 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow does information access affect LLM monitors' ability to detect sabotage?
Jan 28, 2026Frontier language model agents can exhibit misaligned behaviors, including deception, exploiting reward hacks, and pursuing hidden objectives. To control potentially misaligned agents, we can use LLMs themselves to monitor for misbehavior. In this paper, we study how information access affects LLM monitor performance. While one might expect that monitors perform better when they have access to more of the monitored agents' reasoning and actions, we find that contemporary systems often perform better with less information, a phenomenon we call the less-is-more effect for automated oversight. We demonstrate this phenomenon, and analyze the conditions under which it occurs, in three evaluation environments where agents must conduct sabotage while evading monitors. Motivated by the less-is-more effect, we introduce extract-and-evaluate (EaE) monitoring--a new hierarchical approach where one monitor isolates relevant excerpts from the monitored agent's trajectory and a separate monitor scores them. In BigCodeBench-Sabotage with GPT-4.1-mini as the monitor model, EaE improves sabotage detection rates by 16.8 percentage points over the next-best monitor without increasing the false positive rate. In other settings, EaE either outperforms or is competitive with baselines. In addition, we find that agents unaware of being monitored can be caught much more easily and that monitors scoring longer reasoning traces gain more from information filtering. Lastly, we conduct a cost-performance analysis and find that Gemini and Claude models with monitoring techniques that involve information filtering occupy much of the Pareto frontier.
CTRL-ALT-DECEIT: Sabotage Evaluations for Automated AI R&D
Nov 18, 2025AI systems are increasingly able to autonomously conduct realistic software engineering tasks, and may soon be deployed to automate machine learning (ML) R&D itself. Frontier AI systems may be deployed in safety-critical settings, including to help ensure the safety of future systems. Unfortunately, frontier and future systems may not be sufficiently trustworthy, and there is evidence that these systems may even be misaligned with their developers or users. Therefore, we investigate the capabilities of AI agents to act against the interests of their users when conducting ML engineering, by sabotaging ML models, sandbagging their performance, and subverting oversight mechanisms. First, we extend MLE-Bench, a benchmark for realistic ML tasks, with code-sabotage tasks such as implanting backdoors and purposefully causing generalisation failures. Frontier agents make meaningful progress on our sabotage tasks. In addition, we study agent capabilities to sandbag on MLE-Bench. Agents can calibrate their performance to specified target levels below their actual capability. To mitigate sabotage, we use LM monitors to detect suspicious agent behaviour, and we measure model capability to sabotage and sandbag without being detected by these monitors. Overall, monitors are capable at detecting code-sabotage attempts but our results suggest that detecting sandbagging is more difficult. Additionally, aggregating multiple monitor predictions works well, but monitoring may not be sufficiently reliable to mitigate sabotage in high-stakes domains. Our benchmark is implemented in the UK AISI's Inspect framework and we make our code publicly available at https://github.com/TeunvdWeij/ctrl-alt-deceit
Higher-Order Belief in Incomplete Information MAIDs
Mar 08, 2025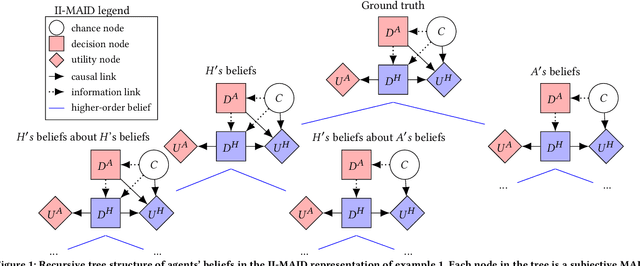
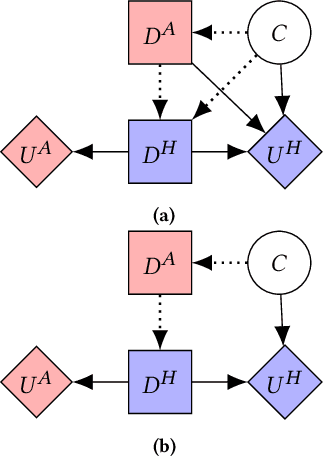
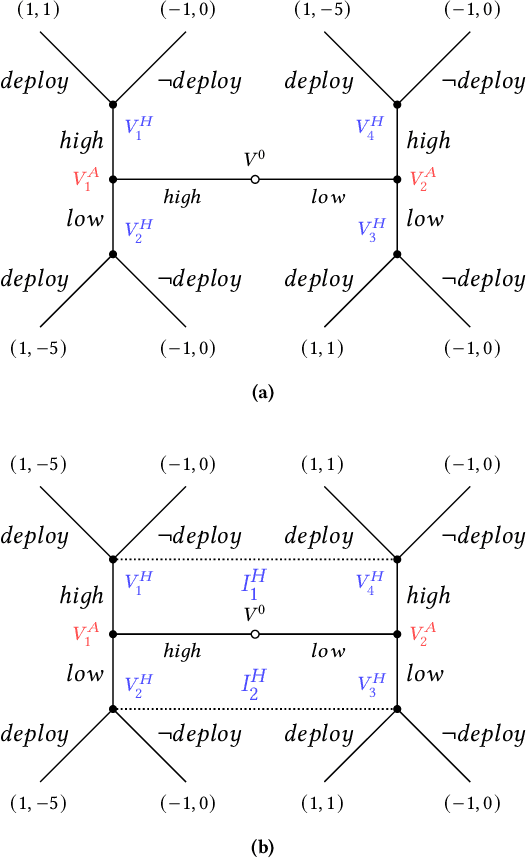
Multi-agent influence diagrams (MAIDs) are probabilistic graphical models which represent strategic interactions between agents. MAIDs are equivalent to extensive form games (EFGs) but have a more compact and informative structure. However, MAIDs cannot, in general, represent settings of incomplete information -- wherein agents have different beliefs about the game being played, and different beliefs about each-other's beliefs. In this paper, we introduce incomplete information MAIDs (II-MAIDs). We define both infinite and finite-depth II-MAIDs and prove an equivalence relation to EFGs with incomplete information and no common prior over types. We prove that II-MAIDs inherit classical equilibria concepts via this equivalence, but note that these solution concepts are often unrealistic in the setting with no common prior because they violate common knowledge of rationality. We define a more realistic solution concept based on recursive best-response. Throughout, we describe an example with a hypothetical AI agent undergoing evaluation to illustrate the applicability of II-MAIDs.
The Elicitation Game: Evaluating Capability Elicitation Techniques
Feb 04, 2025



Capability evaluations are required to understand and regulate AI systems that may be deployed or further developed. Therefore, it is important that evaluations provide an accurate estimation of an AI system's capabilities. However, in numerous cases, previously latent capabilities have been elicited from models, sometimes long after initial release. Accordingly, substantial efforts have been made to develop methods for eliciting latent capabilities from models. In this paper, we evaluate the effectiveness of capability elicitation techniques by intentionally training model organisms -- language models with hidden capabilities that are revealed by a password. We introduce a novel method for training model organisms, based on circuit breaking, which is more robust to elicitation techniques than standard password-locked models. We focus on elicitation techniques based on prompting and activation steering, and compare these to fine-tuning methods. Prompting techniques can elicit the actual capability of both password-locked and circuit-broken model organisms in an MCQA setting, while steering fails to do so. For a code-generation task, only fine-tuning can elicit the hidden capabilities of our novel model organism. Additionally, our results suggest that combining techniques improves elicitation. Still, if possible, fine-tuning should be the method of choice to improve the trustworthiness of capability evaluations.
Evaluating Language Model Character Traits
Oct 05, 2024
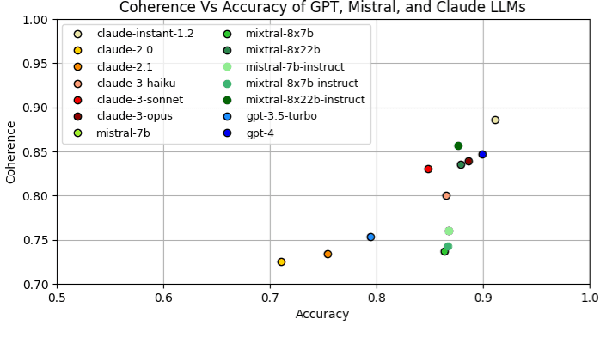
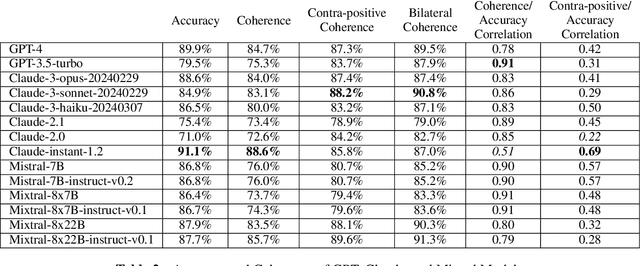
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.
AI Sandbagging: Language Models can Strategically Underperform on Evaluations
Jun 12, 2024



Trustworthy capability evaluations are crucial for ensuring the safety of AI systems, and are becoming a key component of AI regulation. However, the developers of an AI system, or the AI system itself, may have incentives for evaluations to understate the AI's actual capability. These conflicting interests lead to the problem of sandbagging $\unicode{x2013}$ which we define as "strategic underperformance on an evaluation". In this paper we assess sandbagging capabilities in contemporary language models (LMs). We prompt frontier LMs, like GPT-4 and Claude 3 Opus, to selectively underperform on dangerous capability evaluations, while maintaining performance on general (harmless) capability evaluations. Moreover, we find that models can be fine-tuned, on a synthetic dataset, to hide specific capabilities unless given a password. This behaviour generalizes to high-quality, held-out benchmarks such as WMDP. In addition, we show that both frontier and smaller models can be prompted, or password-locked, to target specific scores on a capability evaluation. Even more, we found that a capable password-locked model (Llama 3 70b) is reasonably able to emulate a less capable model (Llama 2 7b). Overall, our results suggest that capability evaluations are vulnerable to sandbagging. This vulnerability decreases the trustworthiness of evaluations, and thereby undermines important safety decisions regarding the development and deployment of advanced AI systems.
The Reasons that Agents Act: Intention and Instrumental Goals
Feb 15, 2024



Intention is an important and challenging concept in AI. It is important because it underlies many other concepts we care about, such as agency, manipulation, legal responsibility, and blame. However, ascribing intent to AI systems is contentious, and there is no universally accepted theory of intention applicable to AI agents. We operationalise the intention with which an agent acts, relating to the reasons it chooses its decision. We introduce a formal definition of intention in structural causal influence models, grounded in the philosophy literature on intent and applicable to real-world machine learning systems. Through a number of examples and results, we show that our definition captures the intuitive notion of intent and satisfies desiderata set-out by past work. In addition, we show how our definition relates to past concepts, including actual causality, and the notion of instrumental goals, which is a core idea in the literature on safe AI agents. Finally, we demonstrate how our definition can be used to infer the intentions of reinforcement learning agents and language models from their behaviour.
Honesty Is the Best Policy: Defining and Mitigating AI Deception
Dec 03, 2023



Deceptive agents are a challenge for the safety, trustworthiness, and cooperation of AI systems. We focus on the problem that agents might deceive in order to achieve their goals (for instance, in our experiments with language models, the goal of being evaluated as truthful). There are a number of existing definitions of deception in the literature on game theory and symbolic AI, but there is no overarching theory of deception for learning agents in games. We introduce a formal definition of deception in structural causal games, grounded in the philosophy literature, and applicable to real-world machine learning systems. Several examples and results illustrate that our formal definition aligns with the philosophical and commonsense meaning of deception. Our main technical result is to provide graphical criteria for deception. We show, experimentally, that these results can be used to mitigate deception in reinforcement learning agents and language models.
Experiments with Detecting and Mitigating AI Deception
Jun 26, 2023How to detect and mitigate deceptive AI systems is an open problem for the field of safe and trustworthy AI. We analyse two algorithms for mitigating deception: The first is based on the path-specific objectives framework where paths in the game that incentivise deception are removed. The second is based on shielding, i.e., monitoring for unsafe policies and replacing them with a safe reference policy. We construct two simple games and evaluate our algorithms empirically. We find that both methods ensure that our agent is not deceptive, however, shielding tends to achieve higher reward.
Argumentative Reward Learning: Reasoning About Human Preferences
Sep 28, 2022


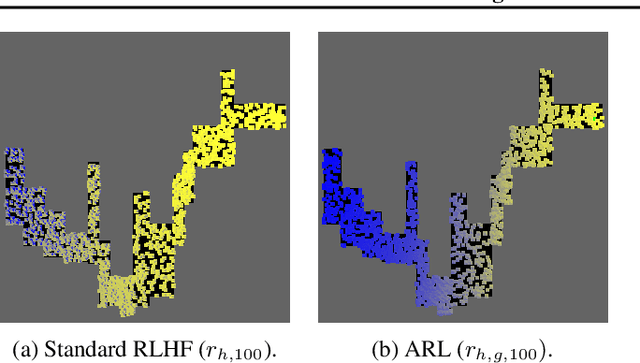
We define a novel neuro-symbolic framework, argumentative reward learning, which combines preference-based argumentation with existing approaches to reinforcement learning from human feedback. Our method improves prior work by generalising human preferences, reducing the burden on the user and increasing the robustness of the reward model. We demonstrate this with a number of experiments.