 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Midas Touch for Metric Depth
May 12, 2026Recent advances have markedly improved the cross-scene generalization of relative depth estimation, yet its practical applicability remains limited by the absence of metric scale, local inconsistencies, and low computational efficiency. To address these issues, we present \emph{\textbf{M}idas \textbf{T}ouch for \textbf{D}epth} (MTD), a mathematically interpretable approach that converts relative depth into metric depth using only extremely sparse 3D data. To eliminate local scale inconsistencies, it applies a segment-wise recovery strategy via sparse graph optimization, followed by a pixel-wise refinement strategy using a discontinuity-aware geodesic cost. MTD exhibits strong generalization and achieves substantial accuracy improvements over previous depth completion and depth estimation methods. Moreover, its lightweight, plug-and-play design facilitates deployment and integration on diverse downstream 3D tasks. Project page is available at https://mias.group/MTD.
FAST: A Synergistic Framework of Attention and State-space Models for Spatiotemporal Traffic Prediction
Apr 15, 2026Traffic forecasting requires modeling complex temporal dynamics and long-range spatial dependencies over large sensor networks. Existing methods typically face a trade-off between expressiveness and efficiency: Transformer-based models capture global dependencies well but suffer from quadratic complexity, while recent selective state-space models are computationally efficient yet less effective at modeling spatial interactions in graph-structured traffic data. We propose FAST, a unified framework that combines attention and state-space modeling for scalable spatiotemporal traffic forecasting. FAST adopts a Temporal-Spatial-Temporal architecture, where temporal attention modules capture both short- and long-term temporal patterns, and a Mamba-based spatial module models long-range inter-sensor dependencies with linear complexity. To better represent heterogeneous traffic contexts, FAST further introduces a learnable multi-source spatiotemporal embedding that integrates historical traffic flow, temporal context, and node-level information, together with a multi-level skip prediction mechanism for hierarchical feature fusion. Experiments on PeMS04, PeMS07, and PeMS08 show that FAST consistently outperforms strong baselines from Transformer-, GNN-, attention-, and Mamba-based families. In particular, FAST achieves the best MAE and RMSE on all three benchmarks, with up to 4.3\% lower RMSE and 2.8\% lower MAE than the strongest baseline, demonstrating a favorable balance between accuracy, scalability, and generalization.
An Instance-Centric Panoptic Occupancy Prediction Benchmark for Autonomous Driving
Mar 28, 2026Panoptic occupancy prediction aims to jointly infer voxel-wise semantics and instance identities within a unified 3D scene representation. Nevertheless, progress in this field remains constrained by the absence of high-quality 3D mesh resources, instance-level annotations, and physically consistent occupancy datasets. Existing benchmarks typically provide incomplete and low-resolution geometry without instance-level annotations, limiting the development of models capable of achieving precise geometric reconstruction, reliable occlusion reasoning, and holistic 3D understanding. To address these challenges, this paper presents an instance-centric benchmark for the 3D panoptic occupancy prediction task. Specifically, we introduce ADMesh, the first unified 3D mesh library tailored for autonomous driving, which integrates over 15K high-quality 3D models with diverse textures and rich semantic annotations. Building upon ADMesh, we further construct CarlaOcc, a large-scale, physically consistent panoptic occupancy dataset generated using the CARLA simulator. This dataset contains over 100K frames with fine-grained, instance-level occupancy ground truth at voxel resolutions as fine as 0.05 m. Furthermore, standardized evaluation metrics are introduced to quantify the quality of existing occupancy datasets. Finally, a systematic benchmark of representative models is established on the proposed dataset, which provides a unified platform for fair comparison and reproducible research in the field of 3D panoptic perception. Code and dataset are available at https://mias.group/CarlaOcc.
Task-Specific Efficiency Analysis: When Small Language Models Outperform Large Language Models
Mar 22, 2026Large Language Models achieve remarkable performance but incur substantial computational costs unsuitable for resource-constrained deployments. This paper presents the first comprehensive task-specific efficiency analysis comparing 16 language models across five diverse NLP tasks. We introduce the Performance-Efficiency Ratio (PER), a novel metric integrating accuracy, throughput, memory, and latency through geometric mean normalization. Our systematic evaluation reveals that small models (0.5--3B parameters) achieve superior PER scores across all given tasks. These findings establish quantitative foundations for deploying small models in production environments prioritizing inference efficiency over marginal accuracy gains.
Spectral Analysis of Hard-Constraint PINNs: The Spatial Modulation Mechanism of Boundary Functions
Dec 29, 2025Physics-Informed Neural Networks with hard constraints (HC-PINNs) are increasingly favored for their ability to strictly enforce boundary conditions via a trial function ansatz $\tilde{u} = A + B \cdot N$, yet the theoretical mechanisms governing their training dynamics have remained unexplored. Unlike soft-constrained formulations where boundary terms act as additive penalties, this work reveals that the boundary function $B$ introduces a multiplicative spatial modulation that fundamentally alters the learning landscape. A rigorous Neural Tangent Kernel (NTK) framework for HC-PINNs is established, deriving the explicit kernel composition law. This relationship demonstrates that the boundary function $B(\vec{x})$ functions as a spectral filter, reshaping the eigenspectrum of the neural network's native kernel. Through spectral analysis, the effective rank of the residual kernel is identified as a deterministic predictor of training convergence, superior to classical condition numbers. It is shown that widely used boundary functions can inadvertently induce spectral collapse, leading to optimization stagnation despite exact boundary satisfaction. Validated across multi-dimensional benchmarks, this framework transforms the design of boundary functions from a heuristic choice into a principled spectral optimization problem, providing a solid theoretical foundation for geometric hard constraints in scientific machine learning.
Early Warning Index for Patient Deteriorations in Hospitals
Dec 16, 2025

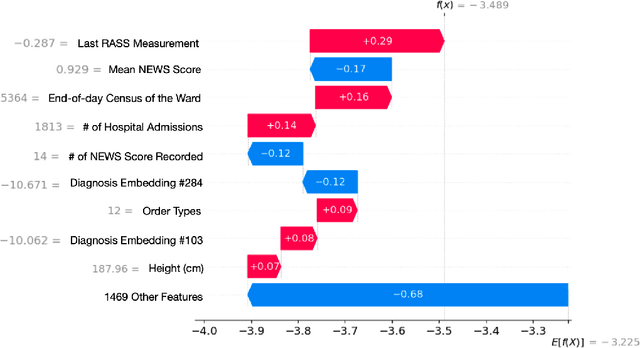

Hospitals lack automated systems to harness the growing volume of heterogeneous clinical and operational data to effectively forecast critical events. Early identification of patients at risk for deterioration is essential not only for patient care quality monitoring but also for physician care management. However, translating varied data streams into accurate and interpretable risk assessments poses significant challenges due to inconsistent data formats. We develop a multimodal machine learning framework, the Early Warning Index (EWI), to predict the aggregate risk of ICU admission, emergency response team dispatch, and mortality. Key to EWI's design is a human-in-the-loop process: clinicians help determine alert thresholds and interpret model outputs, which are enhanced by explainable outputs using Shapley Additive exPlanations (SHAP) to highlight clinical and operational factors (e.g., scheduled surgeries, ward census) driving each patient's risk. We deploy EWI in a hospital dashboard that stratifies patients into three risk tiers. Using a dataset of 18,633 unique patients at a large U.S. hospital, our approach automatically extracts features from both structured and unstructured electronic health record (EHR) data and achieves C-statistics of 0.796. It is currently used as a triage tool for proactively managing at-risk patients. The proposed approach saves physicians valuable time by automatically sorting patients of varying risk levels, allowing them to concentrate on patient care rather than sifting through complex EHR data. By further pinpointing specific risk drivers, the proposed model provides data-informed adjustments to caregiver scheduling and allocation of critical resources. As a result, clinicians and administrators can avert downstream complications, including costly procedures or high readmission rates and improve overall patient flow.
Towards Optimal Valve Prescription for Transcatheter Aortic Valve Replacement (TAVR) Surgery: A Machine Learning Approach
Dec 09, 2025Transcatheter Aortic Valve Replacement (TAVR) has emerged as a minimally invasive treatment option for patients with severe aortic stenosis, a life-threatening cardiovascular condition. Multiple transcatheter heart valves (THV) have been approved for use in TAVR, but current guidelines regarding valve type prescription remain an active topic of debate. We propose a data-driven clinical support tool to identify the optimal valve type with the objective of minimizing the risk of permanent pacemaker implantation (PPI), a predominant postoperative complication. We synthesize a novel dataset that combines U.S. and Greek patient populations and integrates three distinct data sources (patient demographics, computed tomography scans, echocardiograms) while harmonizing differences in each country's record system. We introduce a leaf-level analysis to leverage population heterogeneity and avoid benchmarking against uncertain counterfactual risk estimates. The final prescriptive model shows a reduction in PPI rates of 26% and 16% compared with the current standard of care in our internal U.S. population and external Greek validation cohort, respectively. To the best of our knowledge, this work represents the first unified, personalized prescription strategy for THV selection in TAVR.
Distributionally Robust Multimodal Machine Learning
Nov 07, 2025We consider the problem of distributionally robust multimodal machine learning. Existing approaches often rely on merging modalities on the feature level (early fusion) or heuristic uncertainty modeling, which downplays modality-aware effects and provide limited insights. We propose a novel distributionally robust optimization (DRO) framework that aims to study both the theoretical and practical insights of multimodal machine learning. We first justify this setup and show the significance of this problem through complexity analysis. We then establish both generalization upper bounds and minimax lower bounds which provide performance guarantees. These results are further extended in settings where we consider encoder-specific error propogations. Empirically, we demonstrate that our approach improves robustness in both simulation settings and real-world datasets. Together, these findings provide a principled foundation for employing multimodal machine learning models in high-stakes applications where uncertainty is unavoidable.
CATCH: A Modular Cross-domain Adaptive Template with Hook
Oct 30, 2025



Recent advances in Visual Question Answering (VQA) have demonstrated impressive performance in natural image domains, with models like LLaVA leveraging large language models (LLMs) for open-ended reasoning. However, their generalization degrades significantly when transferred to out-of-domain scenarios such as remote sensing, medical imaging, or math diagrams, due to large distributional shifts and the lack of effective domain adaptation mechanisms. Existing approaches typically rely on per-domain fine-tuning or bespoke pipelines, which are costly, inflexible, and not scalable across diverse tasks. In this paper, we propose CATCH, a plug-and-play framework for cross-domain adaptation that improves the generalization of VQA models while requiring minimal changes to their core architecture. Our key idea is to decouple visual and linguistic adaptation by introducing two lightweight modules: a domain classifier to identify the input image type, and a dual adapter mechanism comprising a Prompt Adapter for language modulation and a Visual Adapter for vision feature adjustment. Both modules are dynamically injected via a unified hook interface, requiring no retraining of the backbone model. Experimental results across four domain-specific VQA benchmarks demonstrate that our framework achieves consistent performance gains without retraining the backbone model, including +2.3 BLEU on MathVQA, +2.6 VQA on MedVQA-RAD, and +3.1 ROUGE on ChartQA. These results highlight that CATCH provides a scalable and extensible approach to multi-domain VQA, enabling practical deployment across diverse application domains.
Hy-Facial: Hybrid Feature Extraction by Dimensionality Reduction Methods for Enhanced Facial Expression Classification
Sep 30, 2025Facial expression classification remains a challenging task due to the high dimensionality and inherent complexity of facial image data. This paper presents Hy-Facial, a hybrid feature extraction framework that integrates both deep learning and traditional image processing techniques, complemented by a systematic investigation of dimensionality reduction strategies. The proposed method fuses deep features extracted from the Visual Geometry Group 19-layer network (VGG19) with handcrafted local descriptors and the scale-invariant feature transform (SIFT) and Oriented FAST and Rotated BRIEF (ORB) algorithms, to obtain rich and diverse image representations. To mitigate feature redundancy and reduce computational complexity, we conduct a comprehensive evaluation of dimensionality reduction techniques and feature extraction. Among these, UMAP is identified as the most effective, preserving both local and global structures of the high-dimensional feature space. The Hy-Facial pipeline integrated VGG19, SIFT, and ORB for feature extraction, followed by K-means clustering and UMAP for dimensionality reduction, resulting in a classification accuracy of 83. 3\% in the facial expression recognition (FER) dataset. These findings underscore the pivotal role of dimensionality reduction not only as a pre-processing step but as an essential component in improving feature quality and overall classification performance.