 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024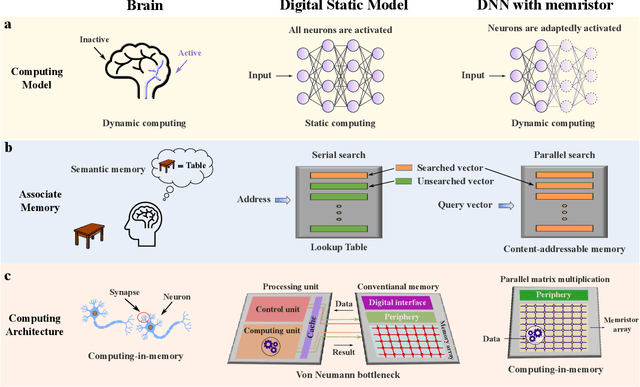
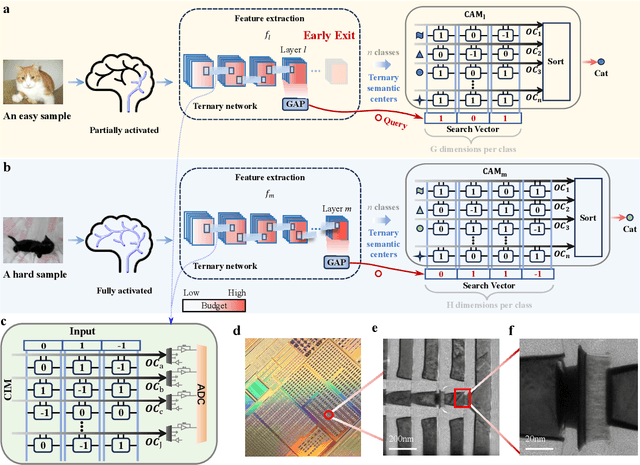
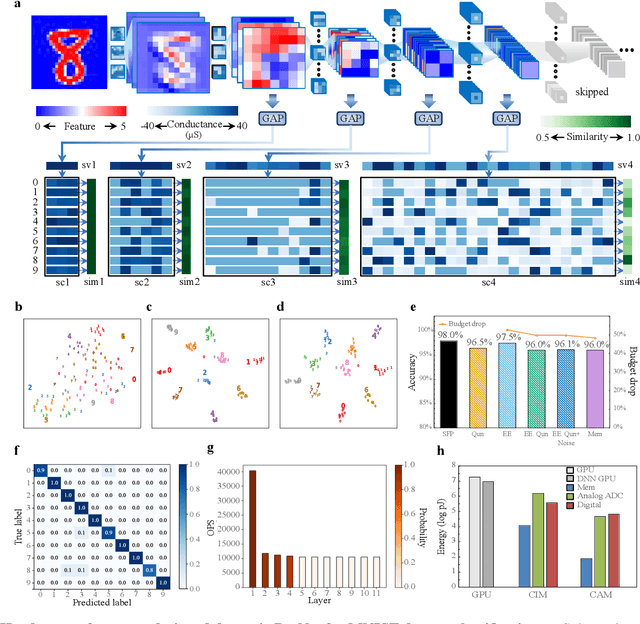
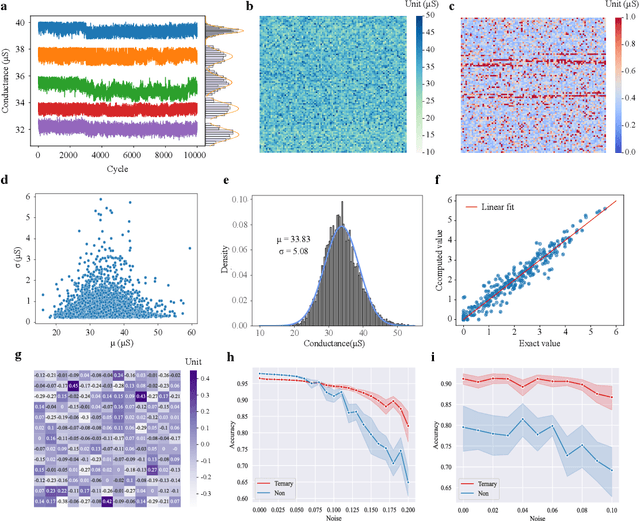
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.
Efficient and accurate neural field reconstruction using resistive memory
Apr 15, 2024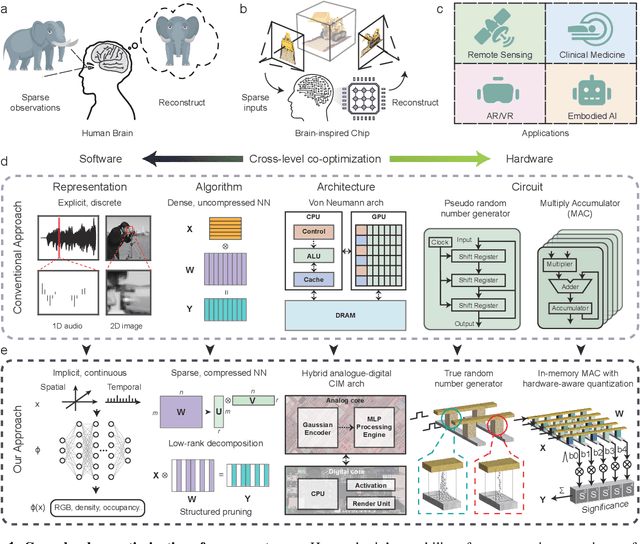
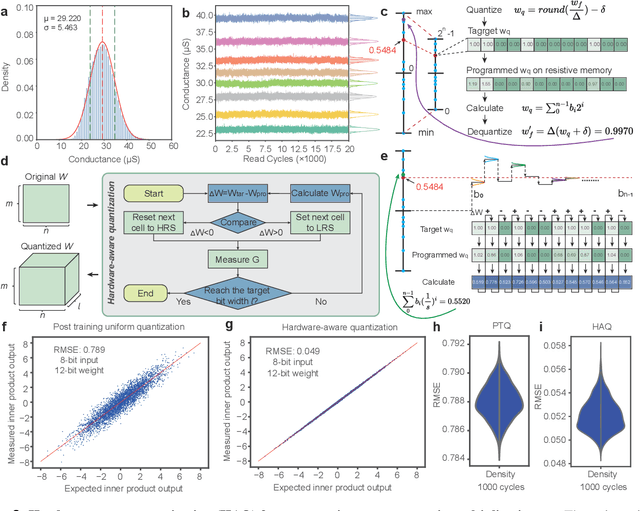
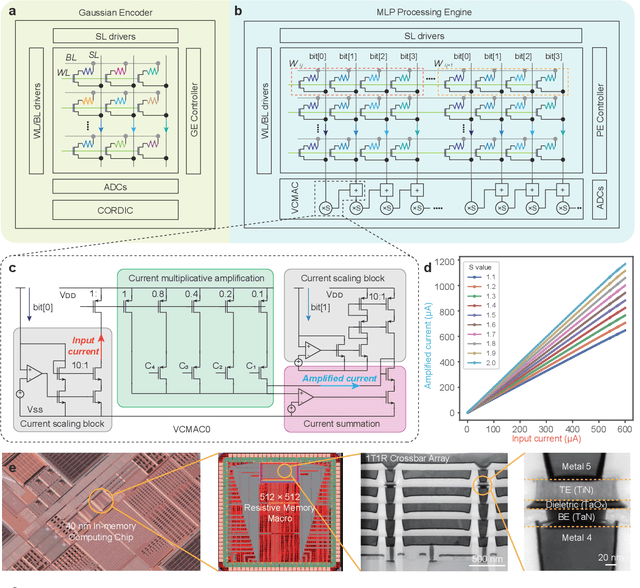
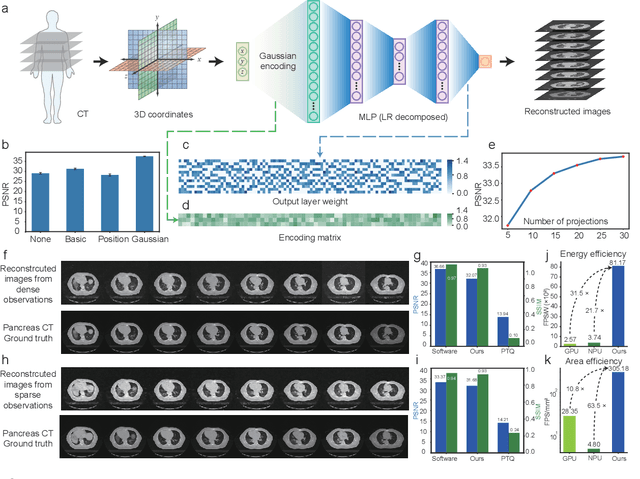
Human beings construct perception of space by integrating sparse observations into massively interconnected synapses and neurons, offering a superior parallelism and efficiency. Replicating this capability in AI finds wide applications in medical imaging, AR/VR, and embodied AI, where input data is often sparse and computing resources are limited. However, traditional signal reconstruction methods on digital computers face both software and hardware challenges. On the software front, difficulties arise from storage inefficiencies in conventional explicit signal representation. Hardware obstacles include the von Neumann bottleneck, which limits data transfer between the CPU and memory, and the limitations of CMOS circuits in supporting parallel processing. We propose a systematic approach with software-hardware co-optimizations for signal reconstruction from sparse inputs. Software-wise, we employ neural field to implicitly represent signals via neural networks, which is further compressed using low-rank decomposition and structured pruning. Hardware-wise, we design a resistive memory-based computing-in-memory (CIM) platform, featuring a Gaussian Encoder (GE) and an MLP Processing Engine (PE). The GE harnesses the intrinsic stochasticity of resistive memory for efficient input encoding, while the PE achieves precise weight mapping through a Hardware-Aware Quantization (HAQ) circuit. We demonstrate the system's efficacy on a 40nm 256Kb resistive memory-based in-memory computing macro, achieving huge energy efficiency and parallelism improvements without compromising reconstruction quality in tasks like 3D CT sparse reconstruction, novel view synthesis, and novel view synthesis for dynamic scenes. This work advances the AI-driven signal restoration technology and paves the way for future efficient and robust medical AI and 3D vision applications.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023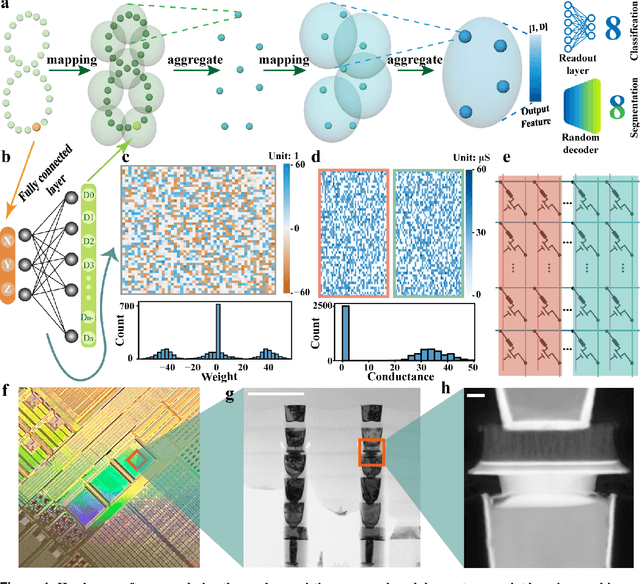
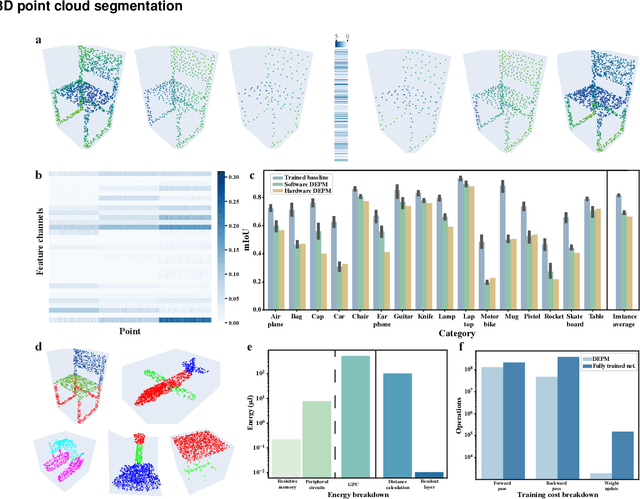
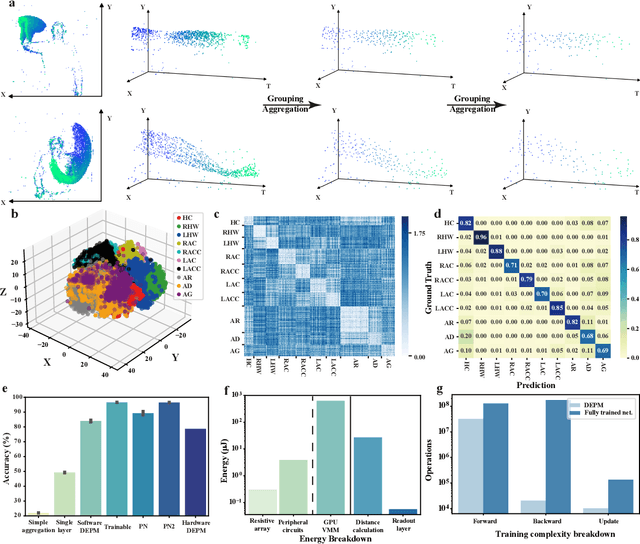
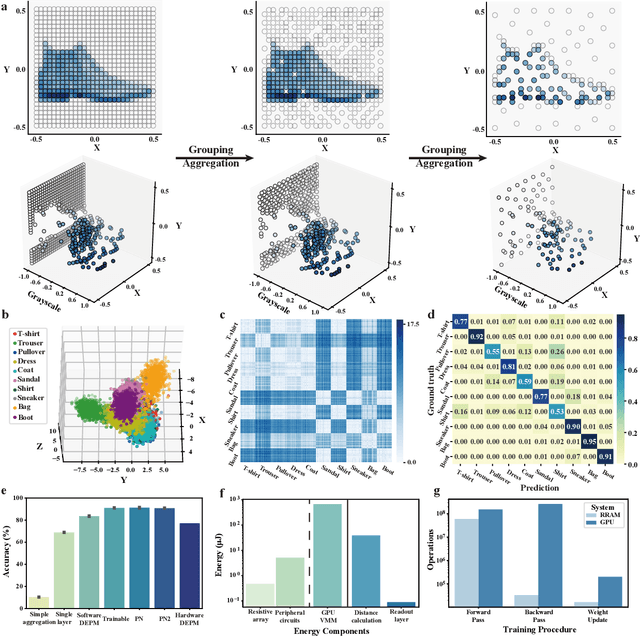
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023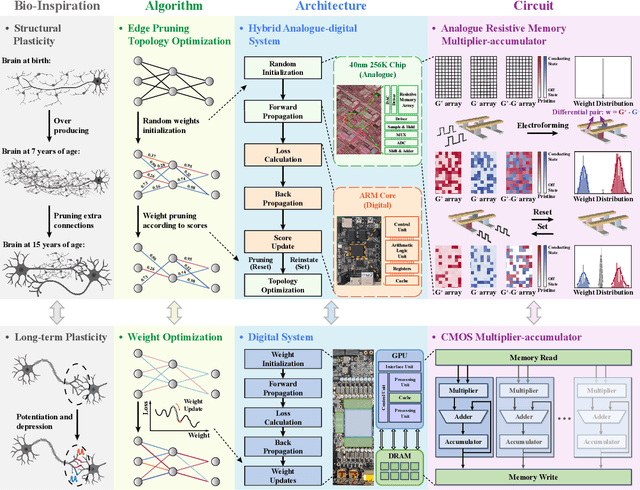
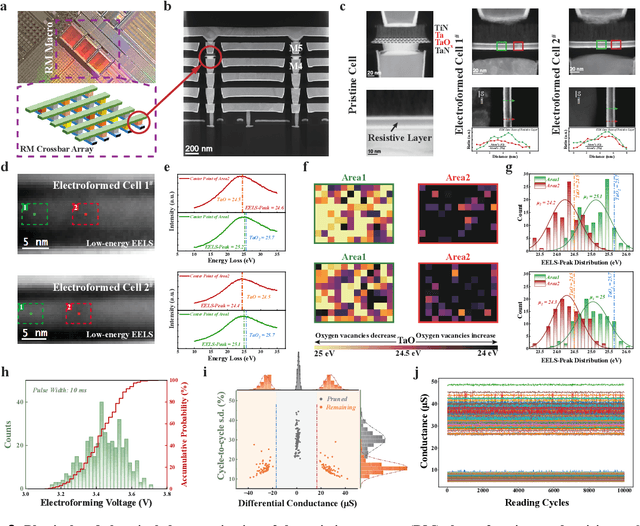
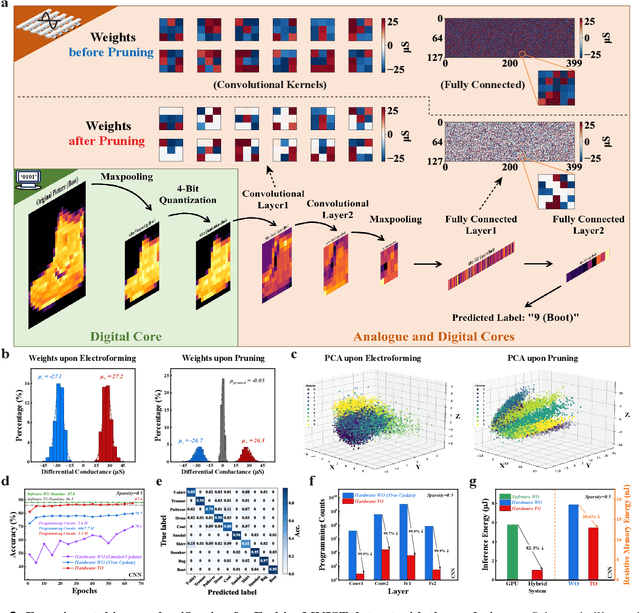
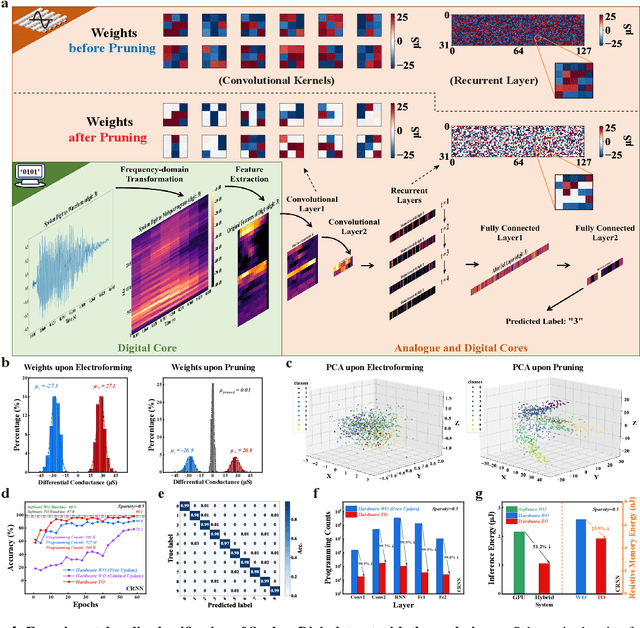
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.