 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
Paper and Code
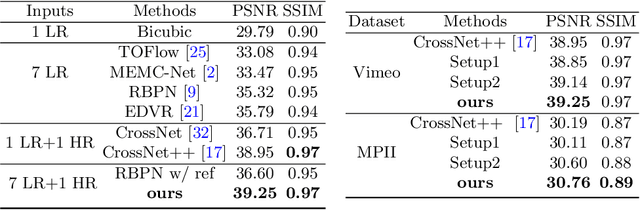
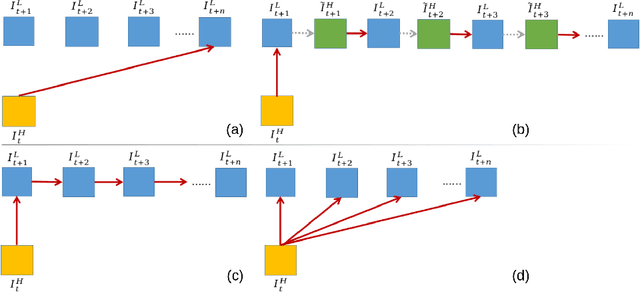


In this paper, we consider the problem of reference-based video super-resolution(RefVSR), i.e., how to utilize a high-resolution (HR) reference frame to super-resolve a low-resolution (LR) video sequence. The existing approaches to RefVSR essentially attempt to align the reference and the input sequence, in the presence of resolution gap and long temporal range. However, they either ignore temporal structure within the input sequence, or suffer accumulative alignment errors. To address these issues, we propose EFENet to exploit simultaneously the visual cues contained in the HR reference and the temporal information contained in the LR sequence. EFENet first globally estimates cross-scale flow between the reference and each LR frame. Then our novel flow refinement module of EFENet refines the flow regarding the furthest frame using all the estimated flows, which leverages the global temporal information within the sequence and therefore effectively reduces the alignment errors. We provide comprehensive evaluations to validate the strengths of our approach, and to demonstrate that the proposed framework outperforms the state-of-the-art methods. Code is available at https://github.com/IndigoPurple/EFENet.