 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Shutdownable Agents: Generalizing Stochastic Choice in RL Agents and LLMs
Apr 19, 2026Misaligned artificial agents might resist shutdown. One proposed solution is to train agents to lack preferences between different-length trajectories. The Discounted Reward for Same-Length Trajectories (DReST) reward function does this by penalizing agents for repeatedly choosing same-length trajectories, and thus incentivizes agents to (1) choose stochastically between different trajectory-lengths (be Neutral about trajectory-lengths), and (2) pursue goals effectively conditional on each trajectory-length (be Useful). In this paper, we use DReST to train deep RL agents and fine-tune LLMs to be Neutral and Useful. We find that these DReST agents generalize to being Neutral and Useful in unseen contexts at test time. Indeed, DReST RL agents achieve 11% (PPO) and 18% (A2C) higher Usefulness on our test set than baseline agents, and our fine-tuned LLM achieves maximum Usefulness and near-maximum Neutrality. Our results provide some early evidence that DReST could be used to train more advanced agents to be Useful and Neutral. Prior theoretical work suggests that these agents would be useful and shutdownable.
ASTER -- Agentic Science Toolkit for Exoplanet Research
Mar 27, 2026The expansion of exoplanet observations has created a need for flexible, accessible, and user-friendly workflows. Transmission spectroscopy has become a key technique for probing atmospheric composition of transiting exoplanets. The analyses of these data require the combination of archival queries, literature search, the use of radiative transfer models, and Bayesian retrieval frameworks, each demanding specialized expertise. Modern large language models enable the coordinated execution of complex, multi-step tasks by AI agents with tool integration, structured prompts, and iterative reasoning. In this study we present ASTER, an Agentic Science Toolkit for Exoplanet Research. ASTER is an orchestration framework that brings LLM capability to the exoplanetary community by enabling LLM-driven interaction with integrated domain-specific tools, workflow planning and management, and support for common data analysis tasks. Currently ASTER incorporates tools for downloading planetary parameters and observational datasets from the NASA Exoplanet Archive, as well as the generation of transit spectra from the TauREx radiative transfer model, and the completion of Bayesian retrieval of planetary parameters with TauREx. Beyond tool integration, the agent assists users by proposing alternative modeling approaches, reporting potential issues and suggesting solutions, and interpretations. We demonstrate ASTER's workflow through a complete case study of WASP-39b, performing multiple retrievals using observational data available on the archive. The agent efficiently transitions between datasets, generates appropriate forward model spectra and performs retrievals. ASTER provides a unified platform for the characterization of exoplanet atmospheres. Ongoing development and community contributions will continue expanding ASTER's capabilities toward broader applications in exoplanet research.
Orchestral AI: A Framework for Agent Orchestration
Jan 05, 2026The rapid proliferation of LLM agent frameworks has forced developers to choose between vendor lock-in through provider-specific SDKs and complex multi-package ecosystems that obscure control flow and hinder reproducibility. Integrating tool calling across multiple LLM providers remains a core engineering challenge due to fragmented APIs, incompatible message formats, and inconsistent streaming and tool-calling behavior, making it difficult to build portable, reliable agent systems. We introduce Orchestral, a lightweight Python framework that provides a unified, type-safe interface for building LLM agents across major providers while preserving the simplicity required for scientific computing and production deployment. Orchestral defines a single universal representation for messages, tools, and LLM usage that operates seamlessly across providers, eliminating manual format translation and reducing framework-induced complexity. Automatic tool schema generation from Python type hints removes the need for handwritten descriptors while maintaining type safety across provider boundaries. A synchronous execution model with streaming support enables deterministic behavior, straightforward debugging, and real-time interaction without introducing server dependencies. The framework's modular architecture cleanly separates provider integration, tool execution, conversation orchestration, and user-facing interfaces, enabling extensibility without architectural entanglement. Orchestral supports advanced agent capabilities found in larger frameworks, including rich tool calling, context compaction, workspace sandboxing, user approval workflows, sub-agents, memory management, and MCP integration.
Hunting for "Oddballs" with Machine Learning: Detecting Anomalous Exoplanets Using a Deep-Learned Low-Dimensional Representation of Transit Spectra with Autoencoders
Jan 05, 2026This study explores the application of autoencoder-based machine learning techniques for anomaly detection to identify exoplanet atmospheres with unconventional chemical signatures using a low-dimensional data representation. We use the Atmospheric Big Challenge (ABC) database, a publicly available dataset with over 100,000 simulated exoplanet spectra, to construct an anomaly detection scenario by defining CO2-rich atmospheres as anomalies and CO2-poor atmospheres as the normal class. We benchmarked four different anomaly detection strategies: Autoencoder Reconstruction Loss, One-Class Support Vector Machine (1 class-SVM), K-means Clustering, and Local Outlier Factor (LOF). Each method was evaluated in both the original spectral space and the autoencoder's latent space using Receiver Operating Characteristic (ROC) curves and Area Under the Curve (AUC) metrics. To test the performance of the different methods under realistic conditions, we introduced Gaussian noise levels ranging from 10 to 50 ppm. Our results indicate that anomaly detection is consistently more effective when performed within the latent space across all noise levels. Specifically, K-means clustering in the latent space emerged as a stable and high-performing method. We demonstrate that this anomaly detection approach is robust to noise levels up to 30 ppm (consistent with realistic space-based observations) and remains viable even at 50 ppm when leveraging latent space representations. On the other hand, the performance of the anomaly detection methods applied directly in the raw spectral space degrades significantly with increasing the level of noise. This suggests that autoencoder-driven dimensionality reduction offers a robust methodology for flagging chemically anomalous targets in large-scale surveys where exhaustive retrievals are computationally prohibitive.
Towards shutdownable agents via stochastic choice
Jun 30, 2024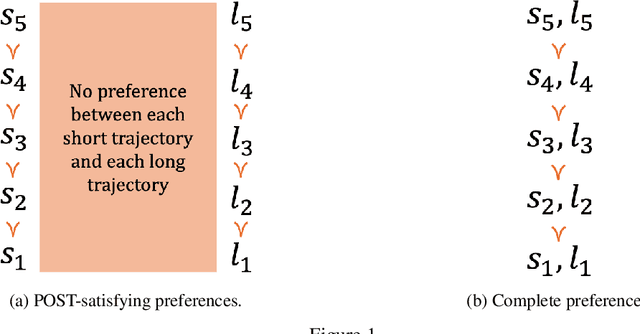
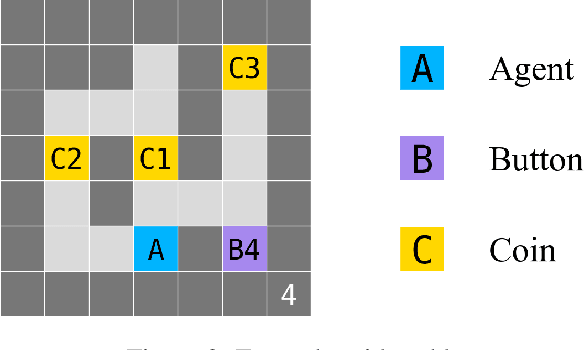
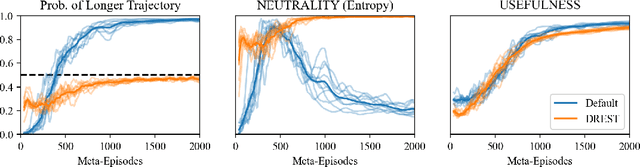
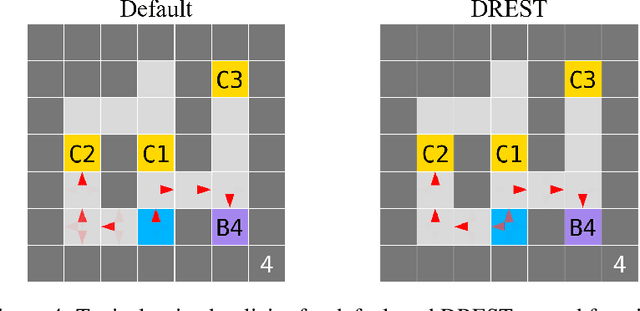
Some worry that advanced artificial agents may resist being shut down. The Incomplete Preferences Proposal (IPP) is an idea for ensuring that doesn't happen. A key part of the IPP is using a novel 'Discounted REward for Same-Length Trajectories (DREST)' reward function to train agents to (1) pursue goals effectively conditional on each trajectory-length (be 'USEFUL'), and (2) choose stochastically between different trajectory-lengths (be 'NEUTRAL' about trajectory-lengths). In this paper, we propose evaluation metrics for USEFULNESS and NEUTRALITY. We use a DREST reward function to train simple agents to navigate gridworlds, and we find that these agents learn to be USEFUL and NEUTRAL. Our results thus suggest that DREST reward functions could also train advanced agents to be USEFUL and NEUTRAL, and thereby make these advanced agents useful and shutdownable.
Identifying the Group-Theoretic Structure of Machine-Learned Symmetries
Sep 14, 2023


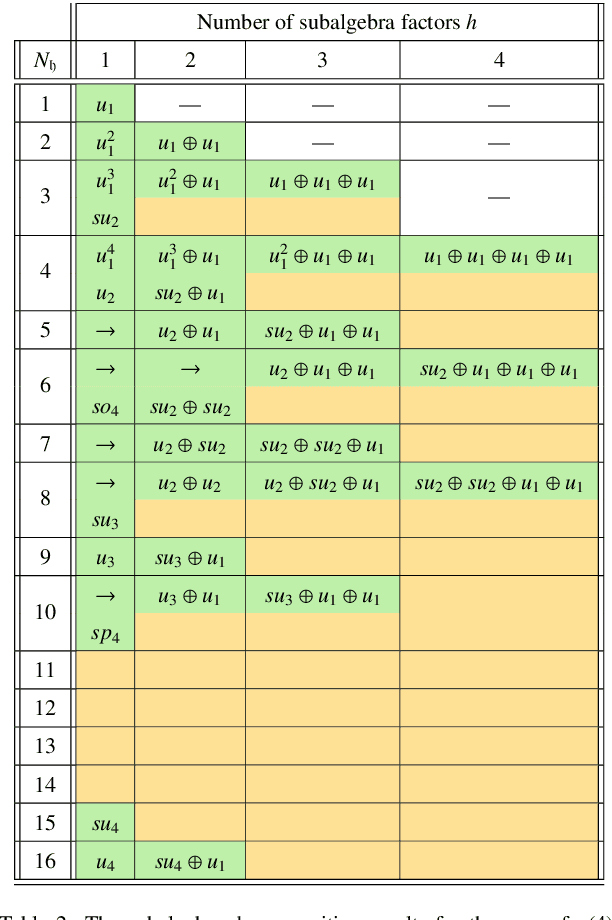
Deep learning was recently successfully used in deriving symmetry transformations that preserve important physics quantities. Being completely agnostic, these techniques postpone the identification of the discovered symmetries to a later stage. In this letter we propose methods for examining and identifying the group-theoretic structure of such machine-learned symmetries. We design loss functions which probe the subalgebra structure either during the deep learning stage of symmetry discovery or in a subsequent post-processing stage. We illustrate the new methods with examples from the U(n) Lie group family, obtaining the respective subalgebra decompositions. As an application to particle physics, we demonstrate the identification of the residual symmetries after the spontaneous breaking of non-Abelian gauge symmetries like SU(3) and SU(5) which are commonly used in model building.
Accelerated Discovery of Machine-Learned Symmetries: Deriving the Exceptional Lie Groups G2, F4 and E6
Jul 10, 2023
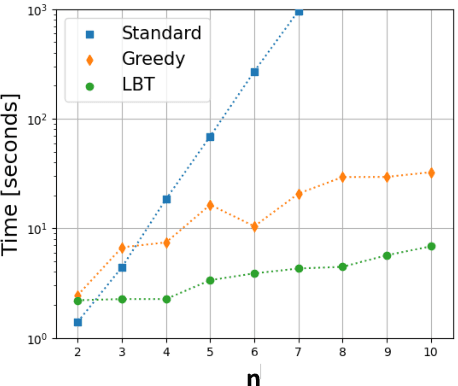


Recent work has applied supervised deep learning to derive continuous symmetry transformations that preserve the data labels and to obtain the corresponding algebras of symmetry generators. This letter introduces two improved algorithms that significantly speed up the discovery of these symmetry transformations. The new methods are demonstrated by deriving the complete set of generators for the unitary groups U(n) and the exceptional Lie groups $G_2$, $F_4$, and $E_6$. A third post-processing algorithm renders the found generators in sparse form. We benchmark the performance improvement of the new algorithms relative to the standard approach. Given the significant complexity of the exceptional Lie groups, our results demonstrate that this machine-learning method for discovering symmetries is completely general and can be applied to a wide variety of labeled datasets.
Discovering Sparse Representations of Lie Groups with Machine Learning
Feb 10, 2023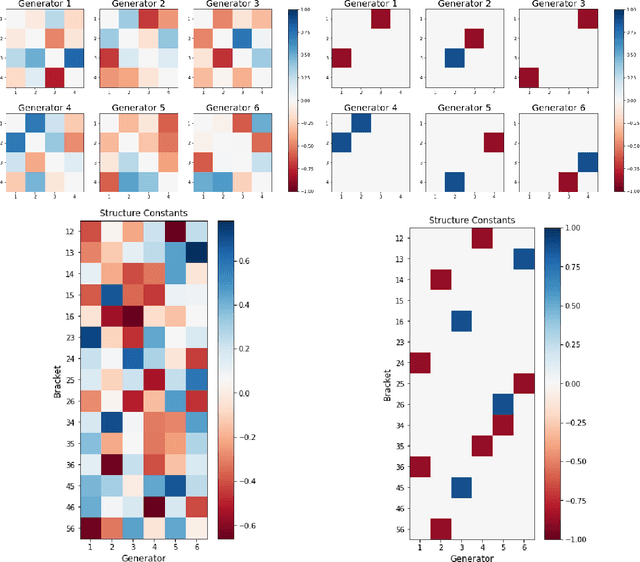

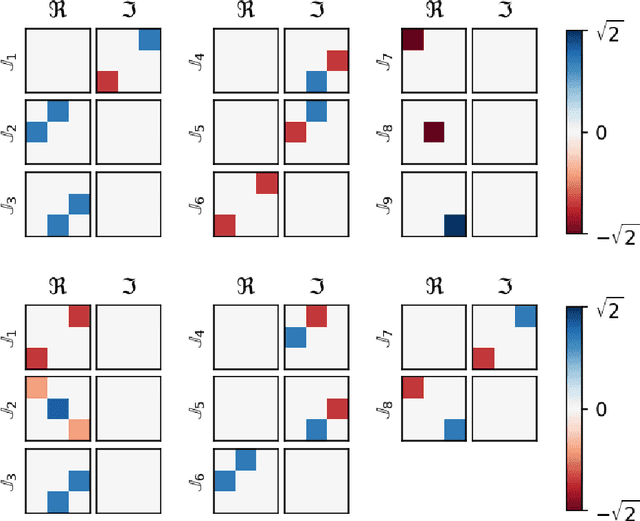
Recent work has used deep learning to derive symmetry transformations, which preserve conserved quantities, and to obtain the corresponding algebras of generators. In this letter, we extend this technique to derive sparse representations of arbitrary Lie algebras. We show that our method reproduces the canonical (sparse) representations of the generators of the Lorentz group, as well as the $U(n)$ and $SU(n)$ families of Lie groups. This approach is completely general and can be used to find the infinitesimal generators for any Lie group.
Oracle-Preserving Latent Flows
Feb 02, 2023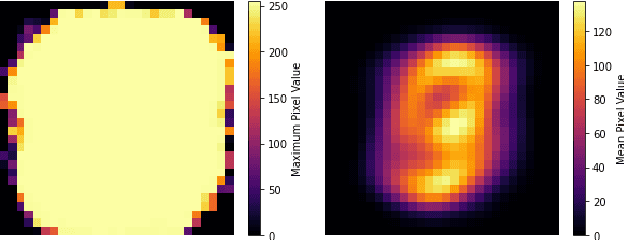
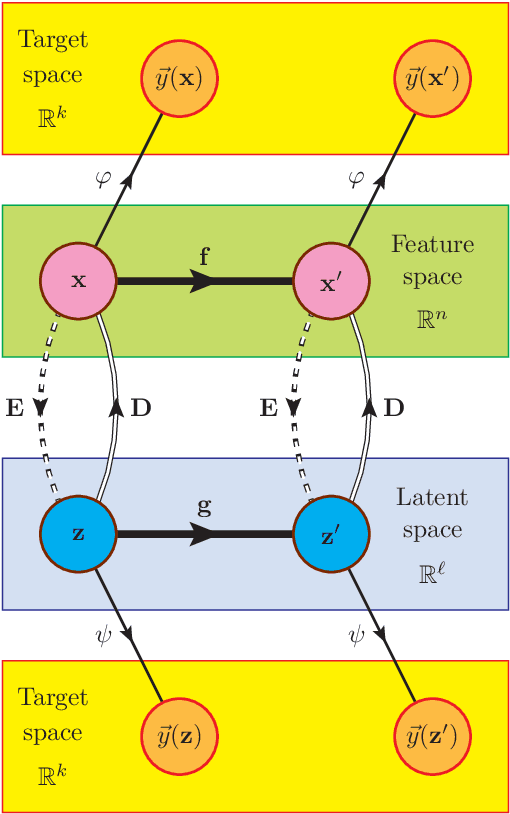
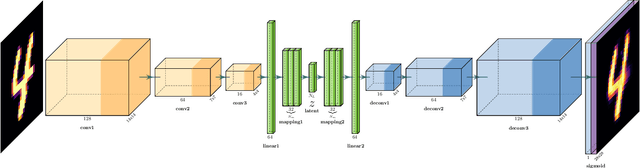
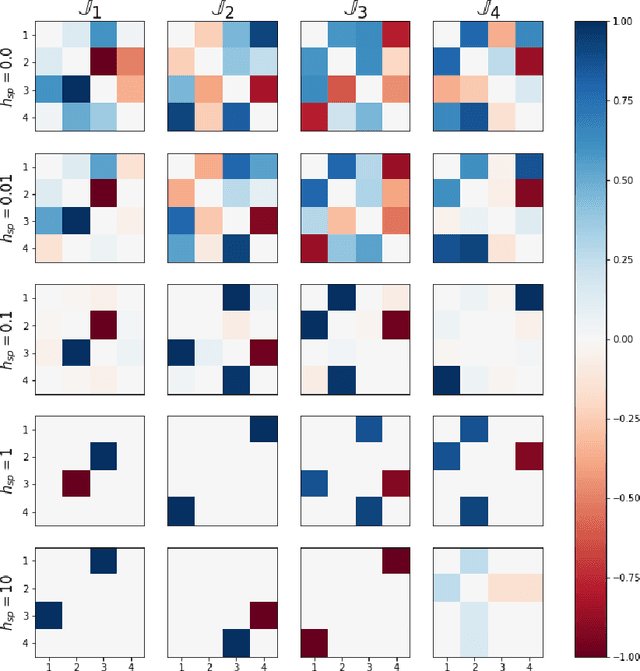
We develop a deep learning methodology for the simultaneous discovery of multiple nontrivial continuous symmetries across an entire labelled dataset. The symmetry transformations and the corresponding generators are modeled with fully connected neural networks trained with a specially constructed loss function ensuring the desired symmetry properties. The two new elements in this work are the use of a reduced-dimensionality latent space and the generalization to transformations invariant with respect to high-dimensional oracles. The method is demonstrated with several examples on the MNIST digit dataset.
Deep Learning Symmetries and Their Lie Groups, Algebras, and Subalgebras from First Principles
Jan 13, 2023We design a deep-learning algorithm for the discovery and identification of the continuous group of symmetries present in a labeled dataset. We use fully connected neural networks to model the symmetry transformations and the corresponding generators. We construct loss functions that ensure that the applied transformations are symmetries and that the corresponding set of generators forms a closed (sub)algebra. Our procedure is validated with several examples illustrating different types of conserved quantities preserved by symmetry. In the process of deriving the full set of symmetries, we analyze the complete subgroup structure of the rotation groups $SO(2)$, $SO(3)$, and $SO(4)$, and of the Lorentz group $SO(1,3)$. Other examples include squeeze mapping, piecewise discontinuous labels, and $SO(10)$, demonstrating that our method is completely general, with many possible applications in physics and data science. Our study also opens the door for using a machine learning approach in the mathematical study of Lie groups and their properties.