 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Open-World Mobile Manipulation in Homes: Lessons from the Neurips 2023 HomeRobot Open Vocabulary Mobile Manipulation Challenge
Jul 09, 2024



In order to develop robots that can effectively serve as versatile and capable home assistants, it is crucial for them to reliably perceive and interact with a wide variety of objects across diverse environments. To this end, we proposed Open Vocabulary Mobile Manipulation as a key benchmark task for robotics: finding any object in a novel environment and placing it on any receptacle surface within that environment. We organized a NeurIPS 2023 competition featuring both simulation and real-world components to evaluate solutions to this task. Our baselines on the most challenging version of this task, using real perception in simulation, achieved only an 0.8% success rate; by the end of the competition, the best participants achieved an 10.8\% success rate, a 13x improvement. We observed that the most successful teams employed a variety of methods, yet two common threads emerged among the best solutions: enhancing error detection and recovery, and improving the integration of perception with decision-making processes. In this paper, we detail the results and methodologies used, both in simulation and real-world settings. We discuss the lessons learned and their implications for future research. Additionally, we compare performance in real and simulated environments, emphasizing the necessity for robust generalization to novel settings.
Neuromorphic Imaging with Super-Resolution
Jul 08, 2024



Neuromorphic imaging is a bio-inspired technique that imitates the human retina to sense variations in a dynamic scene. It responds to pixel-level brightness changes by asynchronous streaming events and boasts microsecond temporal precision over a high dynamic range, yielding blur-free recordings under extreme illumination. Nevertheless, such a modality falls short in spatial resolution and leads to a low level of visual richness and clarity. Pursuing hardware upgrades is expensive and might cause compromised performance due to more burdens on computational requirements. Another option is to harness offline, plug-in-play neuromorphic super-resolution solutions. However, existing ones, which demand substantial sample volumes for lengthy training on massive computing resources, are largely restricted by real data availability owing to the current imperfect high-resolution devices, as well as the randomness and variability of motion. To tackle these challenges, we introduce the first self-supervised neuromorphic super-resolution prototype. It can be self-adaptive to per input source from any low-resolution camera to estimate an optimal, high-resolution counterpart of any scale, without the need of side knowledge and prior training. Evaluated on downstream event-driven tasks, such a simple yet effective method can obtain competitive results against the state-of-the-arts, significantly promoting flexibility but not sacrificing accuracy. It also delivers enhancements for inferior natural images and optical micrographs acquired under non-ideal imaging conditions, breaking through the limitations that are challenging to overcome with traditional frame techniques. In the current landscape where the use of high-resolution cameras for event-based sensing remains an open debate, our solution serves as a cost-efficient and practical alternative, paving the way for more intelligent imaging systems.
SASA: Saliency-Aware Self-Adaptive Snapshot Compressive Imaging
Dec 30, 2023The ability of snapshot compressive imaging (SCI) systems to efficiently capture high-dimensional (HD) data depends on the advent of novel optical designs to sample the HD data as two-dimensional (2D) compressed measurements. Nonetheless, the traditional SCI scheme is fundamentally limited, due to the complete disregard for high-level information in the sampling process. To tackle this issue, in this paper, we pave the first mile toward the advanced design of adaptive coding masks for SCI. Specifically, we propose an efficient and effective algorithm to generate coding masks with the assistance of saliency detection, in a low-cost and low-power fashion. Experiments demonstrate the effectiveness and efficiency of our approach. Code is available at: https://github.com/IndigoPurple/SASA
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023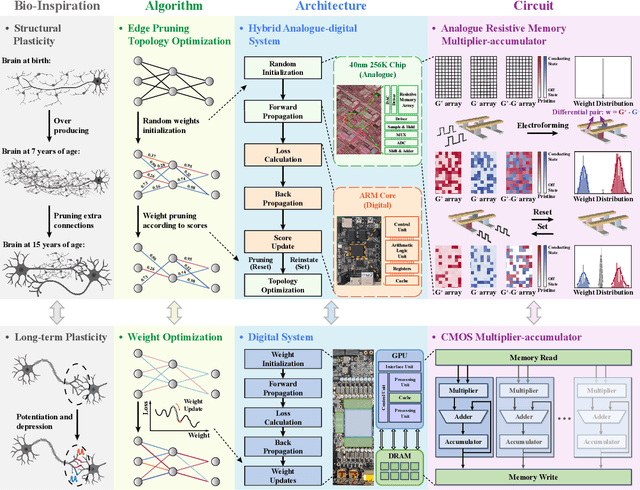
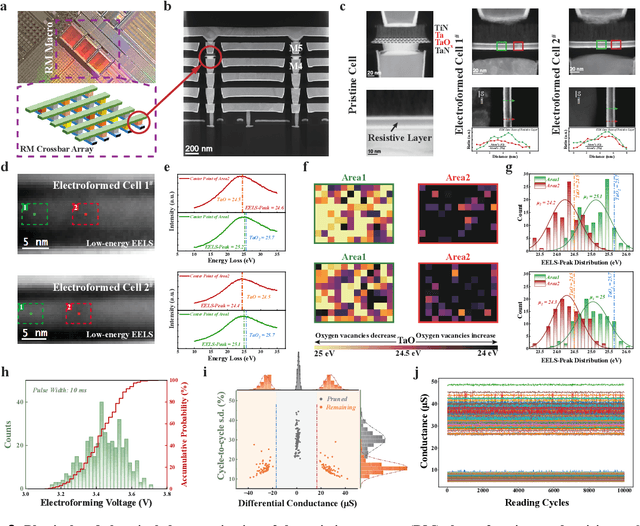
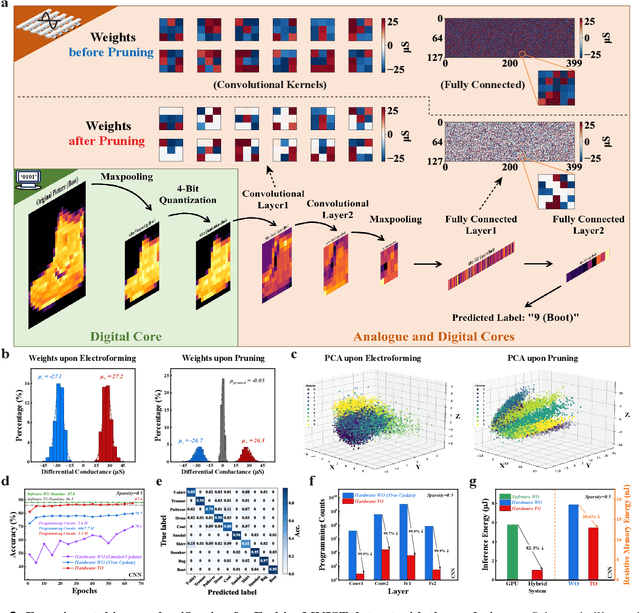
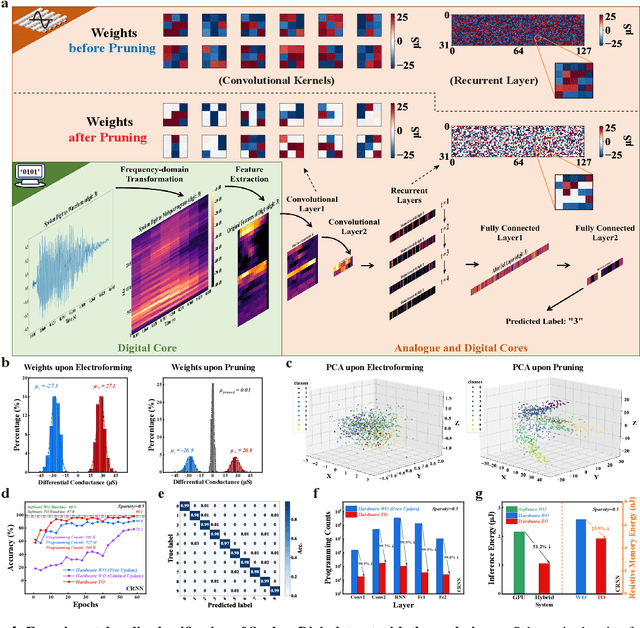
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.
Large-Scale Traffic Congestion Prediction based on Multimodal Fusion and Representation Mapping
Aug 23, 2022



With the progress of the urbanisation process, the urban transportation system is extremely critical to the development of cities and the quality of life of the citizens. Among them, it is one of the most important tasks to judge traffic congestion by analysing the congestion factors. Recently, various traditional and machine-learning-based models have been introduced for predicting traffic congestion. However, these models are either poorly aggregated for massive congestion factors or fail to make accurate predictions for every precise location in large-scale space. To alleviate these problems, a novel end-to-end framework based on convolutional neural networks is proposed in this paper. With learning representations, the framework proposes a novel multimodal fusion module and a novel representation mapping module to achieve traffic congestion predictions on arbitrary query locations on a large-scale map, combined with various global reference information. The proposed framework achieves significant results and efficient inference on real-world large-scale datasets.
Point Cloud Denoising via Momentum Ascent in Gradient Fields
Mar 15, 2022



To achieve point cloud denoising, traditional methods heavily rely on geometric priors, and most learning-based approaches suffer from outliers and loss of details. Recently, the gradient-based method was proposed to estimate the gradient fields from the noisy point clouds using neural networks, and refine the position of each point according to the estimated gradient. However, the predicted gradient could fluctuate, leading to perturbed and unstable solutions, as well as a large inference time. To address these issues, we develop the momentum gradient ascent method that leverages the information of previous iterations in determining the trajectories of the points, thus improving the stability of the solution and reducing the inference time. Experiments demonstrate that the proposed method outperforms state-of-the-art methods with a variety of point clouds and noise levels.
MANet: Improving Video Denoising with a Multi-Alignment Network
Feb 20, 2022



In video denoising, the adjacent frames often provide very useful information, but accurate alignment is needed before such information can be harnassed. In this work, we present a multi-alignment network, which generates multiple flow proposals followed by attention-based averaging. It serves to mimics the non-local mechanism, suppressing noise by averaging multiple observations. Our approach can be applied to various state-of-the-art models that are based on flow estimation. Experiments on a large-scale video dataset demonstrate that our method improves the denoising baseline model by 0.2dB, and further reduces the parameters by 47% with model distillation.
Mathematical Cookbook for Snapshot Compressive Imaging
Feb 09, 2022The author intends to provide you with a beautiful, elegant, user-friendly cookbook for mathematics in Snapshot Compressive Imaging (SCI). Currently, the cookbook is composed of introduction and conventional optimization, using regularization-based optimization algorithms for SCI. The latest releases are strongly recommended! For any other questions, suggestions, or comments, feel free to email the author.
Deep Equilibrium Models for Video Snapshot Compressive Imaging
Jan 18, 2022The ability of snapshot compressive imaging (SCI) systems to efficiently capture high-dimensional (HD) data has led to an inverse problem, which consists of recovering the HD signal from the compressed and noisy measurement. While reconstruction algorithms grow fast to solve it with the recent advances of deep learning, the fundamental issue of accurate and stable recovery remains. To this end, we propose deep equilibrium models (DEQ) for video SCI, fusing data-driven regularization and stable convergence in a theoretically sound manner. Each equilibrium model implicitly learns a nonexpansive operator and analytically computes the fixed point, thus enabling unlimited iterative steps and infinite network depth with only a constant memory requirement in training and testing. Specifically, we demonstrate how DEQ can be applied to two existing models for video SCI reconstruction: recurrent neural networks (RNN) and Plug-and-Play (PnP) algorithms. On a variety of datasets and real data, both quantitative and qualitative evaluations of our results demonstrate the effectiveness and stability of our proposed method. The code and models will be released to the public.
EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
Oct 28, 2021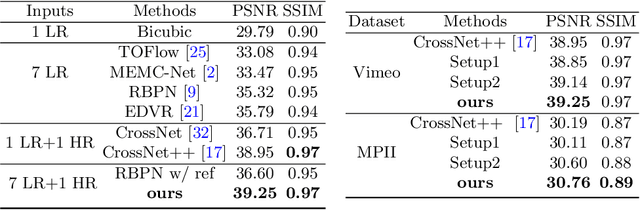
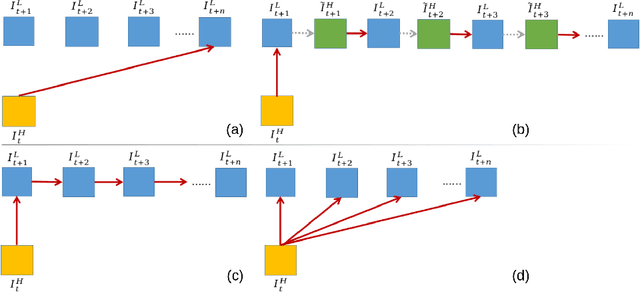


In this paper, we consider the problem of reference-based video super-resolution(RefVSR), i.e., how to utilize a high-resolution (HR) reference frame to super-resolve a low-resolution (LR) video sequence. The existing approaches to RefVSR essentially attempt to align the reference and the input sequence, in the presence of resolution gap and long temporal range. However, they either ignore temporal structure within the input sequence, or suffer accumulative alignment errors. To address these issues, we propose EFENet to exploit simultaneously the visual cues contained in the HR reference and the temporal information contained in the LR sequence. EFENet first globally estimates cross-scale flow between the reference and each LR frame. Then our novel flow refinement module of EFENet refines the flow regarding the furthest frame using all the estimated flows, which leverages the global temporal information within the sequence and therefore effectively reduces the alignment errors. We provide comprehensive evaluations to validate the strengths of our approach, and to demonstrate that the proposed framework outperforms the state-of-the-art methods. Code is available at https://github.com/IndigoPurple/EFENet.