 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamVLA: Breaking the Reason-Act Cycle via Completion-State Gating
Feb 01, 2026Long-horizon robotic manipulation requires bridging the gap between high-level planning (System 2) and low-level control (System 1). Current Vision-Language-Action (VLA) models often entangle these processes, performing redundant multimodal reasoning at every timestep, which leads to high latency and goal instability. To address this, we present StreamVLA, a dual-system architecture that unifies textual task decomposition, visual goal imagination, and continuous action generation within a single parameter-efficient backbone. We introduce a "Lock-and-Gated" mechanism to intelligently modulate computation: only when a sub-task transition is detected, the model triggers slow thinking to generate a textual instruction and imagines the specific visual completion state, rather than generic future frames. Crucially, this completion state serves as a time-invariant goal anchor, making the policy robust to execution speed variations. During steady execution, these high-level intents are locked to condition a Flow Matching action head, allowing the model to bypass expensive autoregressive decoding for 72% of timesteps. This hierarchical abstraction ensures sub-goal focus while significantly reducing inference latency. Extensive evaluations demonstrate that StreamVLA achieves state-of-the-art performance, with a 98.5% success rate on the LIBERO benchmark and robust recovery in real-world interference scenarios, achieving a 48% reduction in latency compared to full-reasoning baselines.
DVPE: Divided View Position Embedding for Multi-View 3D Object Detection
Jul 24, 2024
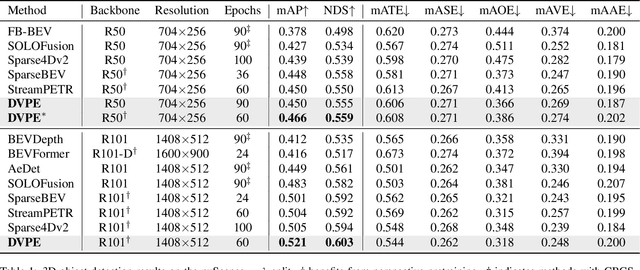
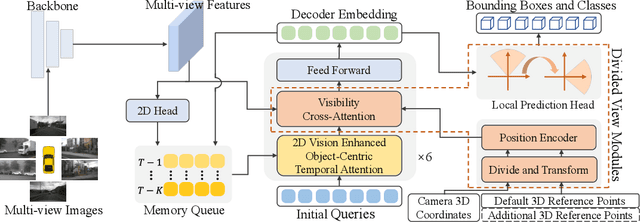
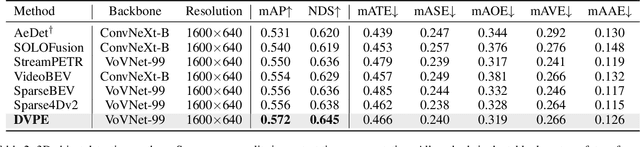
Sparse query-based paradigms have achieved significant success in multi-view 3D detection for autonomous vehicles. Current research faces challenges in balancing between enlarging receptive fields and reducing interference when aggregating multi-view features. Moreover, different poses of cameras present challenges in training global attention models. To address these problems, this paper proposes a divided view method, in which features are modeled globally via the visibility crossattention mechanism, but interact only with partial features in a divided local virtual space. This effectively reduces interference from other irrelevant features and alleviates the training difficulties of the transformer by decoupling the position embedding from camera poses. Additionally, 2D historical RoI features are incorporated into the object-centric temporal modeling to utilize highlevel visual semantic information. The model is trained using a one-to-many assignment strategy to facilitate stability. Our framework, named DVPE, achieves state-of-the-art performance (57.2% mAP and 64.5% NDS) on the nuScenes test set. Codes will be available at https://github.com/dop0/DVPE.