 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResistive Memory-based Neural Differential Equation Solver for Score-based Diffusion Model
Apr 08, 2024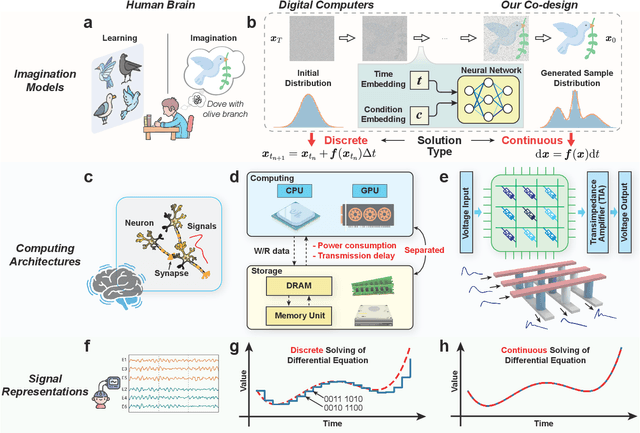
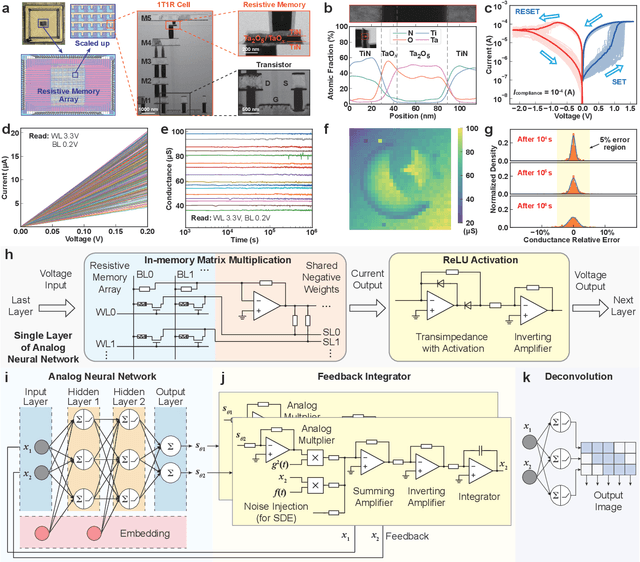
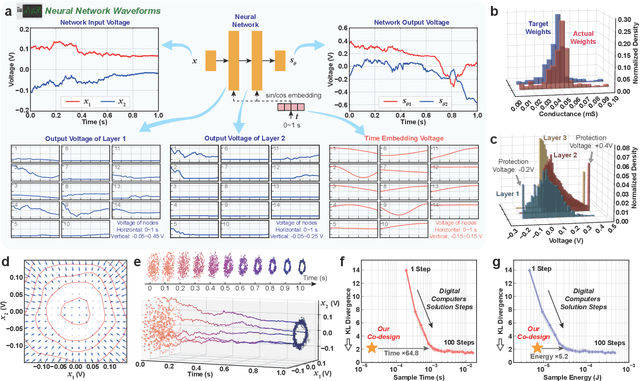
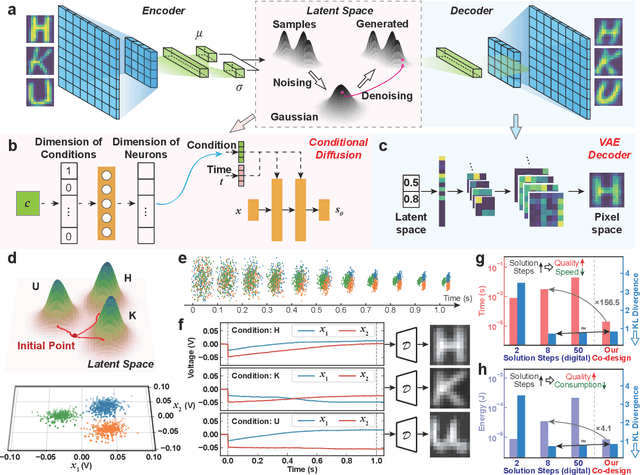
Human brains image complicated scenes when reading a novel. Replicating this imagination is one of the ultimate goals of AI-Generated Content (AIGC). However, current AIGC methods, such as score-based diffusion, are still deficient in terms of rapidity and efficiency. This deficiency is rooted in the difference between the brain and digital computers. Digital computers have physically separated storage and processing units, resulting in frequent data transfers during iterative calculations, incurring large time and energy overheads. This issue is further intensified by the conversion of inherently continuous and analog generation dynamics, which can be formulated by neural differential equations, into discrete and digital operations. Inspired by the brain, we propose a time-continuous and analog in-memory neural differential equation solver for score-based diffusion, employing emerging resistive memory. The integration of storage and computation within resistive memory synapses surmount the von Neumann bottleneck, benefiting the generative speed and energy efficiency. The closed-loop feedback integrator is time-continuous, analog, and compact, physically implementing an infinite-depth neural network. Moreover, the software-hardware co-design is intrinsically robust to analog noise. We experimentally validate our solution with 180 nm resistive memory in-memory computing macros. Demonstrating equivalent generative quality to the software baseline, our system achieved remarkable enhancements in generative speed for both unconditional and conditional generation tasks, by factors of 64.8 and 156.5, respectively. Moreover, it accomplished reductions in energy consumption by factors of 5.2 and 4.1. Our approach heralds a new horizon for hardware solutions in edge computing for generative AI applications.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023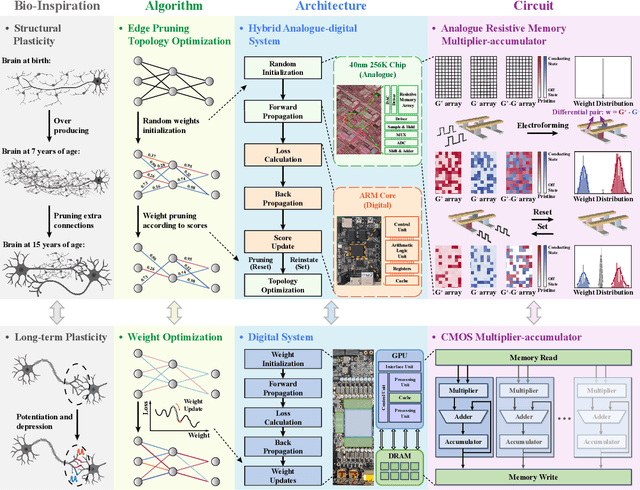
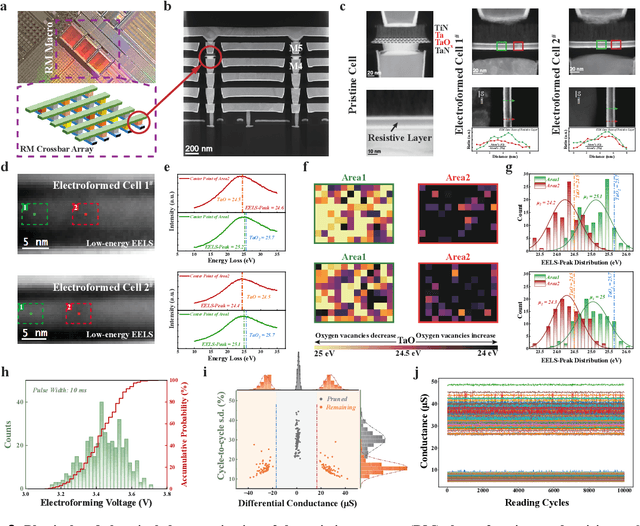
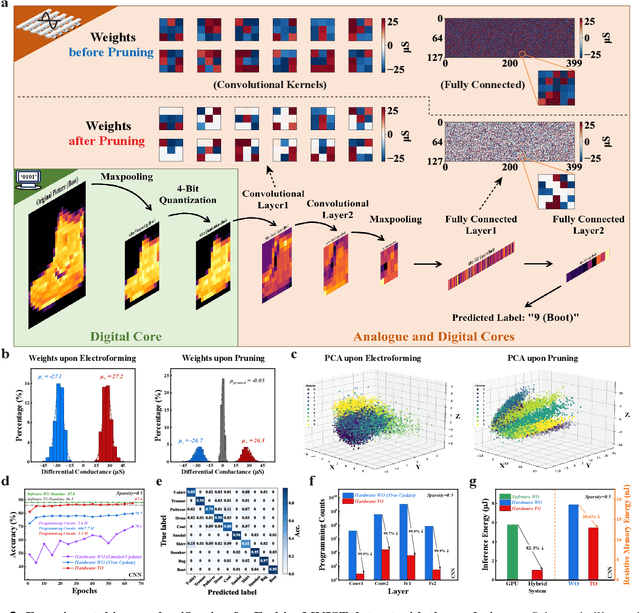
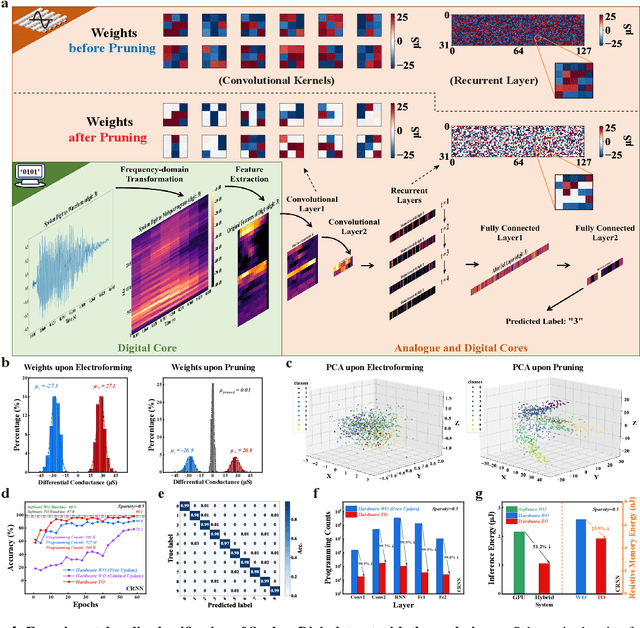
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.