 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Stable Machine Learning Model Retraining via Slowly Varying Sequences
Apr 08, 2024



Retraining machine learning models remains an important task for real-world machine learning model deployment. Existing methods focus largely on greedy approaches to find the best-performing model without considering the stability of trained model structures across different retraining evolutions. In this study, we develop a mixed integer optimization algorithm that holistically considers the problem of retraining machine learning models across different data batch updates. Our method focuses on retaining consistent analytical insights - which is important to model interpretability, ease of implementation, and fostering trust with users - by using custom-defined distance metrics that can be directly incorporated into the optimization problem. Importantly, our method shows stronger stability than greedily trained models with a small, controllable sacrifice in model performance in a real-world production case study. Finally, important analytical insights, as demonstrated using SHAP feature importance, are shown to be consistent across retraining iterations.
BackboneLearn: A Library for Scaling Mixed-Integer Optimization-Based Machine Learning
Nov 22, 2023
We present BackboneLearn: an open-source software package and framework for scaling mixed-integer optimization (MIO) problems with indicator variables to high-dimensional problems. This optimization paradigm can naturally be used to formulate fundamental problems in interpretable supervised learning (e.g., sparse regression and decision trees), in unsupervised learning (e.g., clustering), and beyond; BackboneLearn solves the aforementioned problems faster than exact methods and with higher accuracy than commonly used heuristics. The package is built in Python and is user-friendly and easily extensible: users can directly implement a backbone algorithm for their MIO problem at hand. The source code of BackboneLearn is available on GitHub (link: https://github.com/chziakas/backbone_learn).
Improving Stability in Decision Tree Models
May 26, 2023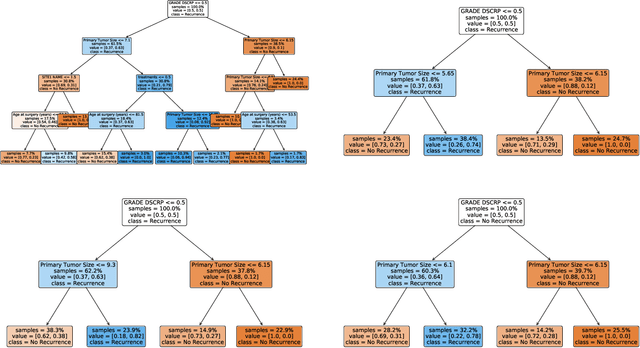

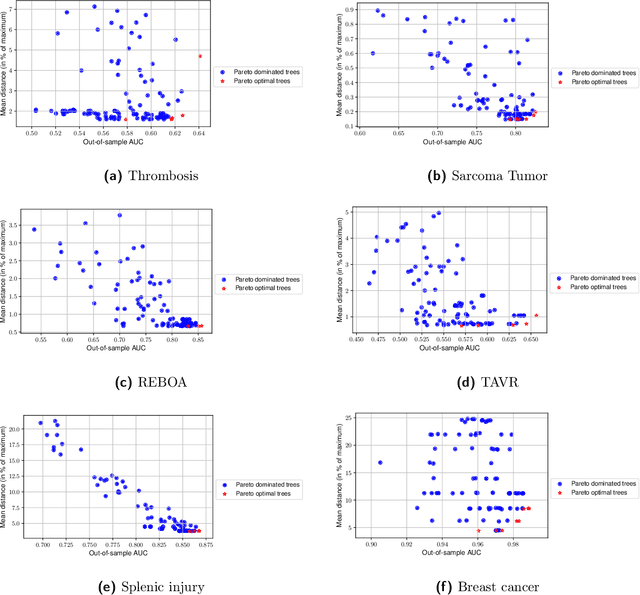
Owing to their inherently interpretable structure, decision trees are commonly used in applications where interpretability is essential. Recent work has focused on improving various aspects of decision trees, including their predictive power and robustness; however, their instability, albeit well-documented, has been addressed to a lesser extent. In this paper, we take a step towards the stabilization of decision tree models through the lens of real-world health care applications due to the relevance of stability and interpretability in this space. We introduce a new distance metric for decision trees and use it to determine a tree's level of stability. We propose a novel methodology to train stable decision trees and investigate the existence of trade-offs that are inherent to decision tree models - including between stability, predictive power, and interpretability. We demonstrate the value of the proposed methodology through an extensive quantitative and qualitative analysis of six case studies from real-world health care applications, and we show that, on average, with a small 4.6% decrease in predictive power, we gain a significant 38% improvement in the model's stability.
Frequency Estimation in Data Streams: Learning the Optimal Hashing Scheme
Jul 17, 2020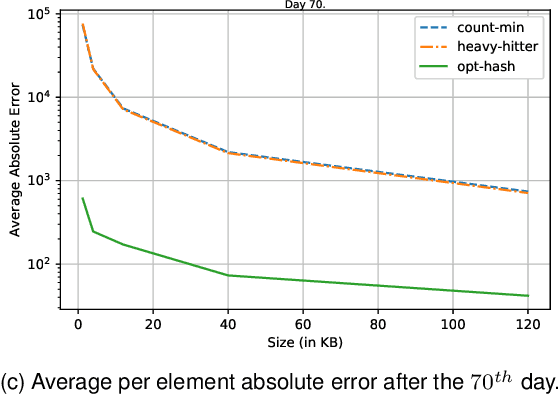
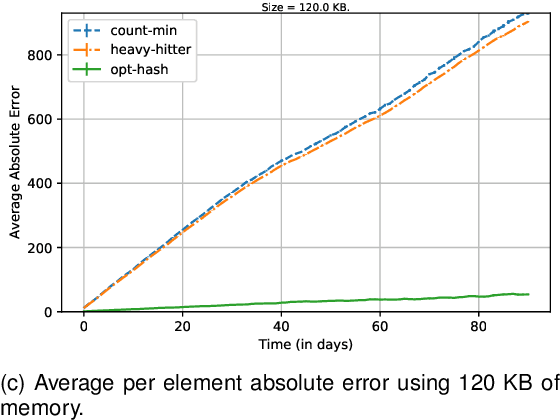
We present a novel approach for the problem of frequency estimation in data streams that is based on optimization and machine learning. Contrary to state-of-the-art streaming frequency estimation algorithms, which heavily rely on random hashing to maintain the frequency distribution of the data steam using limited storage, the proposed approach exploits an observed stream prefix to near-optimally hash elements and compress the target frequency distribution. We develop an exact mixed-integer linear optimization formulation, as well as an efficient block coordinate descent algorithm, that enable us to compute near-optimal hashing schemes for elements seen in the observed stream prefix; then, we use machine learning to hash unseen elements. We empirically evaluate the proposed approach on real-world search query data and show that it outperforms existing approaches by one to two orders of magnitude in terms of its average (per element) estimation error and by 45-90% in terms of its expected magnitude of estimation error.
The Backbone Method for Ultra-High Dimensional Sparse Machine Learning
Jun 11, 2020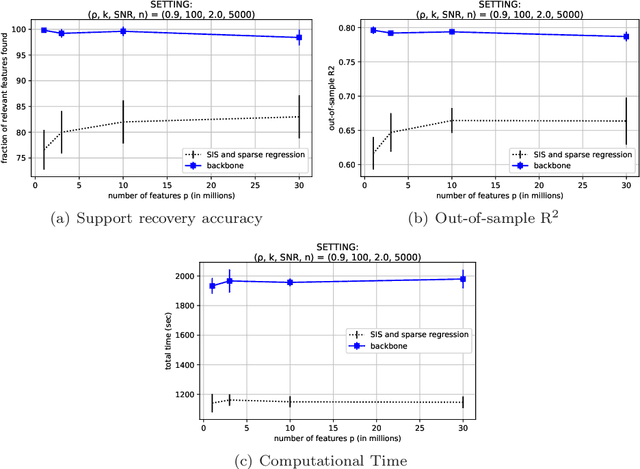
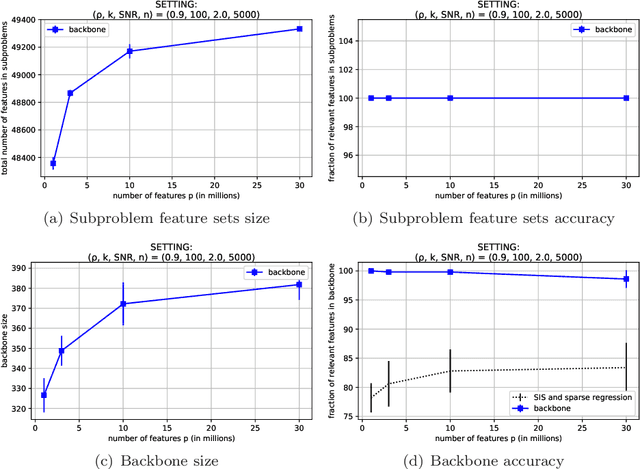
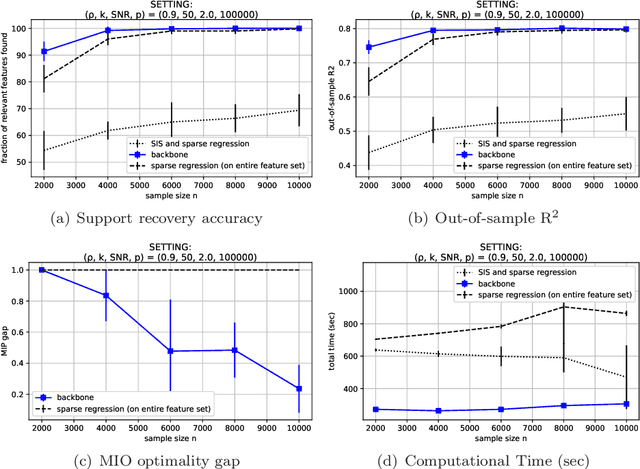
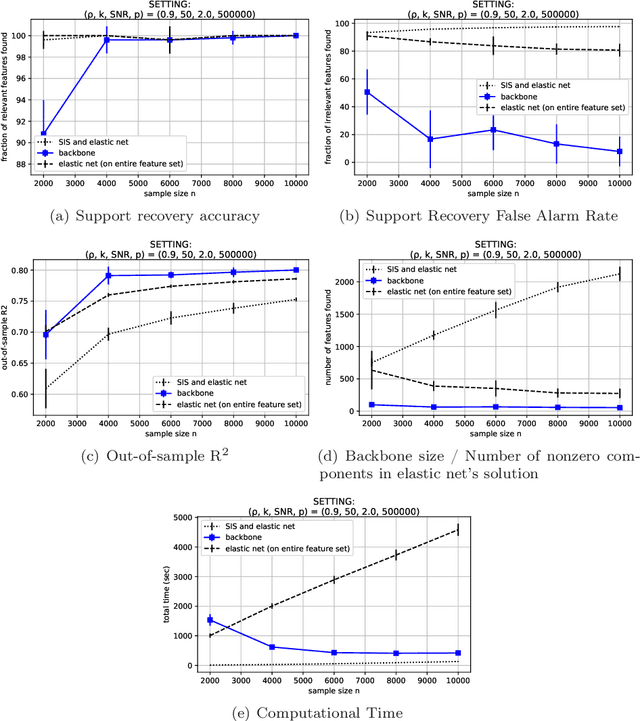
We present the backbone method, a generic framework that enables sparse and interpretable supervised machine learning methods to scale to ultra-high dimensional problems. We solve, in minutes, sparse regression problems with $p\sim10^7$ features and decision tree induction problems with $p\sim10^5$ features. The proposed method operates in two phases; we first determine the backbone set, that consists of potentially relevant features, by solving a number of tractable subproblems; then, we solve a reduced problem, considering only the backbone features. Numerical experiments demonstrate that our method competes with optimal solutions, when exact methods apply, and substantially outperforms baseline heuristics, when exact methods do not scale, both in terms of recovering the true relevant features and in its out-of-sample predictive performance.