 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization and Generation in Aerodynamics Inverse Design
Feb 03, 2026Inverse design with physics-based objectives is challenging because it couples high-dimensional geometry with expensive simulations, as exemplified by aerodynamic shape optimization for drag reduction. We revisit inverse design through two canonical solutions, the optimal design point and the optimal design distribution, and relate them to optimization and guided generation. Building on this view, we propose a new training loss for cost predictors and a density-gradient optimization method that improves objectives while preserving plausible shapes. We further unify existing training-free guided generation methods. To address their inability to approximate conditional covariance in high dimensions, we develop a time- and memory-efficient algorithm for approximate covariance estimation. Experiments on a controlled 2D study and high-fidelity 3D aerodynamic benchmarks (car and aircraft), validated by OpenFOAM simulations and miniature wind-tunnel tests with 3D-printed prototypes, demonstrate consistent gains in both optimization and guided generation. Additional offline RL results further support the generality of our approach.
Nowcast3D: Reliable precipitation nowcasting via gray-box learning
Nov 06, 2025Extreme precipitation nowcasting demands high spatiotemporal fidelity and extended lead times, yet existing approaches remain limited. Numerical Weather Prediction (NWP) and its deep-learning emulations are too slow and coarse for rapidly evolving convection, while extrapolation and purely data-driven models suffer from error accumulation and excessive smoothing. Hybrid 2D radar-based methods discard crucial vertical information, preventing accurate reconstruction of height-dependent dynamics. We introduce a gray-box, fully three-dimensional nowcasting framework that directly processes volumetric radar reflectivity and couples physically constrained neural operators with datadriven learning. The model learns vertically varying 3D advection fields under a conservative advection operator, parameterizes spatially varying diffusion, and introduces a Brownian-motion--inspired stochastic term to represent unresolved motions. A residual branch captures small-scale convective initiation and microphysical variability, while a diffusion-based stochastic module estimates uncertainty. The framework achieves more accurate forecasts up to three-hour lead time across precipitation regimes and ranked first in 57\% of cases in a blind evaluation by 160 meteorologists. By restoring full 3D dynamics with physical consistency, it offers a scalable and robust pathway for skillful and reliable nowcasting of extreme precipitation.
Efficient lattice field theory simulation using adaptive normalizing flow on a resistive memory-based neural differential equation solver
Sep 16, 2025Lattice field theory (LFT) simulations underpin advances in classical statistical mechanics and quantum field theory, providing a unified computational framework across particle, nuclear, and condensed matter physics. However, the application of these methods to high-dimensional systems remains severely constrained by several challenges, including the prohibitive computational cost and limited parallelizability of conventional sampling algorithms such as hybrid Monte Carlo (HMC), the substantial training expense associated with traditional normalizing flow models, and the inherent energy inefficiency of digital hardware architectures. Here, we introduce a software-hardware co-design that integrates an adaptive normalizing flow (ANF) model with a resistive memory-based neural differential equation solver, enabling efficient generation of LFT configurations. Software-wise, ANF enables efficient parallel generation of statistically independent configurations, thereby reducing computational costs, while low-rank adaptation (LoRA) allows cost-effective fine-tuning across diverse simulation parameters. Hardware-wise, in-memory computing with resistive memory substantially enhances both parallelism and energy efficiency. We validate our approach on the scalar phi4 theory and the effective field theory of graphene wires, using a hybrid analog-digital neural differential equation solver equipped with a 180 nm resistive memory in-memory computing macro. Our co-design enables low-cost computation, achieving approximately 8.2-fold and 13.9-fold reductions in integrated autocorrelation time over HMC, while requiring fine-tuning of less than 8% of the weights via LoRA. Compared to state-of-the-art GPUs, our co-design achieves up to approximately 16.1- and 17.0-fold speedups for the two tasks, as well as 73.7- and 138.0-fold improvements in energy efficiency.
Data-driven solar forecasting enables near-optimal economic decisions
Sep 08, 2025Solar energy adoption is critical to achieving net-zero emissions. However, it remains difficult for many industrial and commercial actors to decide on whether they should adopt distributed solar-battery systems, which is largely due to the unavailability of fast, low-cost, and high-resolution irradiance forecasts. Here, we present SunCastNet, a lightweight data-driven forecasting system that provides 0.05$^\circ$, 10-minute resolution predictions of surface solar radiation downwards (SSRD) up to 7 days ahead. SunCastNet, coupled with reinforcement learning (RL) for battery scheduling, reduces operational regret by 76--93\% compared to robust decision making (RDM). In 25-year investment backtests, it enables up to five of ten high-emitting industrial sectors per region to cross the commercial viability threshold of 12\% Internal Rate of Return (IRR). These results show that high-resolution, long-horizon solar forecasts can directly translate into measurable economic gains, supporting near-optimal energy operations and accelerating renewable deployment.
SlotPi: Physics-informed Object-centric Reasoning Models
Jun 12, 2025Understanding and reasoning about dynamics governed by physical laws through visual observation, akin to human capabilities in the real world, poses significant challenges. Currently, object-centric dynamic simulation methods, which emulate human behavior, have achieved notable progress but overlook two critical aspects: 1) the integration of physical knowledge into models. Humans gain physical insights by observing the world and apply this knowledge to accurately reason about various dynamic scenarios; 2) the validation of model adaptability across diverse scenarios. Real-world dynamics, especially those involving fluids and objects, demand models that not only capture object interactions but also simulate fluid flow characteristics. To address these gaps, we introduce SlotPi, a slot-based physics-informed object-centric reasoning model. SlotPi integrates a physical module based on Hamiltonian principles with a spatio-temporal prediction module for dynamic forecasting. Our experiments highlight the model's strengths in tasks such as prediction and Visual Question Answering (VQA) on benchmark and fluid datasets. Furthermore, we have created a real-world dataset encompassing object interactions, fluid dynamics, and fluid-object interactions, on which we validated our model's capabilities. The model's robust performance across all datasets underscores its strong adaptability, laying a foundation for developing more advanced world models.
Are High-Degree Representations Really Unnecessary in Equivariant Graph Neural Networks?
Oct 15, 2024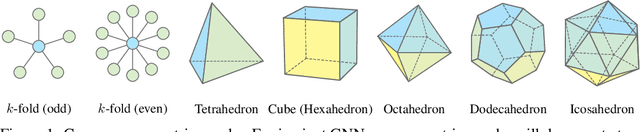
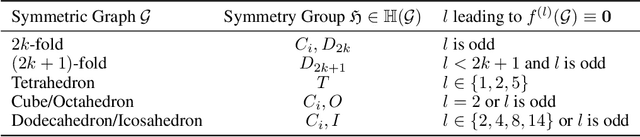
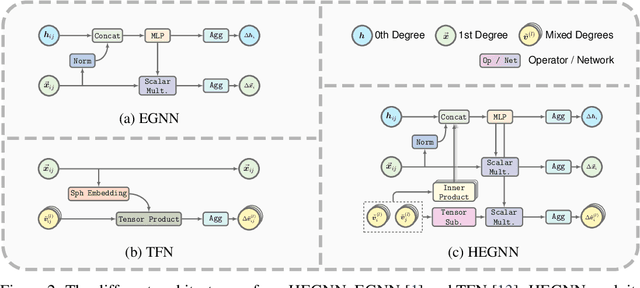
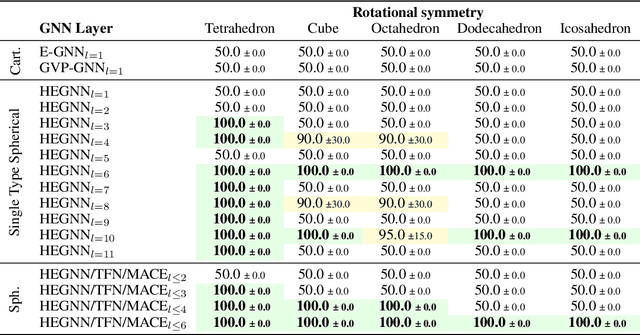
Equivariant Graph Neural Networks (GNNs) that incorporate E(3) symmetry have achieved significant success in various scientific applications. As one of the most successful models, EGNN leverages a simple scalarization technique to perform equivariant message passing over only Cartesian vectors (i.e., 1st-degree steerable vectors), enjoying greater efficiency and efficacy compared to equivariant GNNs using higher-degree steerable vectors. This success suggests that higher-degree representations might be unnecessary. In this paper, we disprove this hypothesis by exploring the expressivity of equivariant GNNs on symmetric structures, including $k$-fold rotations and regular polyhedra. We theoretically demonstrate that equivariant GNNs will always degenerate to a zero function if the degree of the output representations is fixed to 1 or other specific values. Based on this theoretical insight, we propose HEGNN, a high-degree version of EGNN to increase the expressivity by incorporating high-degree steerable vectors while maintaining EGNN's efficiency through the scalarization trick. Our extensive experiments demonstrate that HEGNN not only aligns with our theoretical analyses on toy datasets consisting of symmetric structures, but also shows substantial improvements on more complicated datasets such as $N$-body and MD17. Our theoretical findings and empirical results potentially open up new possibilities for the research of equivariant GNNs.
RNC: Efficient RRAM-aware NAS and Compilation for DNNs on Resource-Constrained Edge Devices
Sep 27, 2024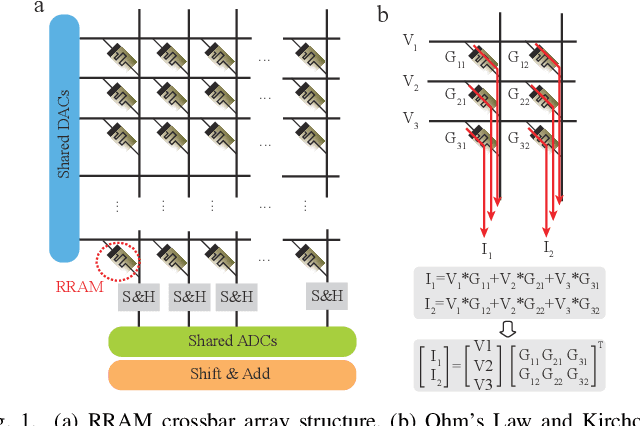
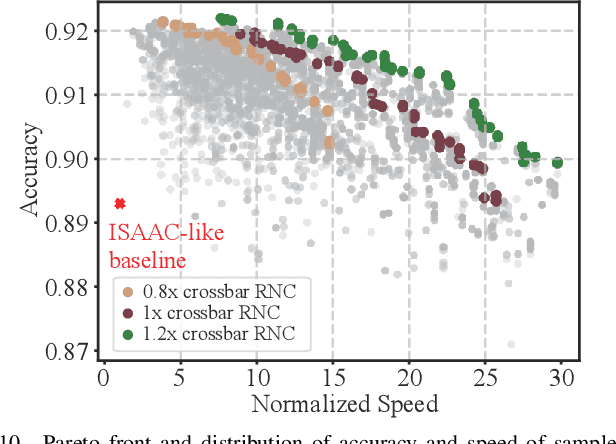
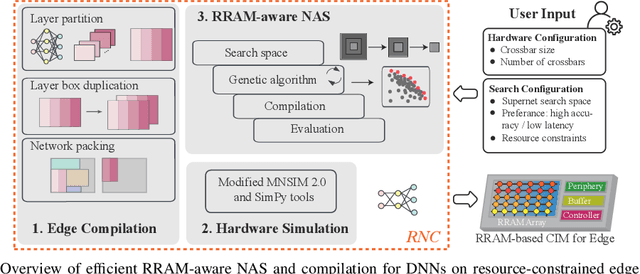
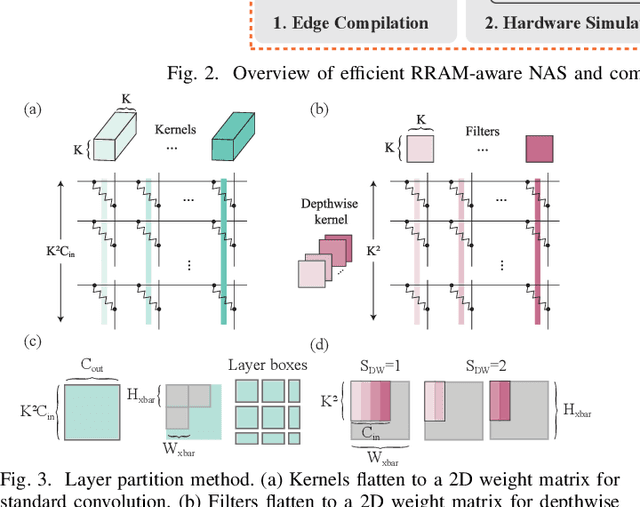
Computing-in-memory (CIM) is an emerging computing paradigm, offering noteworthy potential for accelerating neural networks with high parallelism, low latency, and energy efficiency compared to conventional von Neumann architectures. However, existing research has primarily focused on hardware architecture and network co-design for large-scale neural networks, without considering resource constraints. In this study, we aim to develop edge-friendly deep neural networks (DNNs) for accelerators based on resistive random-access memory (RRAM). To achieve this, we propose an edge compilation and resource-constrained RRAM-aware neural architecture search (NAS) framework to search for optimized neural networks meeting specific hardware constraints. Our compilation approach integrates layer partitioning, duplication, and network packing to maximize the utilization of computation units. The resulting network architecture can be optimized for either high accuracy or low latency using a one-shot neural network approach with Pareto optimality achieved through the Non-dominated Sorted Genetic Algorithm II (NSGA-II). The compilation of mobile-friendly networks, like Squeezenet and MobilenetV3 small can achieve over 80% of utilization and over 6x speedup compared to ISAAC-like framework with different crossbar resources. The resulting model from NAS optimized for speed achieved 5x-30x speedup. The code for this paper is available at https://github.com/ArChiiii/rram_nas_comp_pack.
Topology Optimization of Random Memristors for Input-Aware Dynamic SNN
Jul 26, 2024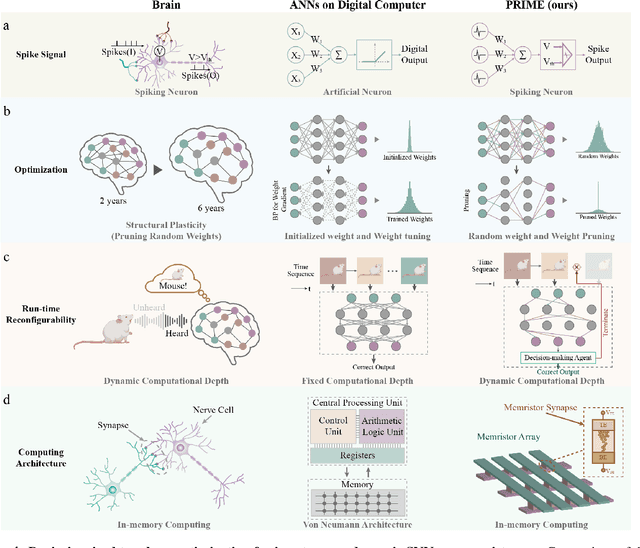
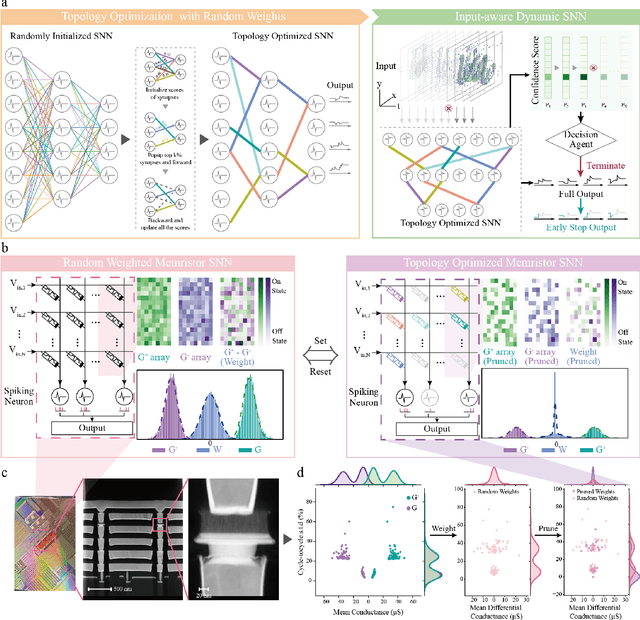
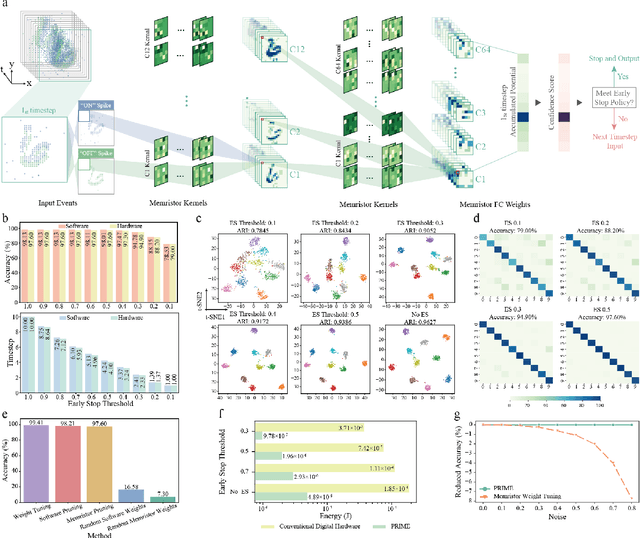
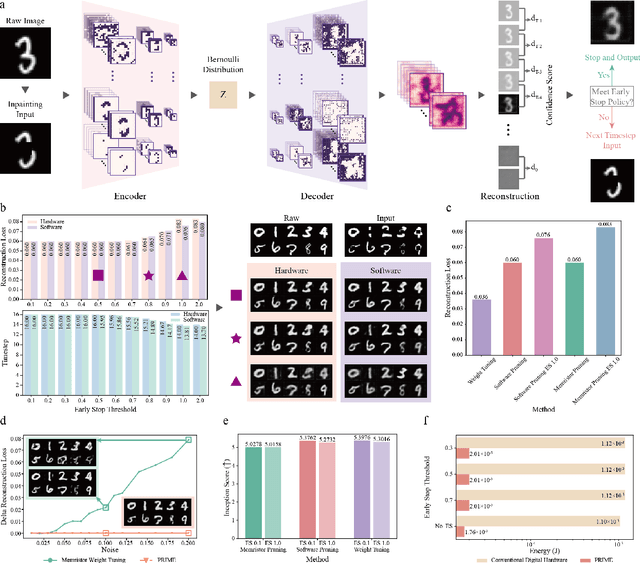
There is unprecedented development in machine learning, exemplified by recent large language models and world simulators, which are artificial neural networks running on digital computers. However, they still cannot parallel human brains in terms of energy efficiency and the streamlined adaptability to inputs of different difficulties, due to differences in signal representation, optimization, run-time reconfigurability, and hardware architecture. To address these fundamental challenges, we introduce pruning optimization for input-aware dynamic memristive spiking neural network (PRIME). Signal representation-wise, PRIME employs leaky integrate-and-fire neurons to emulate the brain's inherent spiking mechanism. Drawing inspiration from the brain's structural plasticity, PRIME optimizes the topology of a random memristive spiking neural network without expensive memristor conductance fine-tuning. For runtime reconfigurability, inspired by the brain's dynamic adjustment of computational depth, PRIME employs an input-aware dynamic early stop policy to minimize latency during inference, thereby boosting energy efficiency without compromising performance. Architecture-wise, PRIME leverages memristive in-memory computing, mirroring the brain and mitigating the von Neumann bottleneck. We validated our system using a 40 nm 256 Kb memristor-based in-memory computing macro on neuromorphic image classification and image inpainting. Our results demonstrate the classification accuracy and Inception Score are comparable to the software baseline, while achieving maximal 62.50-fold improvements in energy efficiency, and maximal 77.0% computational load savings. The system also exhibits robustness against stochastic synaptic noise of analogue memristors. Our software-hardware co-designed model paves the way to future brain-inspired neuromorphic computing with brain-like energy efficiency and adaptivity.
Dynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024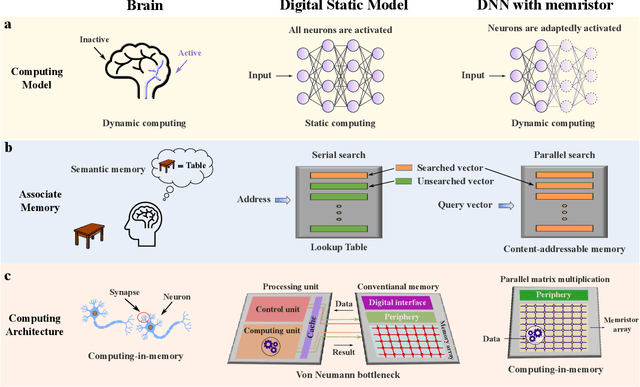
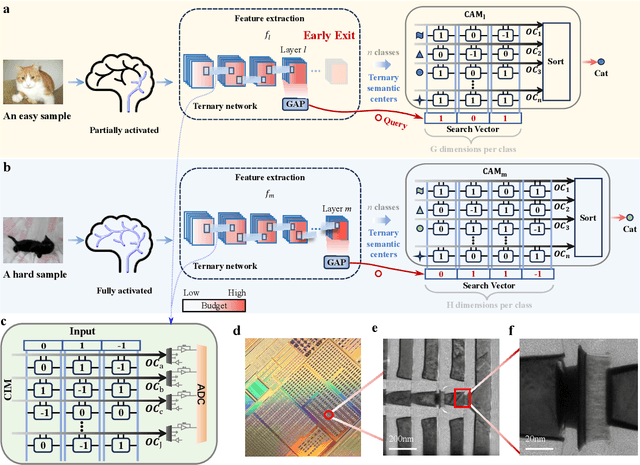
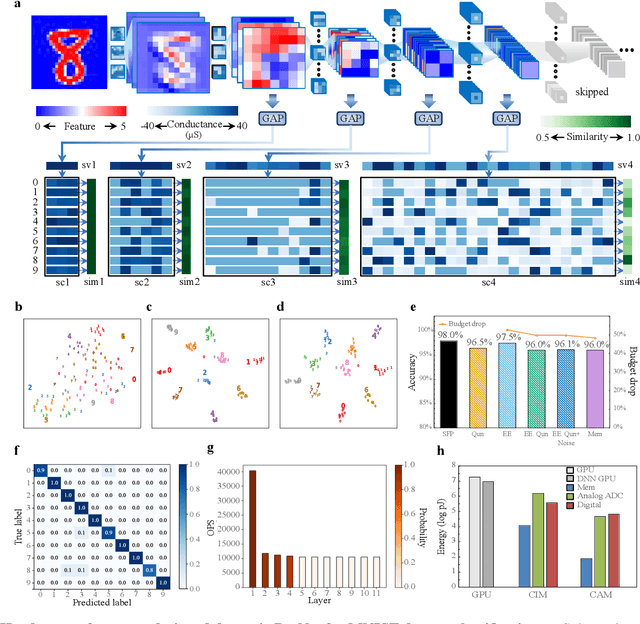
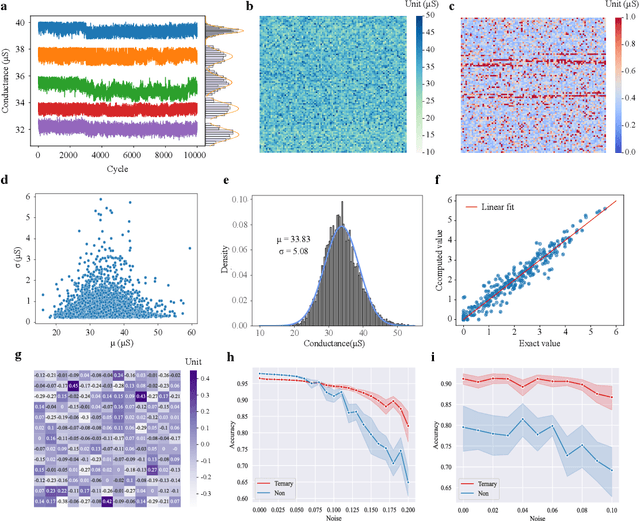
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.
Continuous-Time Digital Twin with Analogue Memristive Neural Ordinary Differential Equation Solver
Jun 12, 2024Digital twins, the cornerstone of Industry 4.0, replicate real-world entities through computer models, revolutionising fields such as manufacturing management and industrial automation. Recent advances in machine learning provide data-driven methods for developing digital twins using discrete-time data and finite-depth models on digital computers. However, this approach fails to capture the underlying continuous dynamics and struggles with modelling complex system behaviour. Additionally, the architecture of digital computers, with separate storage and processing units, necessitates frequent data transfers and Analogue-Digital (A/D) conversion, thereby significantly increasing both time and energy costs. Here, we introduce a memristive neural ordinary differential equation (ODE) solver for digital twins, which is capable of capturing continuous-time dynamics and facilitates the modelling of complex systems using an infinite-depth model. By integrating storage and computation within analogue memristor arrays, we circumvent the von Neumann bottleneck, thus enhancing both speed and energy efficiency. We experimentally validate our approach by developing a digital twin of the HP memristor, which accurately extrapolates its nonlinear dynamics, achieving a 4.2-fold projected speedup and a 41.4-fold projected decrease in energy consumption compared to state-of-the-art digital hardware, while maintaining an acceptable error margin. Additionally, we demonstrate scalability through experimentally grounded simulations of Lorenz96 dynamics, exhibiting projected performance improvements of 12.6-fold in speed and 189.7-fold in energy efficiency relative to traditional digital approaches. By harnessing the capabilities of fully analogue computing, our breakthrough accelerates the development of digital twins, offering an efficient and rapid solution to meet the demands of Industry 4.0.