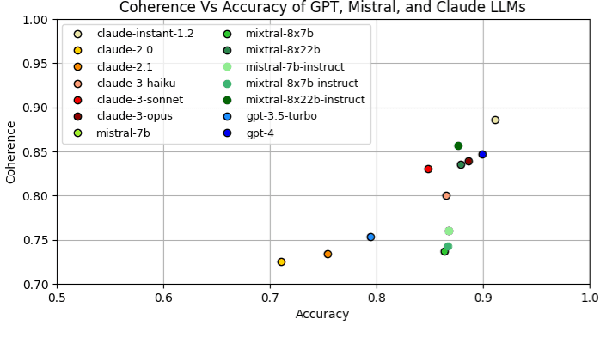
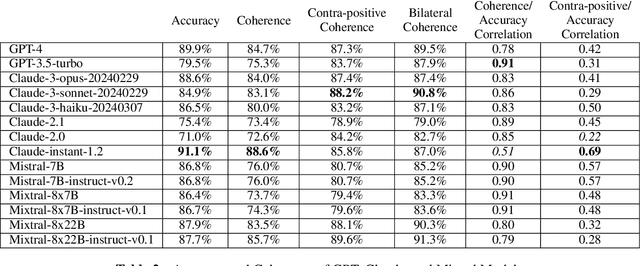
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.