 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Generated Videos in Feasible Plans via World Models
Feb 02, 2026Large-scale video generative models have shown emerging capabilities as zero-shot visual planners, yet video-generated plans often violate temporal consistency and physical constraints, leading to failures when mapped to executable actions. To address this, we propose Grounding Video Plans with World Models (GVP-WM), a planning method that grounds video-generated plans into feasible action sequences using a learned action-conditioned world model. At test-time, GVP-WM first generates a video plan from initial and goal observations, then projects the video guidance onto the manifold of dynamically feasible latent trajectories via video-guided latent collocation. In particular, we formulate grounding as a goal-conditioned latent-space trajectory optimization problem that jointly optimizes latent states and actions under world-model dynamics, while preserving semantic alignment with the video-generated plan. Empirically, GVP-WM recovers feasible long-horizon plans from zero-shot image-to-video-generated and motion-blurred videos that violate physical constraints, across navigation and manipulation simulation tasks.
Red-Bandit: Test-Time Adaptation for LLM Red-Teaming via Bandit-Guided LoRA Experts
Oct 08, 2025Automated red-teaming has emerged as a scalable approach for auditing Large Language Models (LLMs) prior to deployment, yet existing approaches lack mechanisms to efficiently adapt to model-specific vulnerabilities at inference. We introduce Red-Bandit, a red-teaming framework that adapts online to identify and exploit model failure modes under distinct attack styles (e.g., manipulation, slang). Red-Bandit post-trains a set of parameter-efficient LoRA experts, each specialized for a particular attack style, using reinforcement learning that rewards the generation of unsafe prompts via a rule-based safety model. At inference, a multi-armed bandit policy dynamically selects among these attack-style experts based on the target model's response safety, balancing exploration and exploitation. Red-Bandit achieves state-of-the-art results on AdvBench under sufficient exploration (ASR@10), while producing more human-readable prompts (lower perplexity). Moreover, Red-Bandit's bandit policy serves as a diagnostic tool for uncovering model-specific vulnerabilities by indicating which attack styles most effectively elicit unsafe behaviors.
Test-Time Adaptation for Generalizable Task Progress Estimation
Jun 11, 2025We propose a test-time adaptation method that enables a progress estimation model to adapt online to the visual and temporal context of test trajectories by optimizing a learned self-supervised objective. To this end, we introduce a gradient-based meta-learning strategy to train the model on expert visual trajectories and their natural language task descriptions, such that test-time adaptation improves progress estimation relying on semantic content over temporal order. Our test-time adaptation method generalizes from a single training environment to diverse out-of-distribution tasks, environments, and embodiments, outperforming the state-of-the-art in-context learning approach using autoregressive vision-language models.
Towards shutdownable agents via stochastic choice
Jun 30, 2024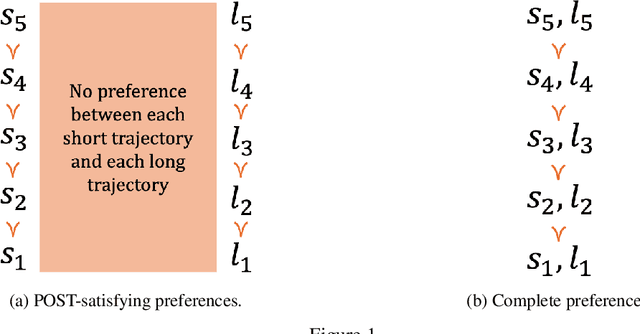
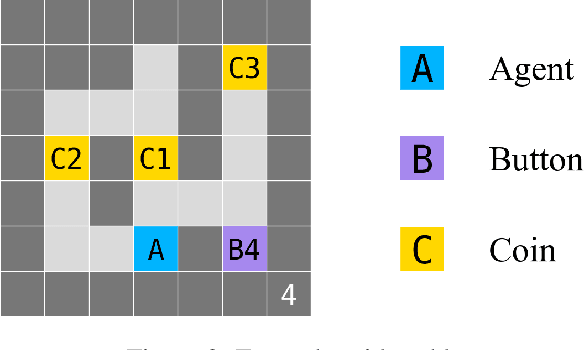
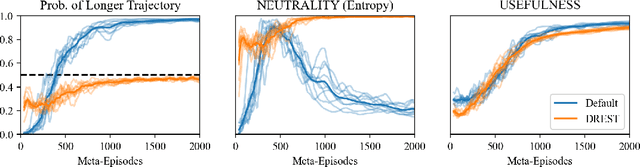
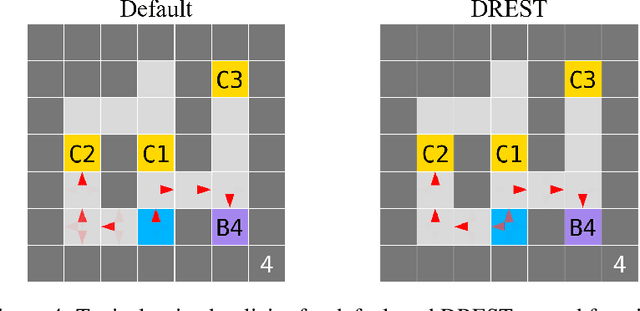
Some worry that advanced artificial agents may resist being shut down. The Incomplete Preferences Proposal (IPP) is an idea for ensuring that doesn't happen. A key part of the IPP is using a novel 'Discounted REward for Same-Length Trajectories (DREST)' reward function to train agents to (1) pursue goals effectively conditional on each trajectory-length (be 'USEFUL'), and (2) choose stochastically between different trajectory-lengths (be 'NEUTRAL' about trajectory-lengths). In this paper, we propose evaluation metrics for USEFULNESS and NEUTRALITY. We use a DREST reward function to train simple agents to navigate gridworlds, and we find that these agents learn to be USEFUL and NEUTRAL. Our results thus suggest that DREST reward functions could also train advanced agents to be USEFUL and NEUTRAL, and thereby make these advanced agents useful and shutdownable.
BackboneLearn: A Library for Scaling Mixed-Integer Optimization-Based Machine Learning
Nov 22, 2023
We present BackboneLearn: an open-source software package and framework for scaling mixed-integer optimization (MIO) problems with indicator variables to high-dimensional problems. This optimization paradigm can naturally be used to formulate fundamental problems in interpretable supervised learning (e.g., sparse regression and decision trees), in unsupervised learning (e.g., clustering), and beyond; BackboneLearn solves the aforementioned problems faster than exact methods and with higher accuracy than commonly used heuristics. The package is built in Python and is user-friendly and easily extensible: users can directly implement a backbone algorithm for their MIO problem at hand. The source code of BackboneLearn is available on GitHub (link: https://github.com/chziakas/backbone_learn).