 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATCH: A Modular Cross-domain Adaptive Template with Hook
Oct 30, 2025



Recent advances in Visual Question Answering (VQA) have demonstrated impressive performance in natural image domains, with models like LLaVA leveraging large language models (LLMs) for open-ended reasoning. However, their generalization degrades significantly when transferred to out-of-domain scenarios such as remote sensing, medical imaging, or math diagrams, due to large distributional shifts and the lack of effective domain adaptation mechanisms. Existing approaches typically rely on per-domain fine-tuning or bespoke pipelines, which are costly, inflexible, and not scalable across diverse tasks. In this paper, we propose CATCH, a plug-and-play framework for cross-domain adaptation that improves the generalization of VQA models while requiring minimal changes to their core architecture. Our key idea is to decouple visual and linguistic adaptation by introducing two lightweight modules: a domain classifier to identify the input image type, and a dual adapter mechanism comprising a Prompt Adapter for language modulation and a Visual Adapter for vision feature adjustment. Both modules are dynamically injected via a unified hook interface, requiring no retraining of the backbone model. Experimental results across four domain-specific VQA benchmarks demonstrate that our framework achieves consistent performance gains without retraining the backbone model, including +2.3 BLEU on MathVQA, +2.6 VQA on MedVQA-RAD, and +3.1 ROUGE on ChartQA. These results highlight that CATCH provides a scalable and extensible approach to multi-domain VQA, enabling practical deployment across diverse application domains.
Rhyme-aware Chinese lyric generator based on GPT
Aug 19, 2024Neural language representation models such as GPT, pre-trained on large-scale corpora, can effectively capture rich semantic patterns from plain text and be fine-tuned to consistently improve natural language generation performance. However, existing pre-trained language models used to generate lyrics rarely consider rhyme information, which is crucial in lyrics. Using a pre-trained model directly results in poor performance. To enhance the rhyming quality of generated lyrics, we incorporate integrated rhyme information into our model, thereby improving lyric generation performance.
DVPE: Divided View Position Embedding for Multi-View 3D Object Detection
Jul 24, 2024
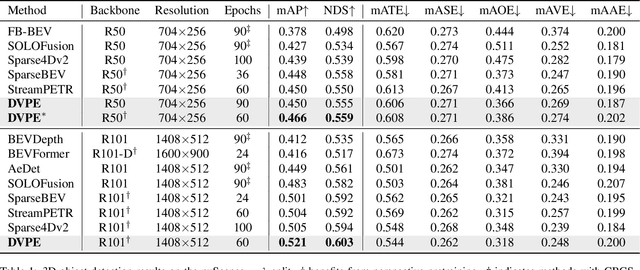
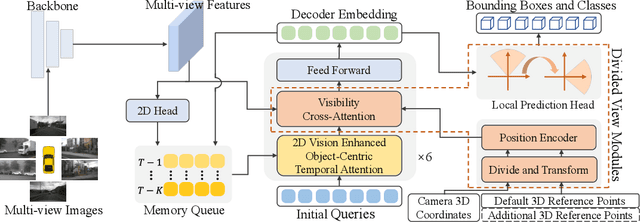
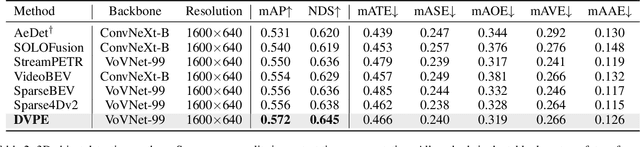
Sparse query-based paradigms have achieved significant success in multi-view 3D detection for autonomous vehicles. Current research faces challenges in balancing between enlarging receptive fields and reducing interference when aggregating multi-view features. Moreover, different poses of cameras present challenges in training global attention models. To address these problems, this paper proposes a divided view method, in which features are modeled globally via the visibility crossattention mechanism, but interact only with partial features in a divided local virtual space. This effectively reduces interference from other irrelevant features and alleviates the training difficulties of the transformer by decoupling the position embedding from camera poses. Additionally, 2D historical RoI features are incorporated into the object-centric temporal modeling to utilize highlevel visual semantic information. The model is trained using a one-to-many assignment strategy to facilitate stability. Our framework, named DVPE, achieves state-of-the-art performance (57.2% mAP and 64.5% NDS) on the nuScenes test set. Codes will be available at https://github.com/dop0/DVPE.
Research on the Application of Computer Vision Based on Deep Learning in Autonomous Driving Technology
Jun 04, 2024
This research aims to explore the application of deep learning in autonomous driving computer vision technology and its impact on improving system performance. By using advanced technologies such as convolutional neural networks (CNN), multi-task joint learning methods, and deep reinforcement learning, this article analyzes in detail the application of deep learning in image recognition, real-time target tracking and classification, environment perception and decision support, and path planning and navigation. Application process in key areas. Research results show that the proposed system has an accuracy of over 98% in image recognition, target tracking and classification, and also demonstrates efficient performance and practicality in environmental perception and decision support, path planning and navigation. The conclusion points out that deep learning technology can significantly improve the accuracy and real-time response capabilities of autonomous driving systems. Although there are still challenges in environmental perception and decision support, with the advancement of technology, it is expected to achieve wider applications and greater capabilities in the future. potential.
Mapping New Realities: Ground Truth Image Creation with Pix2Pix Image-to-Image Translation
May 01, 2024


Generative Adversarial Networks (GANs) have significantly advanced image processing, with Pix2Pix being a notable framework for image-to-image translation. This paper explores a novel application of Pix2Pix to transform abstract map images into realistic ground truth images, addressing the scarcity of such images crucial for domains like urban planning and autonomous vehicle training. We detail the Pix2Pix model's utilization for generating high-fidelity datasets, supported by a dataset of paired map and aerial images, and enhanced by a tailored training regimen. The results demonstrate the model's capability to accurately render complex urban features, establishing its efficacy and potential for broad real-world applications.
Feature Manipulation for DDPM based Change Detection
Mar 23, 2024Change Detection is a classic task of computer vision that receives a bi-temporal image pair as input and separates the semantically changed and unchanged regions of it. The diffusion model is used in image synthesis and as a feature extractor and has been applied to various downstream tasks. Using this, a feature map is extracted from the pre-trained diffusion model from the large-scale data set, and changes are detected through the additional network. On the one hand, the current diffusion-based change detection approach focuses only on extracting a good feature map using the diffusion model. It obtains and uses differences without further adjustment to the created feature map. Our method focuses on manipulating the feature map extracted from the Diffusion Model to be more semantically useful, and for this, we propose two methods: Feature Attention and FDAF. Our model with Feature Attention achieved a state-of-the-art F1 score (90.18) and IoU (83.86) on the LEVIR-CD dataset.
Comprehensive evaluation of Mal-API-2019 dataset by machine learning in malware detection
Mar 04, 2024
This study conducts a thorough examination of malware detection using machine learning techniques, focusing on the evaluation of various classification models using the Mal-API-2019 dataset. The aim is to advance cybersecurity capabilities by identifying and mitigating threats more effectively. Both ensemble and non-ensemble machine learning methods, such as Random Forest, XGBoost, K Nearest Neighbor (KNN), and Neural Networks, are explored. Special emphasis is placed on the importance of data pre-processing techniques, particularly TF-IDF representation and Principal Component Analysis, in improving model performance. Results indicate that ensemble methods, particularly Random Forest and XGBoost, exhibit superior accuracy, precision, and recall compared to others, highlighting their effectiveness in malware detection. The paper also discusses limitations and potential future directions, emphasizing the need for continuous adaptation to address the evolving nature of malware. This research contributes to ongoing discussions in cybersecurity and provides practical insights for developing more robust malware detection systems in the digital era.
Open-World Object Detection via Discriminative Class Prototype Learning
Feb 23, 2023



Open-world object detection (OWOD) is a challenging problem that combines object detection with incremental learning and open-set learning. Compared to standard object detection, the OWOD setting is task to: 1) detect objects seen during training while identifying unseen classes, and 2) incrementally learn the knowledge of the identified unknown objects when the corresponding annotations is available. We propose a novel and efficient OWOD solution from a prototype perspective, which we call OCPL: Open-world object detection via discriminative Class Prototype Learning, which consists of a Proposal Embedding Aggregator (PEA), an Embedding Space Compressor (ESC) and a Cosine Similarity-based Classifier (CSC). All our proposed modules aim to learn the discriminative embeddings of known classes in the feature space to minimize the overlapping distributions of known and unknown classes, which is beneficial to differentiate known and unknown classes. Extensive experiments performed on PASCAL VOC and MS-COCO benchmark demonstrate the effectiveness of our proposed method.
* 4 pages, 3 figures, ICIP2022
Automated Movement Detection with Dirichlet Process Mixture Models and Electromyography
Feb 15, 2023
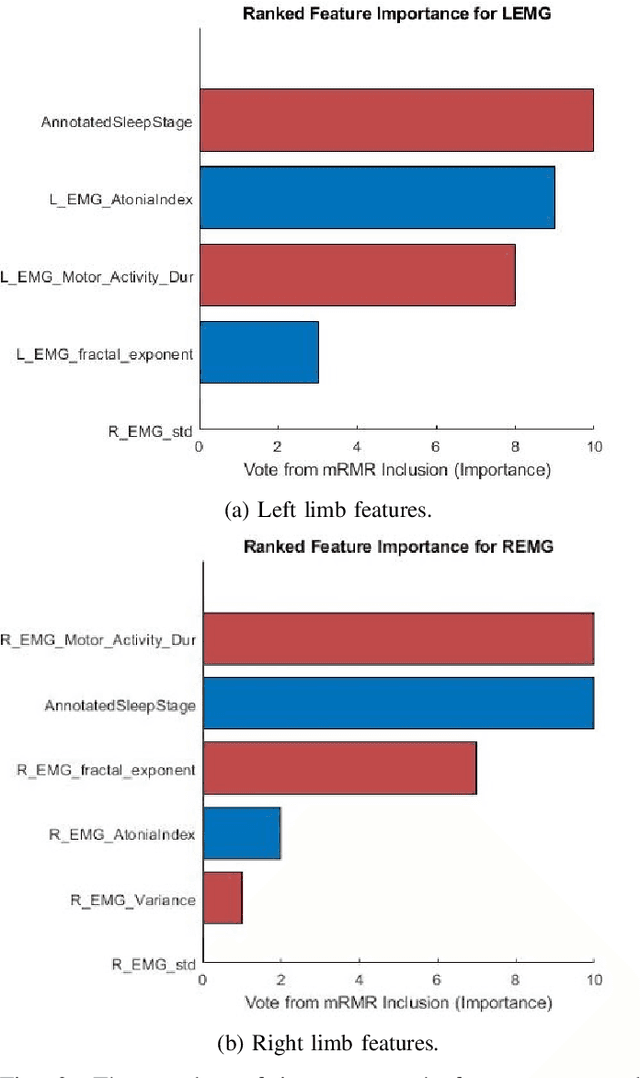
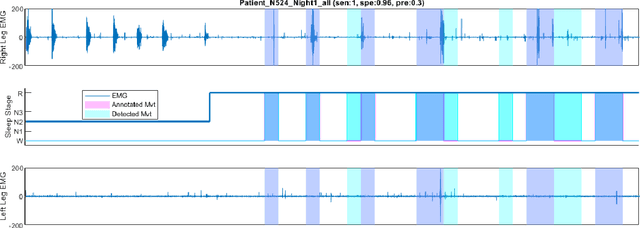

Numerous sleep disorders are characterised by movement during sleep, these include rapid-eye movement sleep behaviour disorder (RBD) and periodic limb movement disorder. The process of diagnosing movement related sleep disorders requires laborious and time-consuming visual analysis of sleep recordings. This process involves sleep clinicians visually inspecting electromyogram (EMG) signals to identify abnormal movements. The distribution of characteristics that represent movement can be diverse and varied, ranging from brief moments of tensing to violent outbursts. This study proposes a framework for automated limb-movement detection by fusing data from two EMG sensors (from the left and right limb) through a Dirichlet process mixture model. Several features are extracted from 10 second mini-epochs, where each mini-epoch has been classified as 'leg-movement' or 'no leg-movement' based on annotations of movement from sleep clinicians. The distributions of the features from each category can be estimated accurately using Gaussian mixture models with the Dirichlet process as a prior. The available dataset includes 36 participants that have all been diagnosed with RBD. The performance of this framework was evaluated by a 10-fold cross validation scheme (participant independent). The study was compared to a random forest model and outperformed it with a mean accuracy, sensitivity, and specificity of 94\%, 48\%, and 95\%, respectively. These results demonstrate the ability of this framework to automate the detection of limb movement for the potential application of assisting clinical diagnosis and decision-making.