 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper detection limits in astronomical imaging using self-supervised spatiotemporal denoising
Feb 19, 2026The detection limit of astronomical imaging observations is limited by several noise sources. Some of that noise is correlated between neighbouring image pixels and exposures, so in principle could be learned and corrected. We present an astronomical self-supervised transformer-based denoising algorithm (ASTERIS), that integrates spatiotemporal information across multiple exposures. Benchmarking on mock data indicates that ASTERIS improves detection limits by 1.0 magnitude at 90% completeness and purity, while preserving the point spread function and photometric accuracy. Observational validation using data from the James Webb Space Telescope (JWST) and Subaru telescope identifies previously undetectable features, including low-surface-brightness galaxy structures and gravitationally-lensed arcs. Applied to deep JWST images, ASTERIS identifies three times more redshift > 9 galaxy candidates, with rest-frame ultraviolet luminosity 1.0 magnitude fainter, than previous methods.
A Survey: Learning Embodied Intelligence from Physical Simulators and World Models
Jul 01, 2025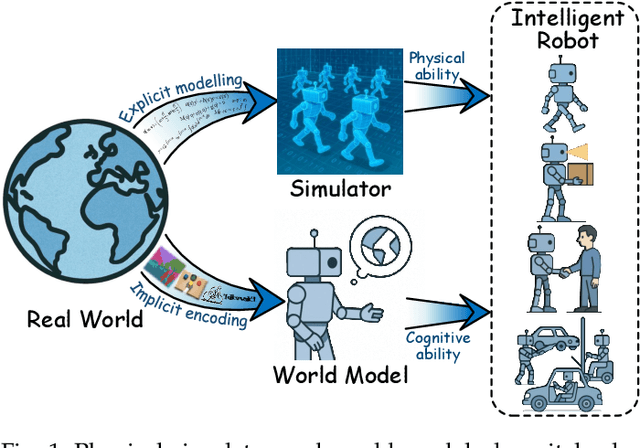
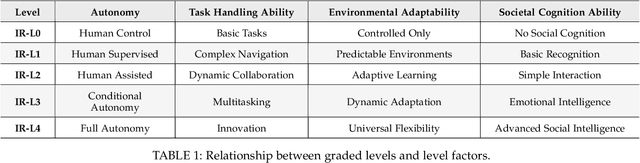
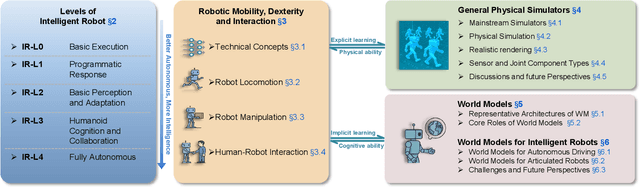

The pursuit of artificial general intelligence (AGI) has placed embodied intelligence at the forefront of robotics research. Embodied intelligence focuses on agents capable of perceiving, reasoning, and acting within the physical world. Achieving robust embodied intelligence requires not only advanced perception and control, but also the ability to ground abstract cognition in real-world interactions. Two foundational technologies, physical simulators and world models, have emerged as critical enablers in this quest. Physical simulators provide controlled, high-fidelity environments for training and evaluating robotic agents, allowing safe and efficient development of complex behaviors. In contrast, world models empower robots with internal representations of their surroundings, enabling predictive planning and adaptive decision-making beyond direct sensory input. This survey systematically reviews recent advances in learning embodied AI through the integration of physical simulators and world models. We analyze their complementary roles in enhancing autonomy, adaptability, and generalization in intelligent robots, and discuss the interplay between external simulation and internal modeling in bridging the gap between simulated training and real-world deployment. By synthesizing current progress and identifying open challenges, this survey aims to provide a comprehensive perspective on the path toward more capable and generalizable embodied AI systems. We also maintain an active repository that contains up-to-date literature and open-source projects at https://github.com/NJU3DV-LoongGroup/Embodied-World-Models-Survey.
ELGAR: Expressive Cello Performance Motion Generation for Audio Rendition
May 07, 2025The art of instrument performance stands as a vivid manifestation of human creativity and emotion. Nonetheless, generating instrument performance motions is a highly challenging task, as it requires not only capturing intricate movements but also reconstructing the complex dynamics of the performer-instrument interaction. While existing works primarily focus on modeling partial body motions, we propose Expressive ceLlo performance motion Generation for Audio Rendition (ELGAR), a state-of-the-art diffusion-based framework for whole-body fine-grained instrument performance motion generation solely from audio. To emphasize the interactive nature of the instrument performance, we introduce Hand Interactive Contact Loss (HICL) and Bow Interactive Contact Loss (BICL), which effectively guarantee the authenticity of the interplay. Moreover, to better evaluate whether the generated motions align with the semantic context of the music audio, we design novel metrics specifically for string instrument performance motion generation, including finger-contact distance, bow-string distance, and bowing score. Extensive evaluations and ablation studies are conducted to validate the efficacy of the proposed methods. In addition, we put forward a motion generation dataset SPD-GEN, collated and normalized from the MoCap dataset SPD. As demonstrated, ELGAR has shown great potential in generating instrument performance motions with complicated and fast interactions, which will promote further development in areas such as animation, music education, interactive art creation, etc.
GBR: Generative Bundle Refinement for High-fidelity Gaussian Splatting and Meshing
Dec 08, 2024



Gaussian splatting has gained attention for its efficient representation and rendering of 3D scenes using continuous Gaussian primitives. However, it struggles with sparse-view inputs due to limited geometric and photometric information, causing ambiguities in depth, shape, and texture. we propose GBR: Generative Bundle Refinement, a method for high-fidelity Gaussian splatting and meshing using only 4-6 input views. GBR integrates a neural bundle adjustment module to enhance geometry accuracy and a generative depth refinement module to improve geometry fidelity. More specifically, the neural bundle adjustment module integrates a foundation network to produce initial 3D point maps and point matches from unposed images, followed by bundle adjustment optimization to improve multiview consistency and point cloud accuracy. The generative depth refinement module employs a diffusion-based strategy to enhance geometric details and fidelity while preserving the scale. Finally, for Gaussian splatting optimization, we propose a multimodal loss function incorporating depth and normal consistency, geometric regularization, and pseudo-view supervision, providing robust guidance under sparse-view conditions. Experiments on widely used datasets show that GBR significantly outperforms existing methods under sparse-view inputs. Additionally, GBR demonstrates the ability to reconstruct and render large-scale real-world scenes, such as the Pavilion of Prince Teng and the Great Wall, with remarkable details using only 6 views.
UniCompress: Enhancing Multi-Data Medical Image Compression with Knowledge Distillation
May 27, 2024In the field of medical image compression, Implicit Neural Representation (INR) networks have shown remarkable versatility due to their flexible compression ratios, yet they are constrained by a one-to-one fitting approach that results in lengthy encoding times. Our novel method, ``\textbf{UniCompress}'', innovatively extends the compression capabilities of INR by being the first to compress multiple medical data blocks using a single INR network. By employing wavelet transforms and quantization, we introduce a codebook containing frequency domain information as a prior input to the INR network. This enhances the representational power of INR and provides distinctive conditioning for different image blocks. Furthermore, our research introduces a new technique for the knowledge distillation of implicit representations, simplifying complex model knowledge into more manageable formats to improve compression ratios. Extensive testing on CT and electron microscopy (EM) datasets has demonstrated that UniCompress outperforms traditional INR methods and commercial compression solutions like HEVC, especially in complex and high compression scenarios. Notably, compared to existing INR techniques, UniCompress achieves a 4$\sim$5 times increase in compression speed, marking a significant advancement in the field of medical image compression. Codes will be publicly available.
Event-Enhanced Snapshot Compressive Videography at 10K FPS
Apr 11, 2024Video snapshot compressive imaging (SCI) encodes the target dynamic scene compactly into a snapshot and reconstructs its high-speed frame sequence afterward, greatly reducing the required data footprint and transmission bandwidth as well as enabling high-speed imaging with a low frame rate intensity camera. In implementation, high-speed dynamics are encoded via temporally varying patterns, and only frames at corresponding temporal intervals can be reconstructed, while the dynamics occurring between consecutive frames are lost. To unlock the potential of conventional snapshot compressive videography, we propose a novel hybrid "intensity+event" imaging scheme by incorporating an event camera into a video SCI setup. Our proposed system consists of a dual-path optical setup to record the coded intensity measurement and intermediate event signals simultaneously, which is compact and photon-efficient by collecting the half photons discarded in conventional video SCI. Correspondingly, we developed a dual-branch Transformer utilizing the reciprocal relationship between two data modes to decode dense video frames. Extensive experiments on both simulated and real-captured data demonstrate our superiority to state-of-the-art video SCI and video frame interpolation (VFI) methods. Benefiting from the new hybrid design leveraging both intrinsic redundancy in videos and the unique feature of event cameras, we achieve high-quality videography at 0.1ms time intervals with a low-cost CMOS image sensor working at 24 FPS.
Context-aware Talking Face Video Generation
Feb 28, 2024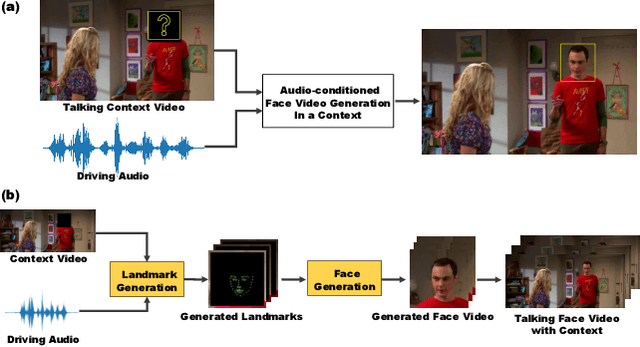
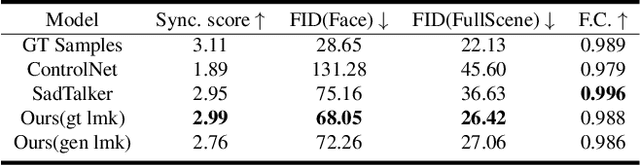
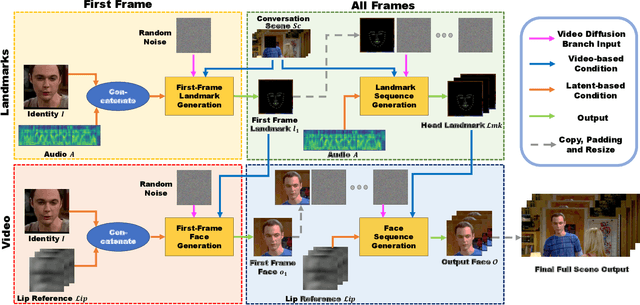
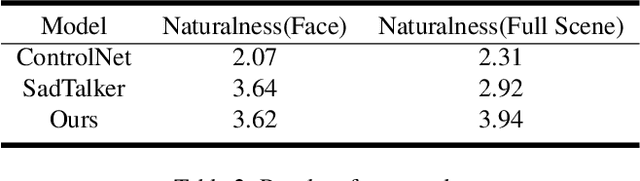
In this paper, we consider a novel and practical case for talking face video generation. Specifically, we focus on the scenarios involving multi-people interactions, where the talking context, such as audience or surroundings, is present. In these situations, the video generation should take the context into consideration in order to generate video content naturally aligned with driving audios and spatially coherent to the context. To achieve this, we provide a two-stage and cross-modal controllable video generation pipeline, taking facial landmarks as an explicit and compact control signal to bridge the driving audio, talking context and generated videos. Inside this pipeline, we devise a 3D video diffusion model, allowing for efficient contort of both spatial conditions (landmarks and context video), as well as audio condition for temporally coherent generation. The experimental results verify the advantage of the proposed method over other baselines in terms of audio-video synchronization, video fidelity and frame consistency.
An Event-Oriented Diffusion-Refinement Method for Sparse Events Completion
Jan 06, 2024Event cameras or dynamic vision sensors (DVS) record asynchronous response to brightness changes instead of conventional intensity frames, and feature ultra-high sensitivity at low bandwidth. The new mechanism demonstrates great advantages in challenging scenarios with fast motion and large dynamic range. However, the recorded events might be highly sparse due to either limited hardware bandwidth or extreme photon starvation in harsh environments. To unlock the full potential of event cameras, we propose an inventive event sequence completion approach conforming to the unique characteristics of event data in both the processing stage and the output form. Specifically, we treat event streams as 3D event clouds in the spatiotemporal domain, develop a diffusion-based generative model to generate dense clouds in a coarse-to-fine manner, and recover exact timestamps to maintain the temporal resolution of raw data successfully. To validate the effectiveness of our method comprehensively, we perform extensive experiments on three widely used public datasets with different spatial resolutions, and additionally collect a novel event dataset covering diverse scenarios with highly dynamic motions and under harsh illumination. Besides generating high-quality dense events, our method can benefit downstream applications such as object classification and intensity frame reconstruction.
Lightweight High-Speed Photography Built on Coded Exposure and Implicit Neural Representation of Videos
Nov 22, 2023The compact cameras recording high-speed scenes with high resolution are highly demanded, but the required high bandwidth often leads to bulky, heavy systems, which limits their applications on low-capacity platforms. Adopting a coded exposure setup to encode a frame sequence into a blurry snapshot and retrieve the latent sharp video afterward can serve as a lightweight solution. However, restoring motion from blur is quite challenging due to the high ill-posedness of motion blur decomposition, intrinsic ambiguity in motion direction, and diverse motions in natural videos. In this work, by leveraging classical coded exposure imaging technique and emerging implicit neural representation for videos, we tactfully embed the motion direction cues into the blurry image during the imaging process and develop a novel self-recursive neural network to sequentially retrieve the latent video sequence from the blurry image utilizing the embedded motion direction cues. To validate the effectiveness and efficiency of the proposed framework, we conduct extensive experiments on benchmark datasets and real-captured blurry images. The results demonstrate that our proposed framework significantly outperforms existing methods in quality and flexibility. The code for our work is available at https://github.com/zhihongz/BDINR
PARF: Primitive-Aware Radiance Fusion for Indoor Scene Novel View Synthesis
Sep 29, 2023This paper proposes a method for fast scene radiance field reconstruction with strong novel view synthesis performance and convenient scene editing functionality. The key idea is to fully utilize semantic parsing and primitive extraction for constraining and accelerating the radiance field reconstruction process. To fulfill this goal, a primitive-aware hybrid rendering strategy was proposed to enjoy the best of both volumetric and primitive rendering. We further contribute a reconstruction pipeline conducts primitive parsing and radiance field learning iteratively for each input frame which successfully fuses semantic, primitive, and radiance information into a single framework. Extensive evaluations demonstrate the fast reconstruction ability, high rendering quality, and convenient editing functionality of our method.