 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamVLA: Breaking the Reason-Act Cycle via Completion-State Gating
Feb 01, 2026Long-horizon robotic manipulation requires bridging the gap between high-level planning (System 2) and low-level control (System 1). Current Vision-Language-Action (VLA) models often entangle these processes, performing redundant multimodal reasoning at every timestep, which leads to high latency and goal instability. To address this, we present StreamVLA, a dual-system architecture that unifies textual task decomposition, visual goal imagination, and continuous action generation within a single parameter-efficient backbone. We introduce a "Lock-and-Gated" mechanism to intelligently modulate computation: only when a sub-task transition is detected, the model triggers slow thinking to generate a textual instruction and imagines the specific visual completion state, rather than generic future frames. Crucially, this completion state serves as a time-invariant goal anchor, making the policy robust to execution speed variations. During steady execution, these high-level intents are locked to condition a Flow Matching action head, allowing the model to bypass expensive autoregressive decoding for 72% of timesteps. This hierarchical abstraction ensures sub-goal focus while significantly reducing inference latency. Extensive evaluations demonstrate that StreamVLA achieves state-of-the-art performance, with a 98.5% success rate on the LIBERO benchmark and robust recovery in real-world interference scenarios, achieving a 48% reduction in latency compared to full-reasoning baselines.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
SparseFormer: Detecting Objects in HRW Shots via Sparse Vision Transformer
Feb 11, 2025Recent years have seen an increase in the use of gigapixel-level image and video capture systems and benchmarks with high-resolution wide (HRW) shots. However, unlike close-up shots in the MS COCO dataset, the higher resolution and wider field of view raise unique challenges, such as extreme sparsity and huge scale changes, causing existing close-up detectors inaccuracy and inefficiency. In this paper, we present a novel model-agnostic sparse vision transformer, dubbed SparseFormer, to bridge the gap of object detection between close-up and HRW shots. The proposed SparseFormer selectively uses attentive tokens to scrutinize the sparsely distributed windows that may contain objects. In this way, it can jointly explore global and local attention by fusing coarse- and fine-grained features to handle huge scale changes. SparseFormer also benefits from a novel Cross-slice non-maximum suppression (C-NMS) algorithm to precisely localize objects from noisy windows and a simple yet effective multi-scale strategy to improve accuracy. Extensive experiments on two HRW benchmarks, PANDA and DOTA-v1.0, demonstrate that the proposed SparseFormer significantly improves detection accuracy (up to 5.8%) and speed (up to 3x) over the state-of-the-art approaches.
Corner2Net: Detecting Objects as Cascade Corners
Nov 24, 2024



The corner-based detection paradigm enjoys the potential to produce high-quality boxes. But the development is constrained by three factors: 1) Hard to match corners. Heuristic corner matching algorithms can lead to incorrect boxes, especially when similar-looking objects co-occur. 2) Poor instance context. Two separate corners preserve few instance semantics, so it is difficult to guarantee getting both two class-specific corners on the same heatmap channel. 3) Unfriendly backbone. The training cost of the hourglass network is high. Accordingly, we build a novel corner-based framework, named Corner2Net. To achieve the corner-matching-free manner, we devise the cascade corner pipeline which progressively predicts the associated corner pair in two steps instead of synchronously searching two independent corners via parallel heads. Corner2Net decouples corner localization and object classification. Both two corners are class-agnostic and the instance-specific bottom-right corner further simplifies its search space. Meanwhile, RoI features with rich semantics are extracted for classification. Popular backbones (e.g., ResNeXt) can be easily connected to Corner2Net. Experimental results on COCO show Corner2Net surpasses all existing corner-based detectors by a large margin in accuracy and speed.
* This paper is accepted by 27th EUROPEAN CONFERENCE ON ARTIFICIAL INTELLIGENCE (ECAI 2024)
DynamicTrack: Advancing Gigapixel Tracking in Crowded Scenes
Jul 26, 2024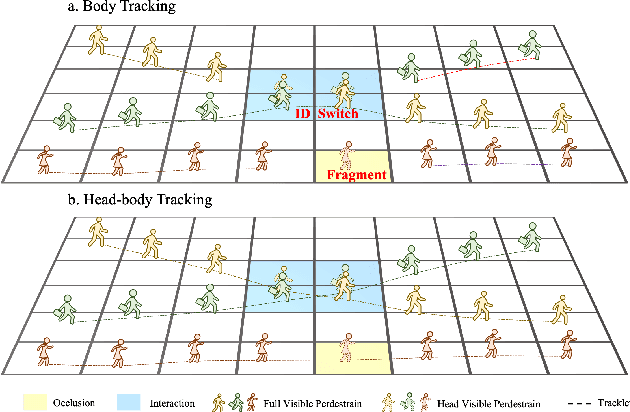
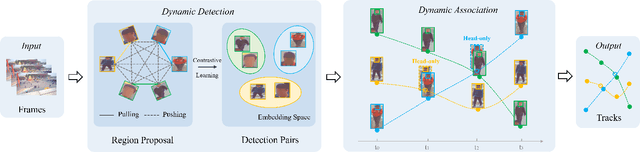
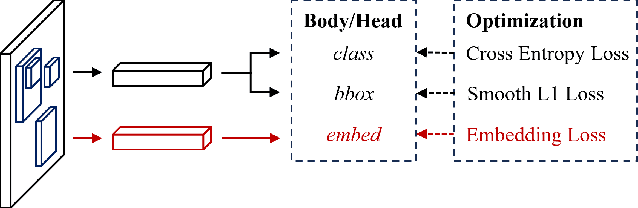

Tracking in gigapixel scenarios holds numerous potential applications in video surveillance and pedestrian analysis. Existing algorithms attempt to perform tracking in crowded scenes by utilizing multiple cameras or group relationships. However, their performance significantly degrades when confronted with complex interaction and occlusion inherent in gigapixel images. In this paper, we introduce DynamicTrack, a dynamic tracking framework designed to address gigapixel tracking challenges in crowded scenes. In particular, we propose a dynamic detector that utilizes contrastive learning to jointly detect the head and body of pedestrians. Building upon this, we design a dynamic association algorithm that effectively utilizes head and body information for matching purposes. Extensive experiments show that our tracker achieves state-of-the-art performance on widely used tracking benchmarks specifically designed for gigapixel crowded scenes.
XScale-NVS: Cross-Scale Novel View Synthesis with Hash Featurized Manifold
Mar 28, 2024We propose XScale-NVS for high-fidelity cross-scale novel view synthesis of real-world large-scale scenes. Existing representations based on explicit surface suffer from discretization resolution or UV distortion, while implicit volumetric representations lack scalability for large scenes due to the dispersed weight distribution and surface ambiguity. In light of the above challenges, we introduce hash featurized manifold, a novel hash-based featurization coupled with a deferred neural rendering framework. This approach fully unlocks the expressivity of the representation by explicitly concentrating the hash entries on the 2D manifold, thus effectively representing highly detailed contents independent of the discretization resolution. We also introduce a novel dataset, namely GigaNVS, to benchmark cross-scale, high-resolution novel view synthesis of realworld large-scale scenes. Our method significantly outperforms competing baselines on various real-world scenes, yielding an average LPIPS that is 40% lower than prior state-of-the-art on the challenging GigaNVS benchmark. Please see our project page at: xscalenvs.github.io.
Den-SOFT: Dense Space-Oriented Light Field DataseT for 6-DOF Immersive Experience
Mar 15, 2024



We have built a custom mobile multi-camera large-space dense light field capture system, which provides a series of high-quality and sufficiently dense light field images for various scenarios. Our aim is to contribute to the development of popular 3D scene reconstruction algorithms such as IBRnet, NeRF, and 3D Gaussian splitting. More importantly, the collected dataset, which is much denser than existing datasets, may also inspire space-oriented light field reconstruction, which is potentially different from object-centric 3D reconstruction, for immersive VR/AR experiences. We utilized a total of 40 GoPro 10 cameras, capturing images of 5k resolution. The number of photos captured for each scene is no less than 1000, and the average density (view number within a unit sphere) is 134.68. It is also worth noting that our system is capable of efficiently capturing large outdoor scenes. Addressing the current lack of large-space and dense light field datasets, we made efforts to include elements such as sky, reflections, lights and shadows that are of interest to researchers in the field of 3D reconstruction during the data capture process. Finally, we validated the effectiveness of our provided dataset on three popular algorithms and also integrated the reconstructed 3DGS results into the Unity engine, demonstrating the potential of utilizing our datasets to enhance the realism of virtual reality (VR) and create feasible interactive spaces. The dataset is available at our project website.
OmniSeg3D: Omniversal 3D Segmentation via Hierarchical Contrastive Learning
Nov 20, 2023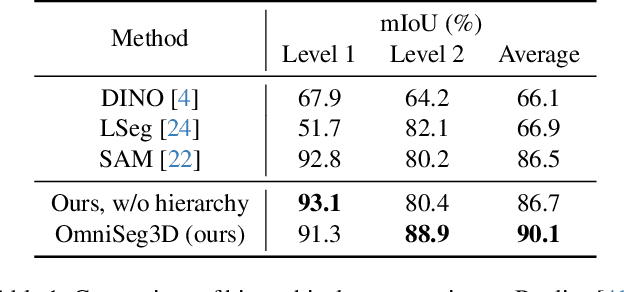
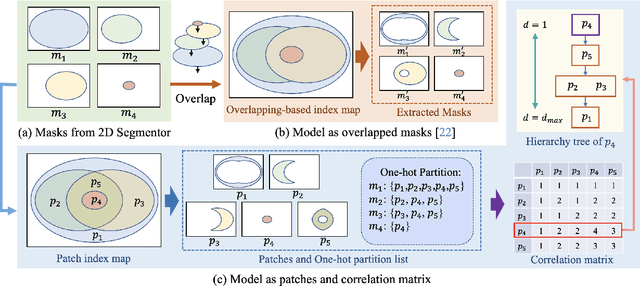
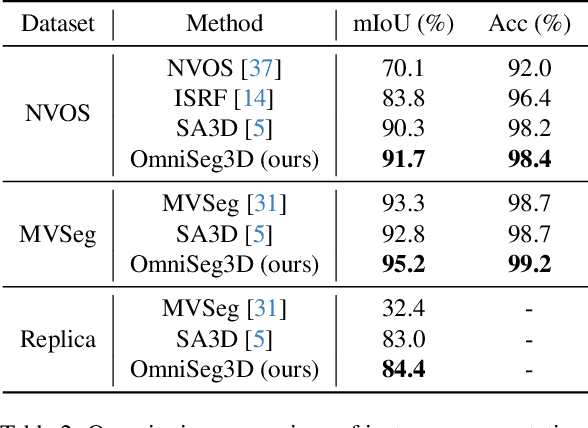
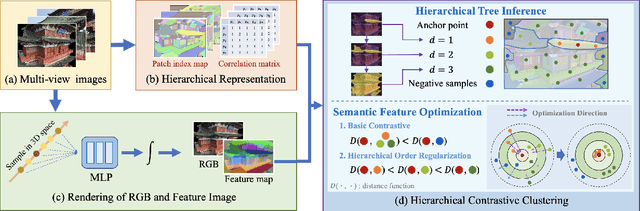
Towards holistic understanding of 3D scenes, a general 3D segmentation method is needed that can segment diverse objects without restrictions on object quantity or categories, while also reflecting the inherent hierarchical structure. To achieve this, we propose OmniSeg3D, an omniversal segmentation method aims for segmenting anything in 3D all at once. The key insight is to lift multi-view inconsistent 2D segmentations into a consistent 3D feature field through a hierarchical contrastive learning framework, which is accomplished by two steps. Firstly, we design a novel hierarchical representation based on category-agnostic 2D segmentations to model the multi-level relationship among pixels. Secondly, image features rendered from the 3D feature field are clustered at different levels, which can be further drawn closer or pushed apart according to the hierarchical relationship between different levels. In tackling the challenges posed by inconsistent 2D segmentations, this framework yields a global consistent 3D feature field, which further enables hierarchical segmentation, multi-object selection, and global discretization. Extensive experiments demonstrate the effectiveness of our method on high-quality 3D segmentation and accurate hierarchical structure understanding. A graphical user interface further facilitates flexible interaction for omniversal 3D segmentation.
PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis
Sep 29, 2023This paper proposes a method for fast scene radiance field reconstruction with strong novel view synthesis performance and convenient scene editing functionality. The key idea is to fully utilize semantic parsing and primitive extraction for constraining and accelerating the radiance field reconstruction process. To fulfill this goal, a primitive-aware hybrid rendering strategy was proposed to enjoy the best of both volumetric and primitive rendering. We further contribute a reconstruction pipeline conducts primitive parsing and radiance field learning iteratively for each input frame which successfully fuses semantic, primitive, and radiance information into a single framework. Extensive evaluations demonstrate the fast reconstruction ability, high rendering quality, and convenient editing functionality of our method.