 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurGSplat: Progressive Geometry-Constrained Gaussian Splatting for Surgical Scene Reconstruction
Jun 06, 2025Intraoperative navigation relies heavily on precise 3D reconstruction to ensure accuracy and safety during surgical procedures. However, endoscopic scenarios present unique challenges, including sparse features and inconsistent lighting, which render many existing Structure-from-Motion (SfM)-based methods inadequate and prone to reconstruction failure. To mitigate these constraints, we propose SurGSplat, a novel paradigm designed to progressively refine 3D Gaussian Splatting (3DGS) through the integration of geometric constraints. By enabling the detailed reconstruction of vascular structures and other critical features, SurGSplat provides surgeons with enhanced visual clarity, facilitating precise intraoperative decision-making. Experimental evaluations demonstrate that SurGSplat achieves superior performance in both novel view synthesis (NVS) and pose estimation accuracy, establishing it as a high-fidelity and efficient solution for surgical scene reconstruction. More information and results can be found on the page https://surgsplat.github.io/.
DPZV: Resource Efficient ZO Optimization For Differentially Private VFL
Feb 27, 2025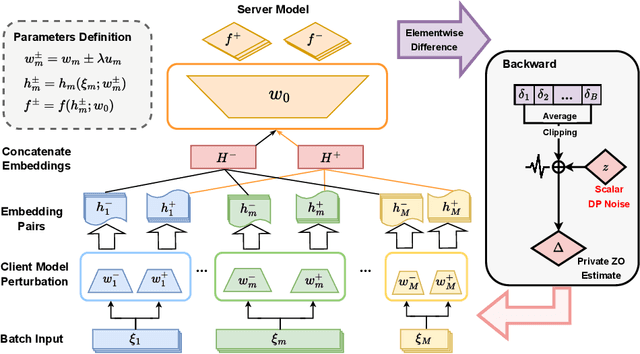

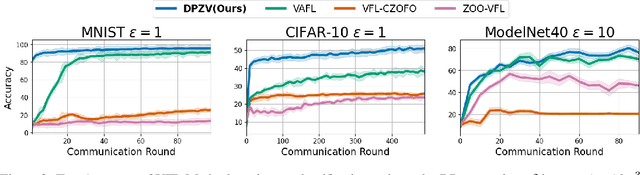
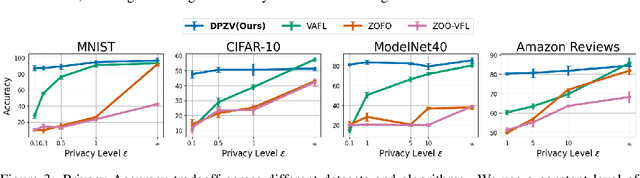
Vertical Federated Learning (VFL) enables collaborative model training across feature-partitioned data, yet faces significant privacy risks and inefficiencies when scaling to large models. We propose DPZV, a memory-efficient Zeroth-Order(ZO) optimization framework that integrates differential privacy (DP) with vertical federated learning, addressing three critical challenges: (1) privacy vulnerabilities from gradient leakage, (2) high computation/communication costs of first-order methods, and (3) excessive memory footprint in conventional zeroth-order approaches. Our framework eliminates backpropagation through two-point gradient estimation, reducing client memory usage by 90\% compared to first-order counterparts while enabling asynchronous communication. By strategically injecting Gaussian noise on the server, DPZV achieves rigorous $(\epsilon, \delta)$-DP guarantees without third-party trust assumptions. Theoretical analysis establishes a convergence rate matching centralized case under non-convex objectives. Extensive experiments on image and NLP benchmarks demonstrate that DPZV outperforms all baselines in accuracy while providing strong privacy assurances ($\epsilon \leq 10$) and requiring far fewer computation resources, establishing new state-of-the-art privacy-utility tradeoffs for resource-constrained VFL deployments.
GBR: Generative Bundle Refinement for High-fidelity Gaussian Splatting and Meshing
Dec 08, 2024



Gaussian splatting has gained attention for its efficient representation and rendering of 3D scenes using continuous Gaussian primitives. However, it struggles with sparse-view inputs due to limited geometric and photometric information, causing ambiguities in depth, shape, and texture. we propose GBR: Generative Bundle Refinement, a method for high-fidelity Gaussian splatting and meshing using only 4-6 input views. GBR integrates a neural bundle adjustment module to enhance geometry accuracy and a generative depth refinement module to improve geometry fidelity. More specifically, the neural bundle adjustment module integrates a foundation network to produce initial 3D point maps and point matches from unposed images, followed by bundle adjustment optimization to improve multiview consistency and point cloud accuracy. The generative depth refinement module employs a diffusion-based strategy to enhance geometric details and fidelity while preserving the scale. Finally, for Gaussian splatting optimization, we propose a multimodal loss function incorporating depth and normal consistency, geometric regularization, and pseudo-view supervision, providing robust guidance under sparse-view conditions. Experiments on widely used datasets show that GBR significantly outperforms existing methods under sparse-view inputs. Additionally, GBR demonstrates the ability to reconstruct and render large-scale real-world scenes, such as the Pavilion of Prince Teng and the Great Wall, with remarkable details using only 6 views.
LEAD: LiDAR Extender for Autonomous Driving
Feb 16, 2021
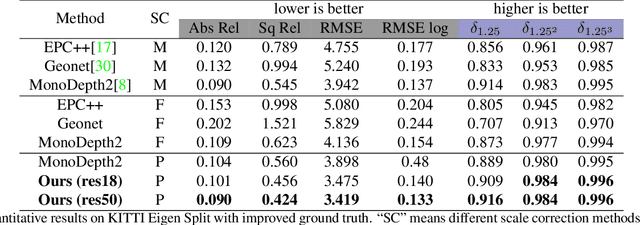
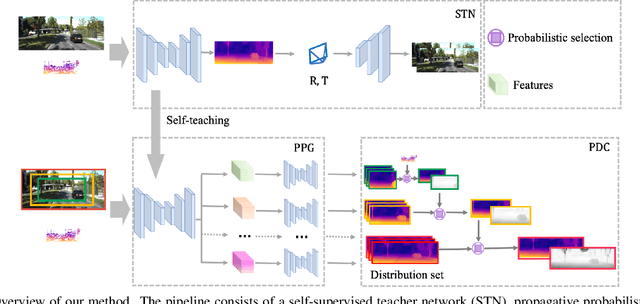
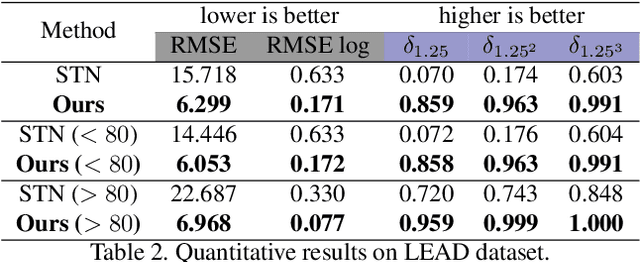
3D perception using sensors under vehicle industrial standard is the rigid demand in autonomous driving. MEMS LiDAR emerges with irresistible trend due to its lower cost, more robust, and meeting the mass-production standards. However, it suffers small field of view (FoV), slowing down the step of its population. In this paper, we propose LEAD, i.e., LiDAR Extender for Autonomous Driving, to extend the MEMS LiDAR by coupled image w.r.t both FoV and range. We propose a multi-stage propagation strategy based on depth distributions and uncertainty map, which shows effective propagation ability. Moreover, our depth outpainting/propagation network follows a teacher-student training fashion, which transfers depth estimation ability to depth completion network without any scale error passed. To validate the LiDAR extension quality, we utilize a high-precise laser scanner to generate a ground-truth dataset. Quantitative and qualitative evaluations show that our scheme outperforms SOTAs with a large margin. We believe the proposed LEAD along with the dataset would benefit the community w.r.t depth researches.