 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
Oct 28, 2021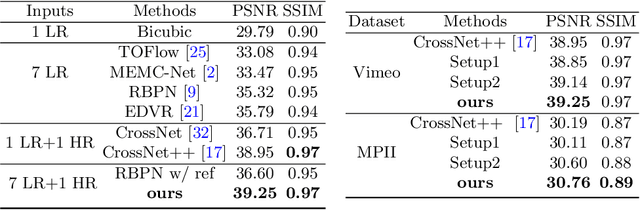
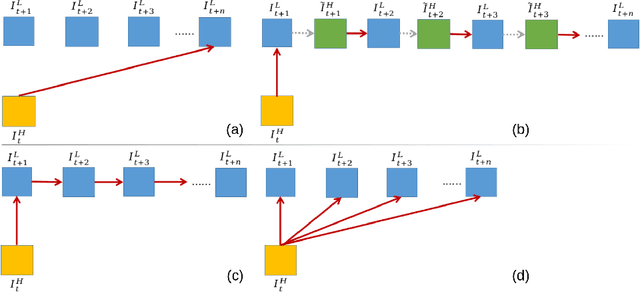


In this paper, we consider the problem of reference-based video super-resolution(RefVSR), i.e., how to utilize a high-resolution (HR) reference frame to super-resolve a low-resolution (LR) video sequence. The existing approaches to RefVSR essentially attempt to align the reference and the input sequence, in the presence of resolution gap and long temporal range. However, they either ignore temporal structure within the input sequence, or suffer accumulative alignment errors. To address these issues, we propose EFENet to exploit simultaneously the visual cues contained in the HR reference and the temporal information contained in the LR sequence. EFENet first globally estimates cross-scale flow between the reference and each LR frame. Then our novel flow refinement module of EFENet refines the flow regarding the furthest frame using all the estimated flows, which leverages the global temporal information within the sequence and therefore effectively reduces the alignment errors. We provide comprehensive evaluations to validate the strengths of our approach, and to demonstrate that the proposed framework outperforms the state-of-the-art methods. Code is available at https://github.com/IndigoPurple/EFENet.
Zoom in to the details of human-centric videos
May 27, 2020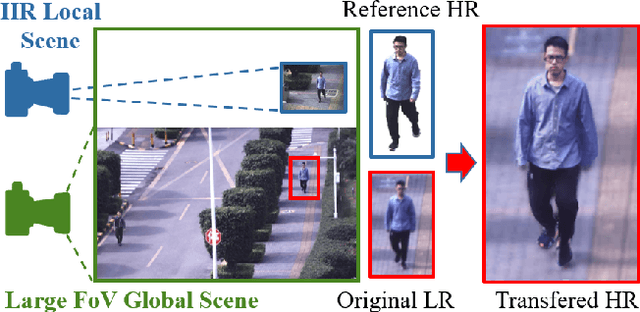
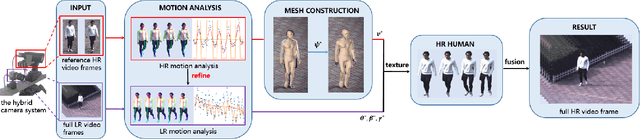
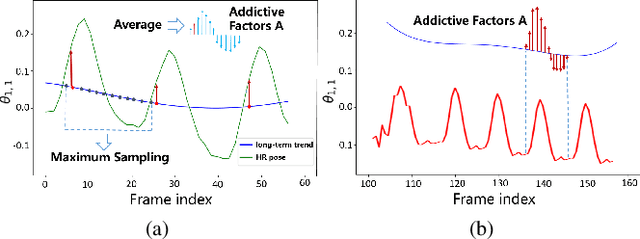

Presenting high-resolution (HR) human appearance is always critical for the human-centric videos. However, current imagery equipment can hardly capture HR details all the time. Existing super-resolution algorithms barely mitigate the problem by only considering universal and low-level priors of im-age patches. In contrast, our algorithm is under bias towards the human body super-resolution by taking advantage of high-level prior defined by HR human appearance. Firstly, a motion analysis module extracts inherent motion pattern from the HR reference video to refine the pose estimation of the low-resolution (LR) sequence. Furthermore, a human body reconstruction module maps the HR texture in the reference frames onto a 3D mesh model. Consequently, the input LR videos get super-resolved HR human sequences are generated conditioned on the original LR videos as well as few HR reference frames. Experiments on an existing dataset and real-world data captured by hybrid cameras show that our approach generates superior visual quality of human body compared with the traditional method.
SurfaceNet+: An End-to-end 3D Neural Network for Very Sparse Multi-view Stereopsis
May 26, 2020
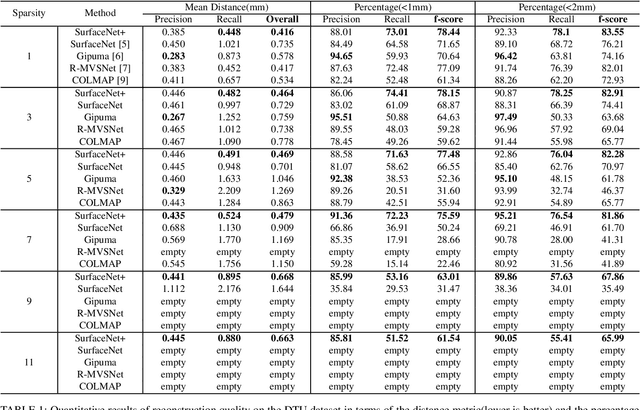
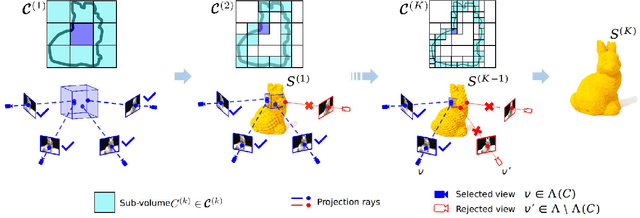
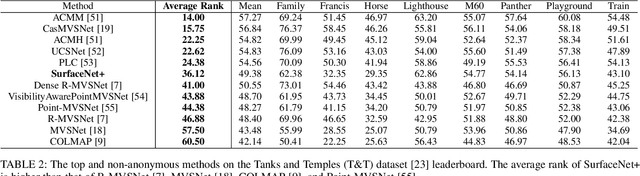
Multi-view stereopsis (MVS) tries to recover the 3D model from 2D images. As the observations become sparser, the significant 3D information loss makes the MVS problem more challenging. Instead of only focusing on densely sampled conditions, we investigate sparse-MVS with large baseline angles since the sparser sensation is more practical and more cost-efficient. By investigating various observation sparsities, we show that the classical depth-fusion pipeline becomes powerless for the case with a larger baseline angle that worsens the photo-consistency check. As another line of the solution, we present SurfaceNet+, a volumetric method to handle the 'incompleteness' and the 'inaccuracy' problems induced by a very sparse MVS setup. Specifically, the former problem is handled by a novel volume-wise view selection approach. It owns superiority in selecting valid views while discarding invalid occluded views by considering the geometric prior. Furthermore, the latter problem is handled via a multi-scale strategy that consequently refines the recovered geometry around the region with the repeating pattern. The experiments demonstrate the tremendous performance gap between SurfaceNet+ and state-of-the-art methods in terms of precision and recall. Under the extreme sparse-MVS settings in two datasets, where existing methods can only return very few points, SurfaceNet+ still works as well as in the dense MVS setting. The benchmark and the implementation are publicly available at https://github.com/mjiUST/SurfaceNet-plus.
* Accepted by IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), May 2020
SPI-Optimizer: an integral-Separated PI Controller for Stochastic Optimization
Dec 29, 2018

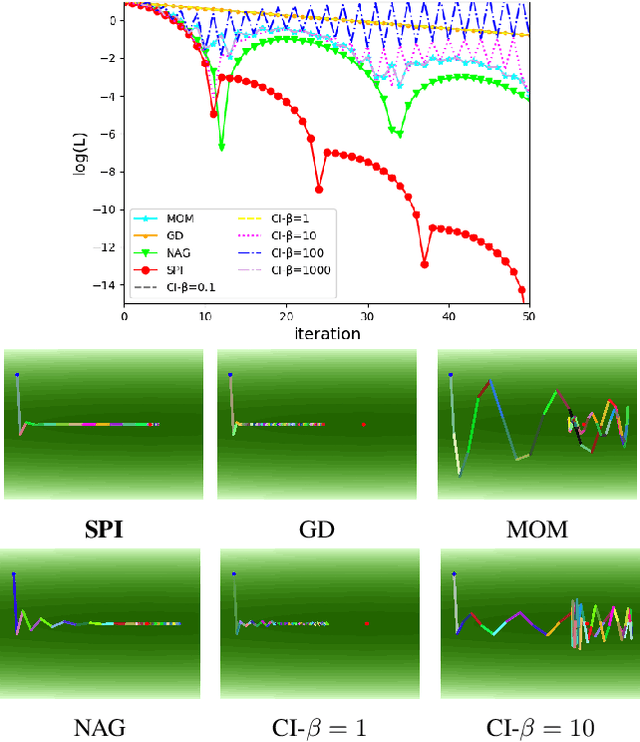

To overcome the oscillation problem in the classical momentum-based optimizer, recent work associates it with the proportional-integral (PI) controller, and artificially adds D term producing a PID controller. It suppresses oscillation with the sacrifice of introducing extra hyper-parameter. In this paper, we start by analyzing: why momentum-based method oscillates about the optimal point? and answering that: the fluctuation problem relates to the lag effect of integral (I) term. Inspired by the conditional integration idea in classical control society, we propose SPI-Optimizer, an integral-Separated PI controller based optimizer WITHOUT introducing extra hyperparameter. It separates momentum term adaptively when the inconsistency of current and historical gradient direction occurs. Extensive experiments demonstrate that SPIOptimizer generalizes well on popular network architectures to eliminate the oscillation, and owns competitive performance with faster convergence speed (up to 40% epochs reduction ratio ) and more accurate classification result on MNIST, CIFAR10, and CIFAR100 (up to 27.5% error reduction ratio) than the state-of-the-art methods.
RegNet: Learning the Optimization of Direct Image-to-Image Pose Registration
Dec 26, 2018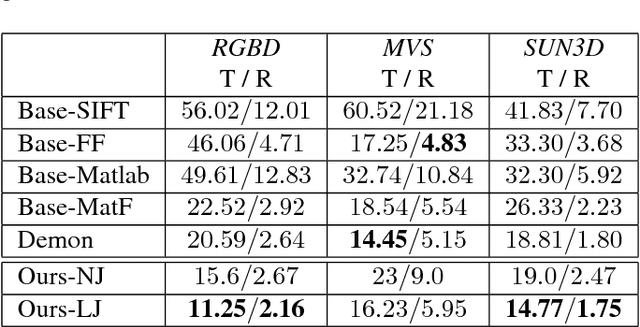
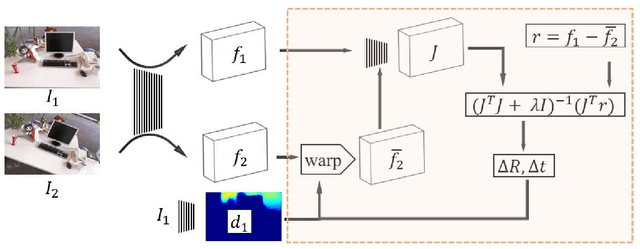

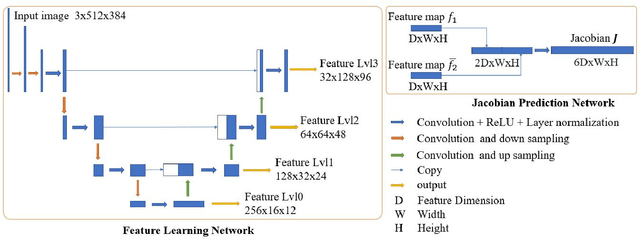
Direct image-to-image alignment that relies on the optimization of photometric error metrics suffers from limited convergence range and sensitivity to lighting conditions. Deep learning approaches has been applied to address this problem by learning better feature representations using convolutional neural networks, yet still require a good initialization. In this paper, we demonstrate that the inaccurate numerical Jacobian limits the convergence range which could be improved greatly using learned approaches. Based on this observation, we propose a novel end-to-end network, RegNet, to learn the optimization of image-to-image pose registration. By jointly learning feature representation for each pixel and partial derivatives that replace handcrafted ones (e.g., numerical differentiation) in the optimization step, the neural network facilitates end-to-end optimization. The energy landscape is constrained on both the feature representation and the learned Jacobian, hence providing more flexibility for the optimization as a consequence leads to more robust and faster convergence. In a series of experiments, including a broad ablation study, we demonstrate that RegNet is able to converge for large-baseline image pairs with fewer iterations.
CrossNet: An End-to-end Reference-based Super Resolution Network using Cross-scale Warping
Jul 27, 2018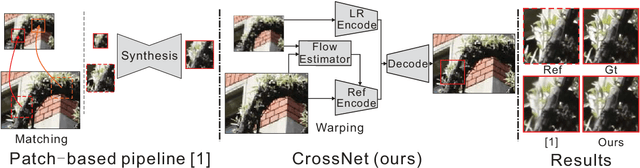

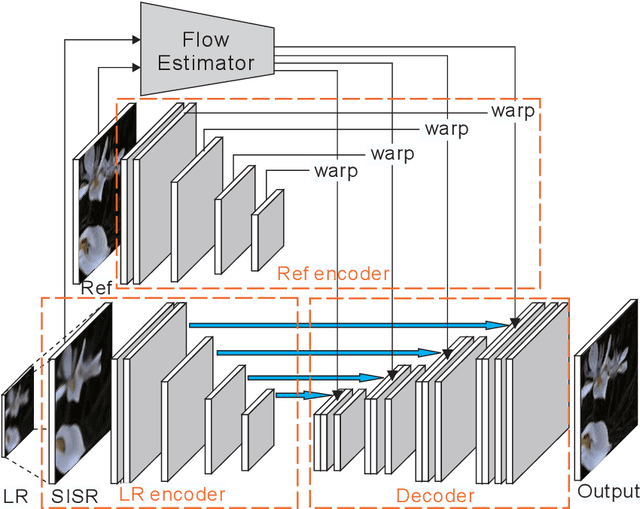
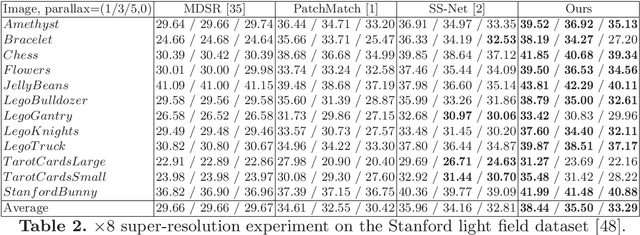
The Reference-based Super-resolution (RefSR) super-resolves a low-resolution (LR) image given an external high-resolution (HR) reference image, where the reference image and LR image share similar viewpoint but with significant resolution gap x8. Existing RefSR methods work in a cascaded way such as patch matching followed by synthesis pipeline with two independently defined objective functions, leading to the inter-patch misalignment, grid effect and inefficient optimization. To resolve these issues, we present CrossNet, an end-to-end and fully-convolutional deep neural network using cross-scale warping. Our network contains image encoders, cross-scale warping layers, and fusion decoder: the encoder serves to extract multi-scale features from both the LR and the reference images; the cross-scale warping layers spatially aligns the reference feature map with the LR feature map; the decoder finally aggregates feature maps from both domains to synthesize the HR output. Using cross-scale warping, our network is able to perform spatial alignment at pixel-level in an end-to-end fashion, which improves the existing schemes both in precision (around 2dB-4dB) and efficiency (more than 100 times faster).
SurfaceNet: An End-to-end 3D Neural Network for Multiview Stereopsis
Aug 05, 2017
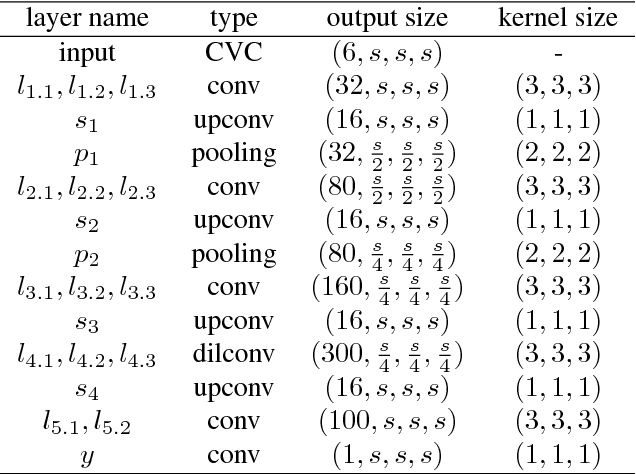
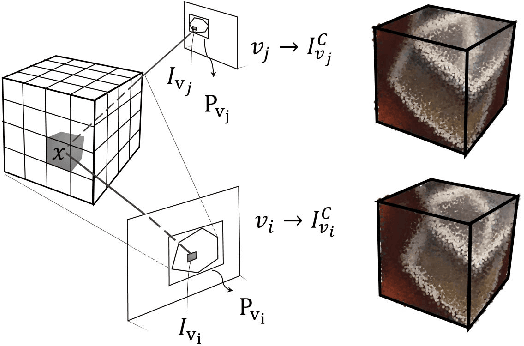
This paper proposes an end-to-end learning framework for multiview stereopsis. We term the network SurfaceNet. It takes a set of images and their corresponding camera parameters as input and directly infers the 3D model. The key advantage of the framework is that both photo-consistency as well geometric relations of the surface structure can be directly learned for the purpose of multiview stereopsis in an end-to-end fashion. SurfaceNet is a fully 3D convolutional network which is achieved by encoding the camera parameters together with the images in a 3D voxel representation. We evaluate SurfaceNet on the large-scale DTU benchmark.
Deep Learning for Surface Material Classification Using Haptic And Visual Information
May 01, 2016
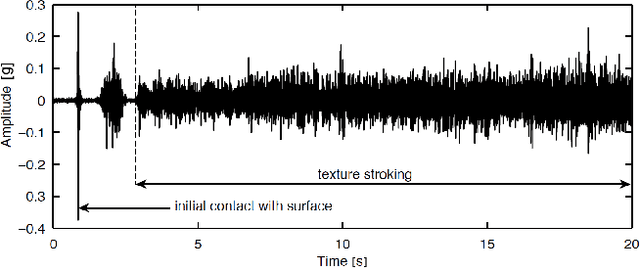

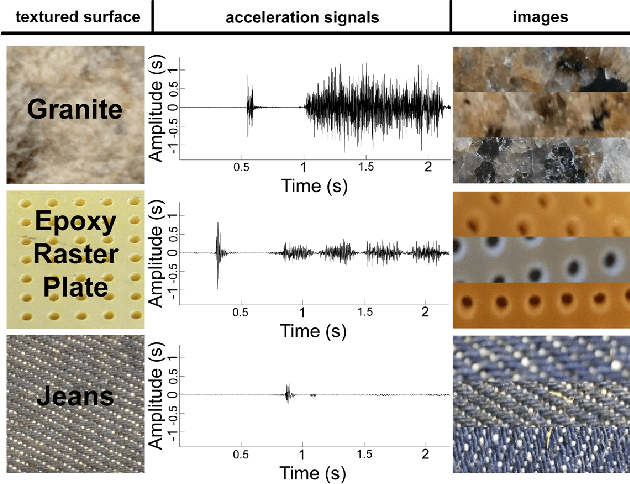
When a user scratches a hand-held rigid tool across an object surface, an acceleration signal can be captured, which carries relevant information about the surface. More importantly, such a haptic signal is complementary to the visual appearance of the surface, which suggests the combination of both modalities for the recognition of the surface material. In this paper, we present a novel deep learning method dealing with the surface material classification problem based on a Fully Convolutional Network (FCN), which takes as input the aforementioned acceleration signal and a corresponding image of the surface texture. Compared to previous surface material classification solutions, which rely on a careful design of hand-crafted domain-specific features, our method automatically extracts discriminative features utilizing the advanced deep learning methodologies. Experiments performed on the TUM surface material database demonstrate that our method achieves state-of-the-art classification accuracy robustly and efficiently.
Learning High-level Prior with Convolutional Neural Networks for Semantic Segmentation
Nov 22, 2015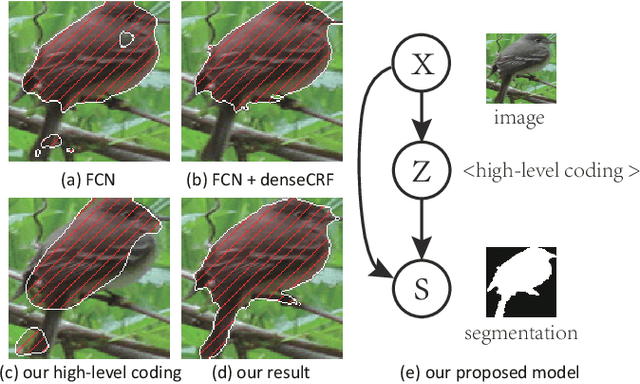
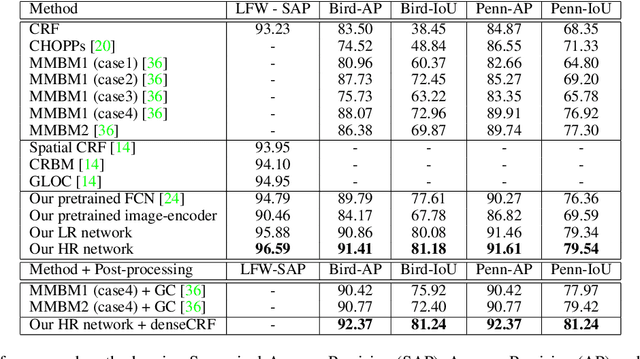
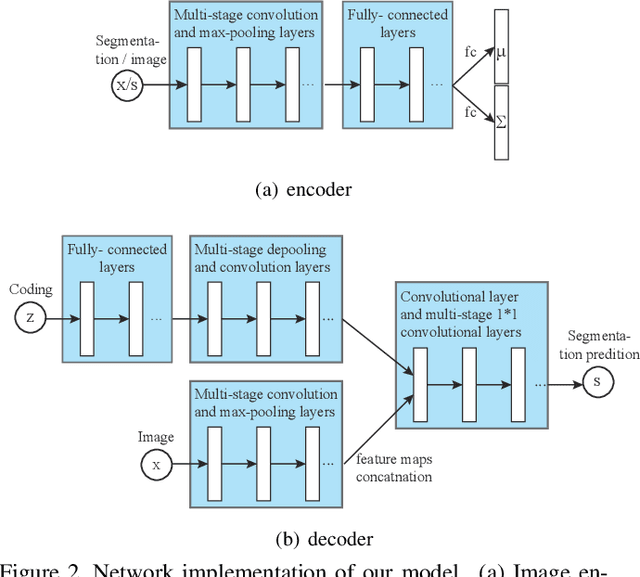
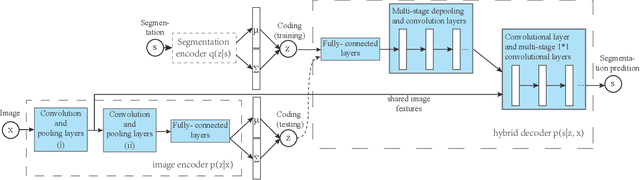
This paper proposes a convolutional neural network that can fuse high-level prior for semantic image segmentation. Motivated by humans' vision recognition system, our key design is a three-layer generative structure consisting of high-level coding, middle-level segmentation and low-level image to introduce global prior for semantic segmentation. Based on this structure, we proposed a generative model called conditional variational auto-encoder (CVAE) that can build up the links behind these three layers. These important links include an image encoder that extracts high level info from image, a segmentation encoder that extracts high level info from segmentation, and a hybrid decoder that outputs semantic segmentation from the high level prior and input image. We theoretically derive the semantic segmentation as an optimization problem parameterized by these links. Finally, the optimization problem enables us to take advantage of state-of-the-art fully convolutional network structure for the implementation of the above encoders and decoder. Experimental results on several representative datasets demonstrate our supreme performance for semantic segmentation.