 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShareVerse: Multi-Agent Consistent Video Generation for Shared World Modeling
Mar 03, 2026This paper presents ShareVerse, a video generation framework enabling multi-agent shared world modeling, addressing the gap in existing works that lack support for unified shared world construction with multi-agent interaction. ShareVerse leverages the generation capability of large video models and integrates three key innovations: 1) A dataset for large-scale multi-agent interactive world modeling is built on the CARLA simulation platform, featuring diverse scenes, weather conditions, and interactive trajectories with paired multi-view videos (front/ rear/ left/ right views per agent) and camera data. 2) We propose a spatial concatenation strategy for four-view videos of independent agents to model a broader environment and to ensure internal multi-view geometric consistency. 3) We integrate cross-agent attention blocks into the pretrained video model, which enable interactive transmission of spatial-temporal information across agents, guaranteeing shared world consistency in overlapping regions and reasonable generation in non-overlapping regions. ShareVerse, which supports 49-frame large-scale video generation, accurately perceives the position of dynamic agents and achieves consistent shared world modeling.
Topology-Aware Revival for Efficient Sparse Training
Feb 04, 2026Static sparse training is a promising route to efficient learning by committing to a fixed mask pattern, yet the constrained structure reduces robustness. Early pruning decisions can lock the network into a brittle structure that is difficult to escape, especially in deep reinforcement learning (RL) where the evolving policy continually shifts the training distribution. We propose Topology-Aware Revival (TAR), a lightweight one-shot post-pruning procedure that improves static sparsity without dynamic rewiring. After static pruning, TAR performs a single revival step by allocating a small reserve budget across layers according to topology needs, randomly uniformly reactivating a few previously pruned connections within each layer, and then keeping the resulting connectivity fixed for the remainder of training. Across multiple continuous-control tasks with SAC and TD3, TAR improves final return over static sparse baselines by up to +37.9% and also outperforms dynamic sparse training baselines with a median gain of +13.5%.
GBR: Generative Bundle Refinement for High-fidelity Gaussian Splatting and Meshing
Dec 08, 2024



Gaussian splatting has gained attention for its efficient representation and rendering of 3D scenes using continuous Gaussian primitives. However, it struggles with sparse-view inputs due to limited geometric and photometric information, causing ambiguities in depth, shape, and texture. we propose GBR: Generative Bundle Refinement, a method for high-fidelity Gaussian splatting and meshing using only 4-6 input views. GBR integrates a neural bundle adjustment module to enhance geometry accuracy and a generative depth refinement module to improve geometry fidelity. More specifically, the neural bundle adjustment module integrates a foundation network to produce initial 3D point maps and point matches from unposed images, followed by bundle adjustment optimization to improve multiview consistency and point cloud accuracy. The generative depth refinement module employs a diffusion-based strategy to enhance geometric details and fidelity while preserving the scale. Finally, for Gaussian splatting optimization, we propose a multimodal loss function incorporating depth and normal consistency, geometric regularization, and pseudo-view supervision, providing robust guidance under sparse-view conditions. Experiments on widely used datasets show that GBR significantly outperforms existing methods under sparse-view inputs. Additionally, GBR demonstrates the ability to reconstruct and render large-scale real-world scenes, such as the Pavilion of Prince Teng and the Great Wall, with remarkable details using only 6 views.
Zoom in to the details of human-centric videos
May 27, 2020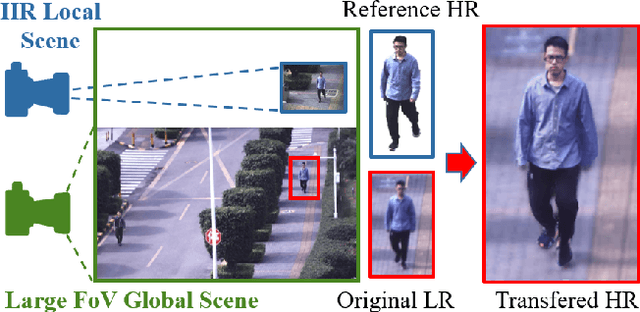
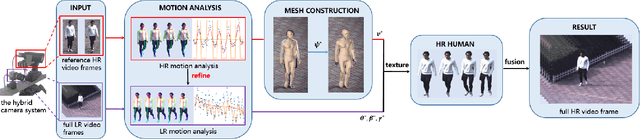
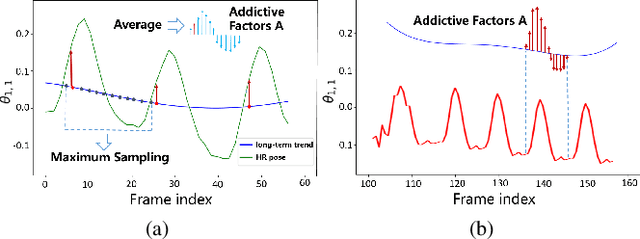

Presenting high-resolution (HR) human appearance is always critical for the human-centric videos. However, current imagery equipment can hardly capture HR details all the time. Existing super-resolution algorithms barely mitigate the problem by only considering universal and low-level priors of im-age patches. In contrast, our algorithm is under bias towards the human body super-resolution by taking advantage of high-level prior defined by HR human appearance. Firstly, a motion analysis module extracts inherent motion pattern from the HR reference video to refine the pose estimation of the low-resolution (LR) sequence. Furthermore, a human body reconstruction module maps the HR texture in the reference frames onto a 3D mesh model. Consequently, the input LR videos get super-resolved HR human sequences are generated conditioned on the original LR videos as well as few HR reference frames. Experiments on an existing dataset and real-world data captured by hybrid cameras show that our approach generates superior visual quality of human body compared with the traditional method.
PANDA: A Gigapixel-level Human-centric Video Dataset
Mar 10, 2020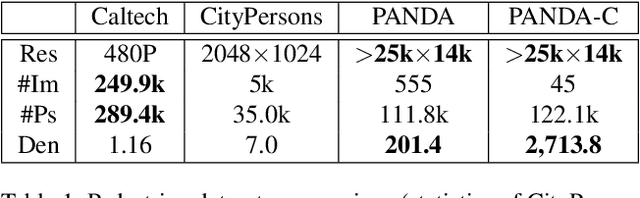

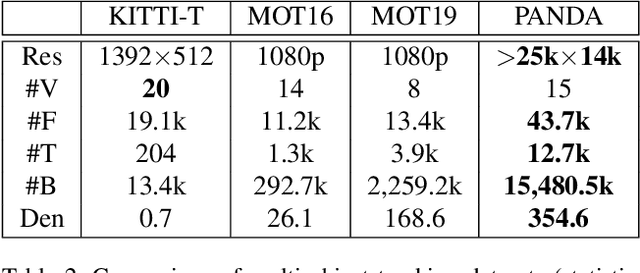
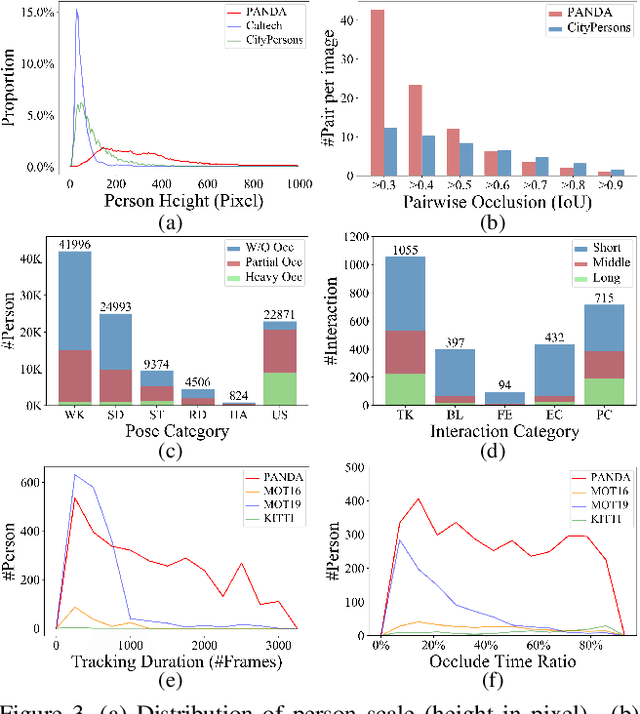
We present PANDA, the first gigaPixel-level humAN-centric viDeo dAtaset, for large-scale, long-term, and multi-object visual analysis. The videos in PANDA were captured by a gigapixel camera and cover real-world scenes with both wide field-of-view (~1 square kilometer area) and high-resolution details (~gigapixel-level/frame). The scenes may contain 4k head counts with over 100x scale variation. PANDA provides enriched and hierarchical ground-truth annotations, including 15,974.6k bounding boxes, 111.8k fine-grained attribute labels, 12.7k trajectories, 2.2k groups and 2.9k interactions. We benchmark the human detection and tracking tasks. Due to the vast variance of pedestrian pose, scale, occlusion and trajectory, existing approaches are challenged by both accuracy and efficiency. Given the uniqueness of PANDA with both wide FoV and high resolution, a new task of interaction-aware group detection is introduced. We design a 'global-to-local zoom-in' framework, where global trajectories and local interactions are simultaneously encoded, yielding promising results. We believe PANDA will contribute to the community of artificial intelligence and praxeology by understanding human behaviors and interactions in large-scale real-world scenes. PANDA Website: http://www.panda-dataset.com.