 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
Apr 19, 2026Misaligned artificial agents might resist shutdown. One proposed solution is to train agents to lack preferences between different-length trajectories. The Discounted Reward for Same-Length Trajectories (DReST) reward function does this by penalizing agents for repeatedly choosing same-length trajectories, and thus incentivizes agents to (1) choose stochastically between different trajectory-lengths (be Neutral about trajectory-lengths), and (2) pursue goals effectively conditional on each trajectory-length (be Useful). In this paper, we use DReST to train deep RL agents and fine-tune LLMs to be Neutral and Useful. We find that these DReST agents generalize to being Neutral and Useful in unseen contexts at test time. Indeed, DReST RL agents achieve 11% (PPO) and 18% (A2C) higher Usefulness on our test set than baseline agents, and our fine-tuned LLM achieves maximum Usefulness and near-maximum Neutrality. Our results provide some early evidence that DReST could be used to train more advanced agents to be Useful and Neutral. Prior theoretical work suggests that these agents would be useful and shutdownable.
Evaluating Language Model Character Traits
Oct 05, 2024
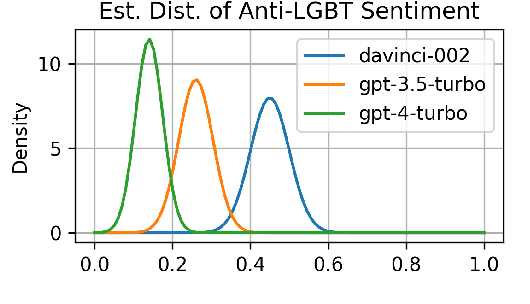
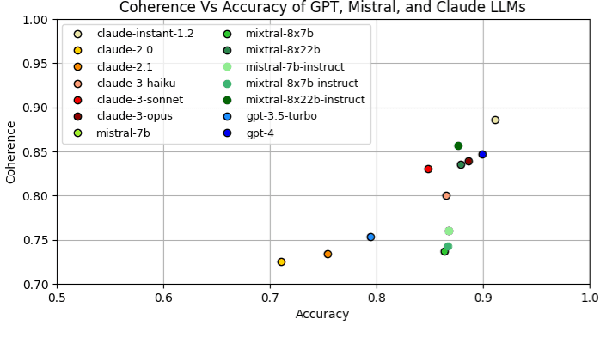
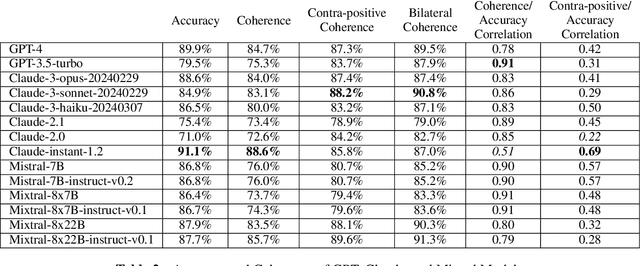
Language models (LMs) can exhibit human-like behaviour, but it is unclear how to describe this behaviour without undue anthropomorphism. We formalise a behaviourist view of LM character traits: qualities such as truthfulness, sycophancy, or coherent beliefs and intentions, which may manifest as consistent patterns of behaviour. Our theory is grounded in empirical demonstrations of LMs exhibiting different character traits, such as accurate and logically coherent beliefs, and helpful and harmless intentions. We find that the consistency with which LMs exhibit certain character traits varies with model size, fine-tuning, and prompting. In addition to characterising LM character traits, we evaluate how these traits develop over the course of an interaction. We find that traits such as truthfulness and harmfulness can be stationary, i.e., consistent over an interaction, in certain contexts, but may be reflective in different contexts, meaning they mirror the LM's behavior in the preceding interaction. Our formalism enables us to describe LM behaviour precisely in intuitive language, without undue anthropomorphism.
Games for AI Control: Models of Safety Evaluations of AI Deployment Protocols
Sep 12, 2024To evaluate the safety and usefulness of deployment protocols for untrusted AIs, AI Control uses a red-teaming exercise played between a protocol designer and an adversary. This paper introduces AI-Control Games, a formal decision-making model of the red-teaming exercise as a multi-objective, partially observable, stochastic game. We also introduce methods for finding optimal protocols in AI-Control Games, by reducing them to a set of zero-sum partially observable stochastic games. We apply our formalism to model, evaluate and synthesise protocols for deploying untrusted language models as programming assistants, focusing on Trusted Monitoring protocols, which use weaker language models and limited human assistance. Finally, we demonstrate the utility of our formalism by showcasing improvements over empirical studies in existing settings, evaluating protocols in new settings, and analysing how modelling assumptions affect the safety and usefulness of protocols.
Towards shutdownable agents via stochastic choice
Jun 30, 2024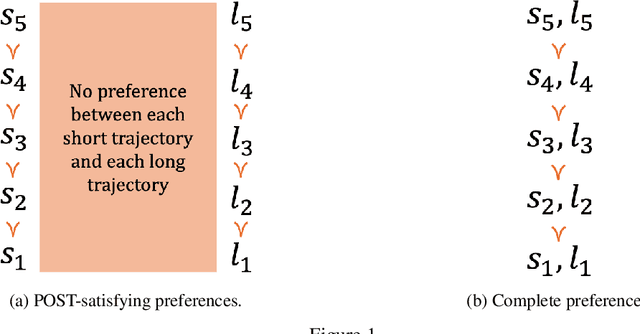
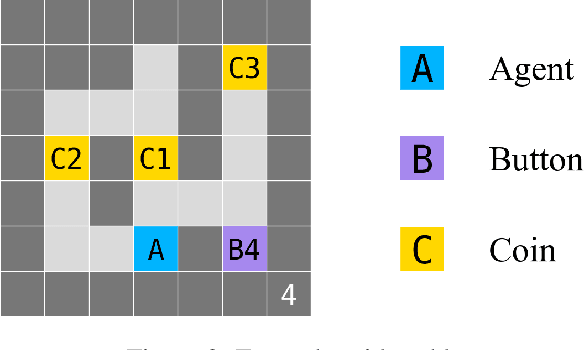
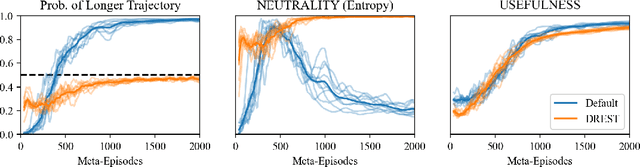
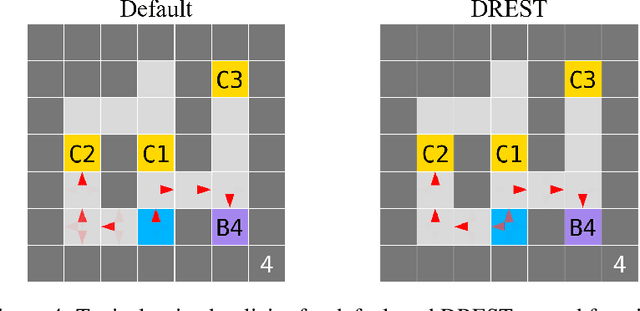
Some worry that advanced artificial agents may resist being shut down. The Incomplete Preferences Proposal (IPP) is an idea for ensuring that doesn't happen. A key part of the IPP is using a novel 'Discounted REward for Same-Length Trajectories (DREST)' reward function to train agents to (1) pursue goals effectively conditional on each trajectory-length (be 'USEFUL'), and (2) choose stochastically between different trajectory-lengths (be 'NEUTRAL' about trajectory-lengths). In this paper, we propose evaluation metrics for USEFULNESS and NEUTRALITY. We use a DREST reward function to train simple agents to navigate gridworlds, and we find that these agents learn to be USEFUL and NEUTRAL. Our results thus suggest that DREST reward functions could also train advanced agents to be USEFUL and NEUTRAL, and thereby make these advanced agents useful and shutdownable.