 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhyme-aware Chinese lyric generator based on GPT
Aug 19, 2024Neural language representation models such as GPT, pre-trained on large-scale corpora, can effectively capture rich semantic patterns from plain text and be fine-tuned to consistently improve natural language generation performance. However, existing pre-trained language models used to generate lyrics rarely consider rhyme information, which is crucial in lyrics. Using a pre-trained model directly results in poor performance. To enhance the rhyming quality of generated lyrics, we incorporate integrated rhyme information into our model, thereby improving lyric generation performance.
ICCV23 Visual-Dialog Emotion Explanation Challenge: SEU_309 Team Technical Report
Jul 13, 2024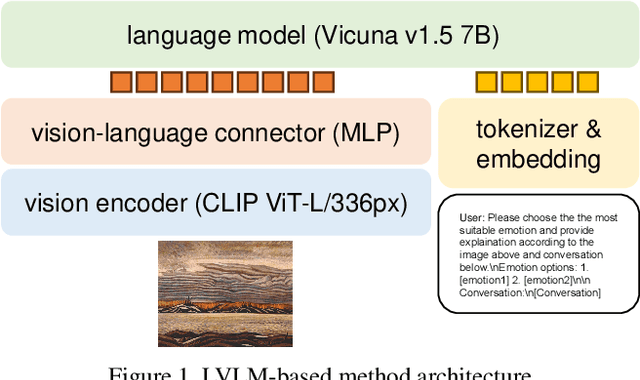

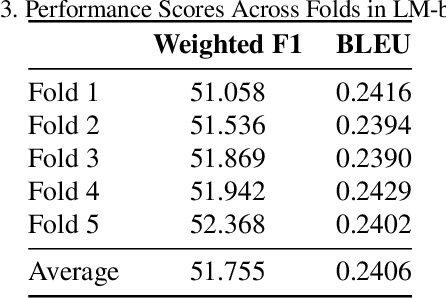
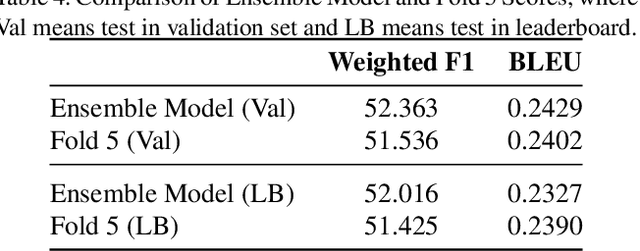
The Visual-Dialog Based Emotion Explanation Generation Challenge focuses on generating emotion explanations through visual-dialog interactions in art discussions. Our approach combines state-of-the-art multi-modal models, including Language Model (LM) and Large Vision Language Model (LVLM), to achieve superior performance. By leveraging these models, we outperform existing benchmarks, securing the top rank in the ICCV23 Visual-Dialog Based Emotion Explanation Generation Challenge, which is part of the 5th Workshop On Closing The Loop Between Vision And Language (CLCV) with significant scores in F1 and BLEU metrics. Our method demonstrates exceptional ability in generating accurate emotion explanations, advancing our understanding of emotional impacts in art.