 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFALCON: An ML Framework for Fully Automated Layout-Constrained Analog Circuit Design
May 28, 2025Designing analog circuits from performance specifications is a complex, multi-stage process encompassing topology selection, parameter inference, and layout feasibility. We introduce FALCON, a unified machine learning framework that enables fully automated, specification-driven analog circuit synthesis through topology selection and layout-constrained optimization. Given a target performance, FALCON first selects an appropriate circuit topology using a performance-driven classifier guided by human design heuristics. Next, it employs a custom, edge-centric graph neural network trained to map circuit topology and parameters to performance, enabling gradient-based parameter inference through the learned forward model. This inference is guided by a differentiable layout cost, derived from analytical equations capturing parasitic and frequency-dependent effects, and constrained by design rules. We train and evaluate FALCON on a large-scale custom dataset of 1M analog mm-wave circuits, generated and simulated using Cadence Spectre across 20 expert-designed topologies. Through this evaluation, FALCON demonstrates >99\% accuracy in topology inference, <10\% relative error in performance prediction, and efficient layout-aware design that completes in under 1 second per instance. Together, these results position FALCON as a practical and extensible foundation model for end-to-end analog circuit design automation.
One-Minute Video Generation with Test-Time Training
Apr 07, 2025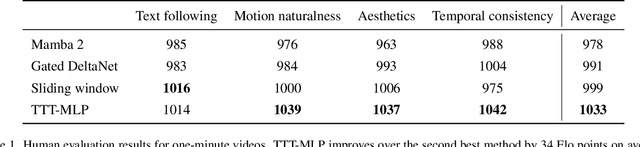
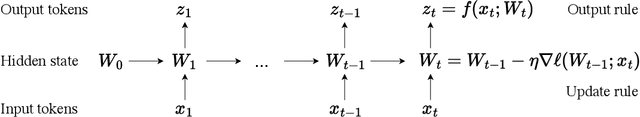
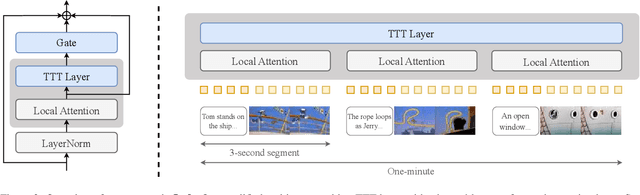
Transformers today still struggle to generate one-minute videos because self-attention layers are inefficient for long context. Alternatives such as Mamba layers struggle with complex multi-scene stories because their hidden states are less expressive. We experiment with Test-Time Training (TTT) layers, whose hidden states themselves can be neural networks, therefore more expressive. Adding TTT layers into a pre-trained Transformer enables it to generate one-minute videos from text storyboards. For proof of concept, we curate a dataset based on Tom and Jerry cartoons. Compared to baselines such as Mamba~2, Gated DeltaNet, and sliding-window attention layers, TTT layers generate much more coherent videos that tell complex stories, leading by 34 Elo points in a human evaluation of 100 videos per method. Although promising, results still contain artifacts, likely due to the limited capability of the pre-trained 5B model. The efficiency of our implementation can also be improved. We have only experimented with one-minute videos due to resource constraints, but the approach can be extended to longer videos and more complex stories. Sample videos, code and annotations are available at: https://test-time-training.github.io/video-dit
UFO: Enhancing Diffusion-Based Video Generation with a Uniform Frame Organizer
Dec 12, 2024
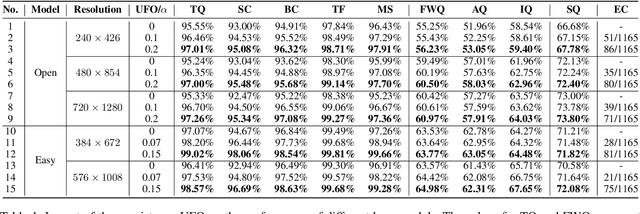
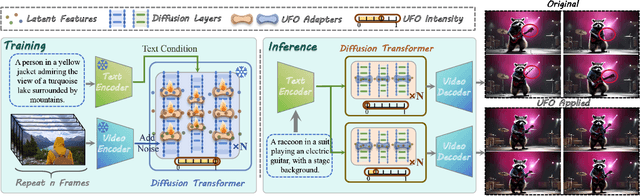
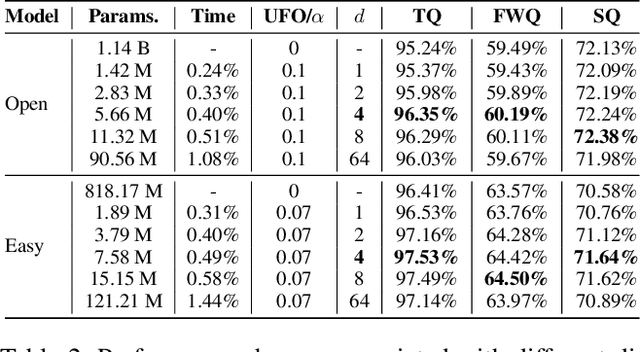
Recently, diffusion-based video generation models have achieved significant success. However, existing models often suffer from issues like weak consistency and declining image quality over time. To overcome these challenges, inspired by aesthetic principles, we propose a non-invasive plug-in called Uniform Frame Organizer (UFO), which is compatible with any diffusion-based video generation model. The UFO comprises a series of adaptive adapters with adjustable intensities, which can significantly enhance the consistency between the foreground and background of videos and improve image quality without altering the original model parameters when integrated. The training for UFO is simple, efficient, requires minimal resources, and supports stylized training. Its modular design allows for the combination of multiple UFOs, enabling the customization of personalized video generation models. Furthermore, the UFO also supports direct transferability across different models of the same specification without the need for specific retraining. The experimental results indicate that UFO effectively enhances video generation quality and demonstrates its superiority in public video generation benchmarks. The code will be publicly available at https://github.com/Delong-liu-bupt/UFO.
RNC: Efficient RRAM-aware NAS and Compilation for DNNs on Resource-Constrained Edge Devices
Sep 27, 2024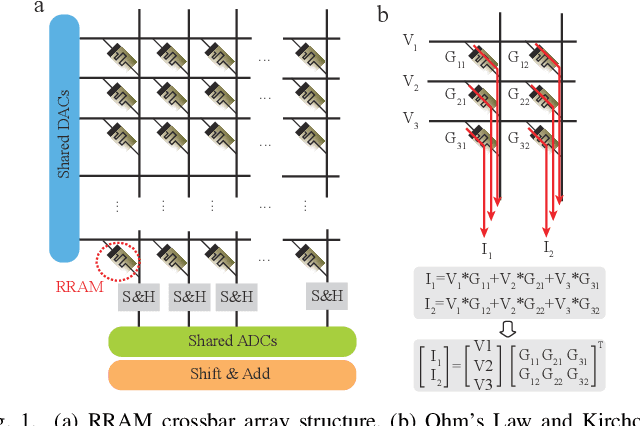
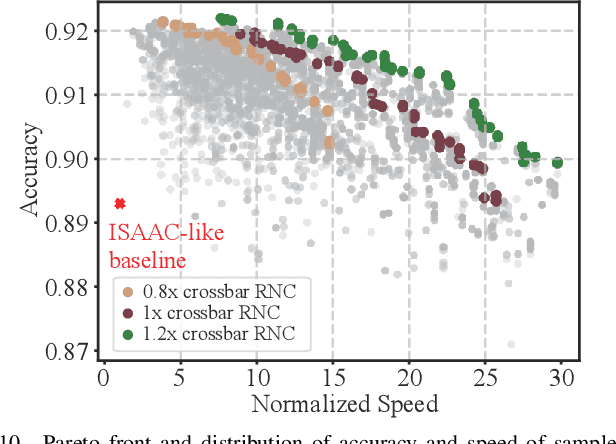
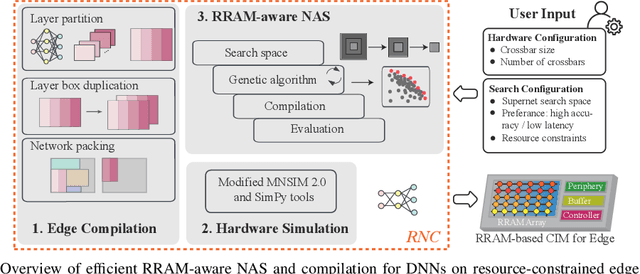
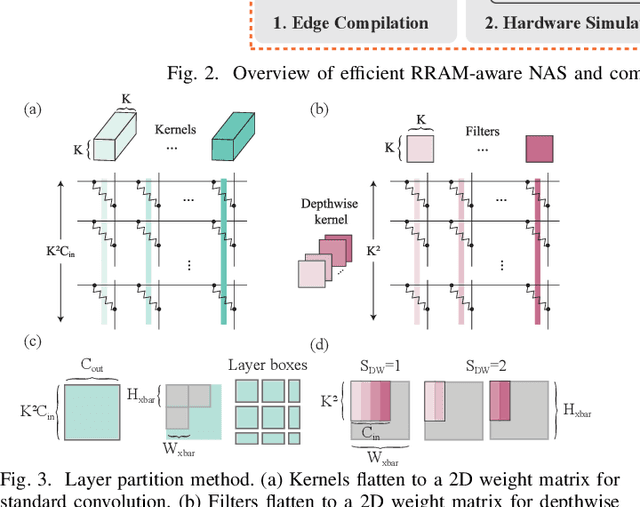
Computing-in-memory (CIM) is an emerging computing paradigm, offering noteworthy potential for accelerating neural networks with high parallelism, low latency, and energy efficiency compared to conventional von Neumann architectures. However, existing research has primarily focused on hardware architecture and network co-design for large-scale neural networks, without considering resource constraints. In this study, we aim to develop edge-friendly deep neural networks (DNNs) for accelerators based on resistive random-access memory (RRAM). To achieve this, we propose an edge compilation and resource-constrained RRAM-aware neural architecture search (NAS) framework to search for optimized neural networks meeting specific hardware constraints. Our compilation approach integrates layer partitioning, duplication, and network packing to maximize the utilization of computation units. The resulting network architecture can be optimized for either high accuracy or low latency using a one-shot neural network approach with Pareto optimality achieved through the Non-dominated Sorted Genetic Algorithm II (NSGA-II). The compilation of mobile-friendly networks, like Squeezenet and MobilenetV3 small can achieve over 80% of utilization and over 6x speedup compared to ISAAC-like framework with different crossbar resources. The resulting model from NAS optimized for speed achieved 5x-30x speedup. The code for this paper is available at https://github.com/ArChiiii/rram_nas_comp_pack.
KAN-HyperpointNet for Point Cloud Sequence-Based 3D Human Action Recognition
Sep 14, 2024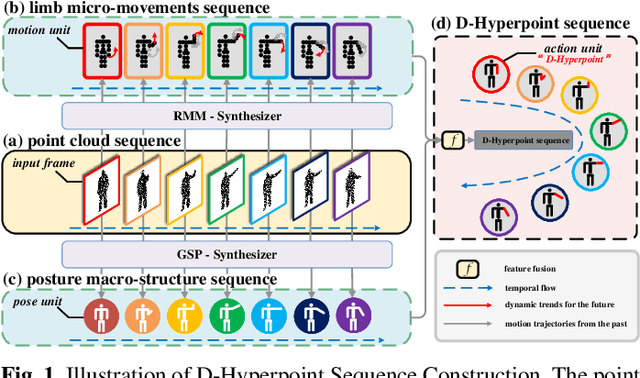
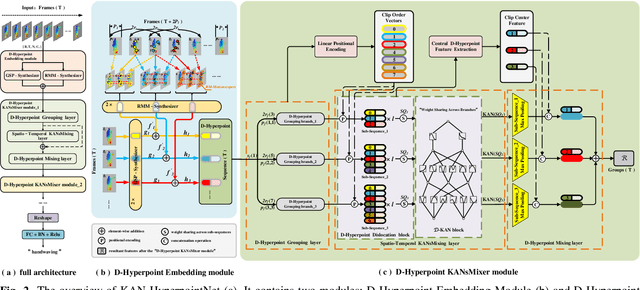
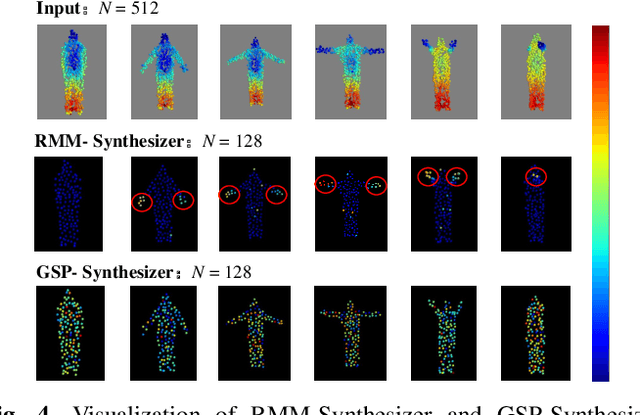
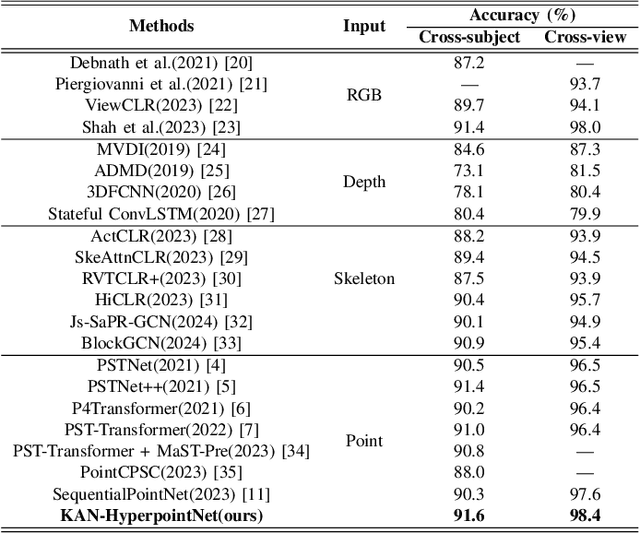
Point cloud sequence-based 3D action recognition has achieved impressive performance and efficiency. However, existing point cloud sequence modeling methods cannot adequately balance the precision of limb micro-movements with the integrity of posture macro-structure, leading to the loss of crucial information cues in action inference. To overcome this limitation, we introduce D-Hyperpoint, a novel data type generated through a D-Hyperpoint Embedding module. D-Hyperpoint encapsulates both regional-momentary motion and global-static posture, effectively summarizing the unit human action at each moment. In addition, we present a D-Hyperpoint KANsMixer module, which is recursively applied to nested groupings of D-Hyperpoints to learn the action discrimination information and creatively integrates Kolmogorov-Arnold Networks (KAN) to enhance spatio-temporal interaction within D-Hyperpoints. Finally, we propose KAN-HyperpointNet, a spatio-temporal decoupled network architecture for 3D action recognition. Extensive experiments on two public datasets: MSR Action3D and NTU-RGB+D 60, demonstrate the state-of-the-art performance of our method.
Tightly Coupled Optimization-based GPS-Visual-Inertial Odometry with Online Calibration and Initialization
Mar 05, 2022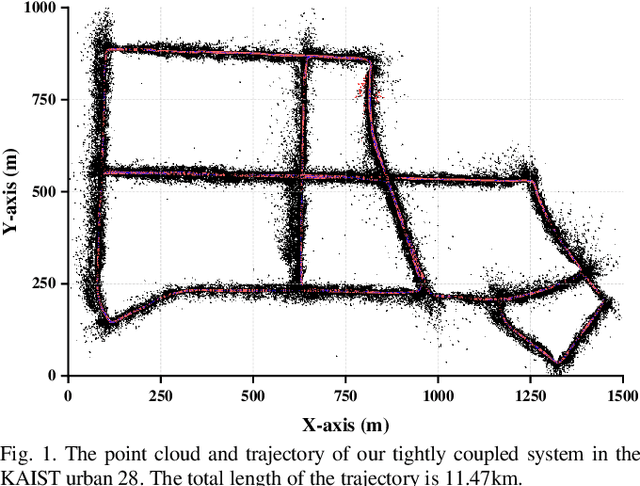
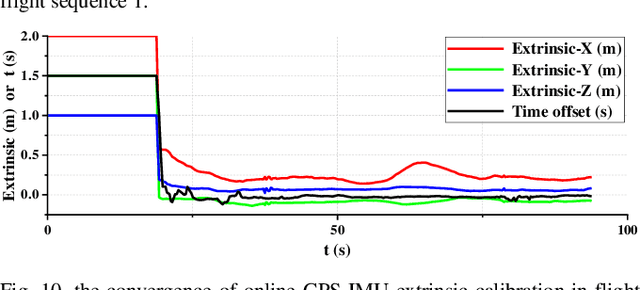
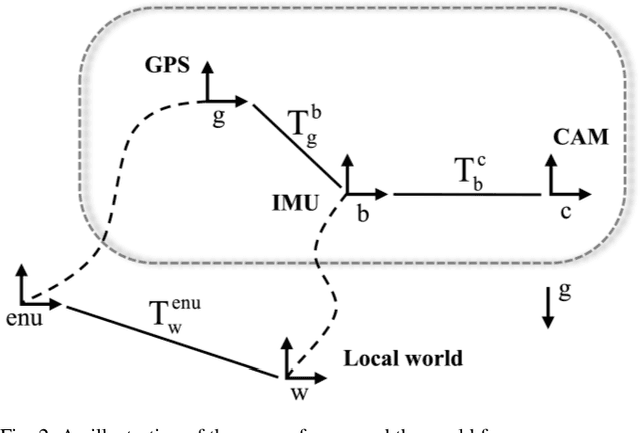
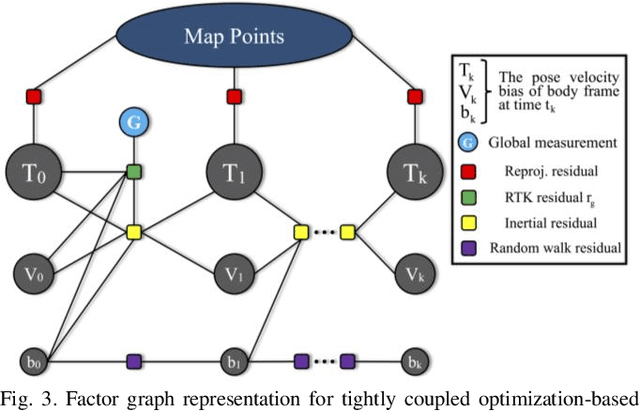
In this paper, we present a tightly coupled optimization-based GPS-Visual-Inertial odometry system to solve the trajectory drift of the visual-inertial odometry especially over long-term runs. Visual reprojection residuals, IMU residuals, and GPS measurement residuals are jointly minimized within a local bundle adjustment, in which we apply GPS measurements and IMU preintegration used for the IMU residuals to formulate a novel GPS residual. To improve the efficiency and robustness of the system, we propose a fast reference frames initialization method and an online calibration method for GPS-IMU extrinsic and time offset. In addition, we further test the performance and convergence of our online calibration method. Experimental results on EuRoC datasets show that our method consistently outperforms other tightly coupled and loosely coupled approaches. Meanwhile, this system has been validated on KAIST datasets, which proves that our system can work well in the case of visual or GPS failure.
Boosting Mobile CNN Inference through Semantic Memory
Dec 05, 2021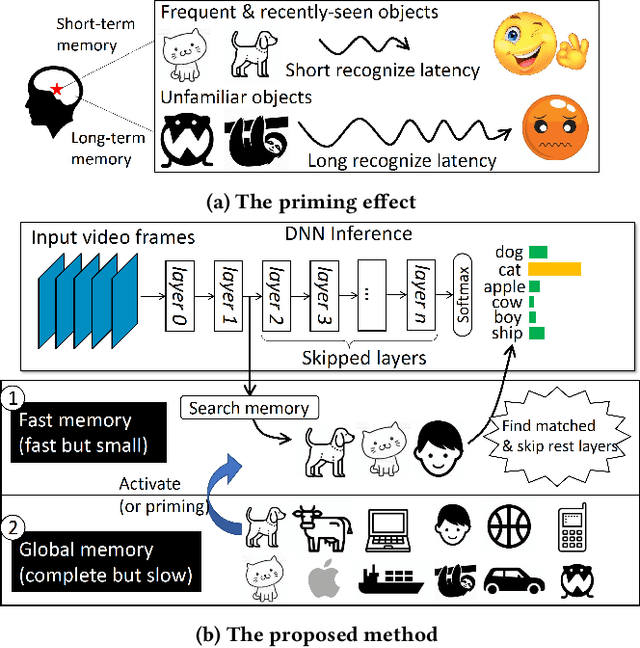
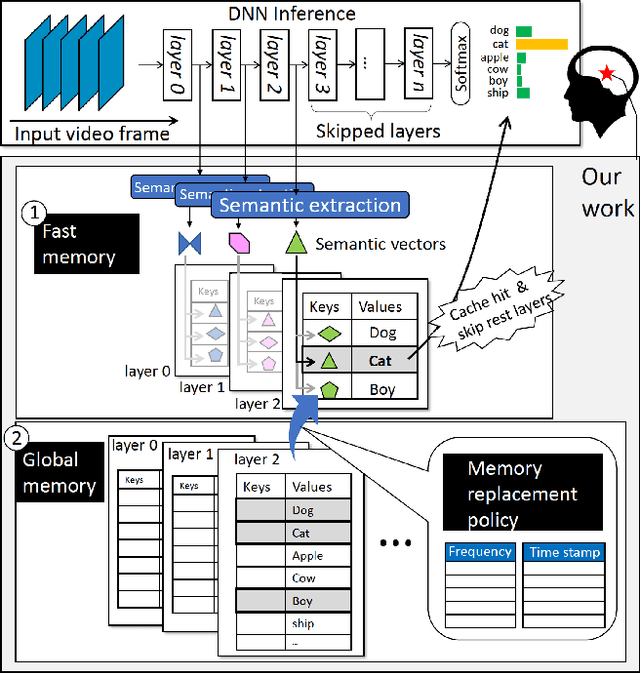
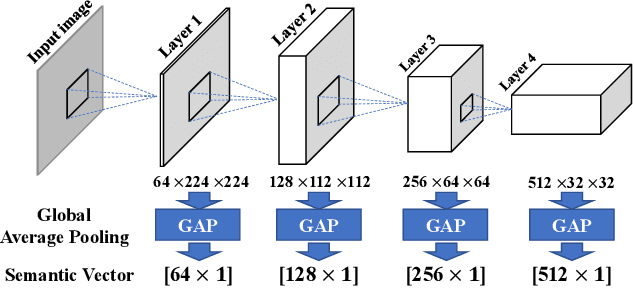
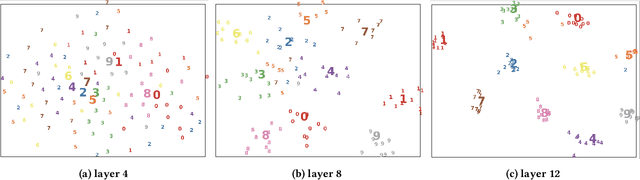
Human brains are known to be capable of speeding up visual recognition of repeatedly presented objects through faster memory encoding and accessing procedures on activated neurons. For the first time, we borrow and distill such a capability into a semantic memory design, namely SMTM, to improve on-device CNN inference. SMTM employs a hierarchical memory architecture to leverage the long-tail distribution of objects of interest, and further incorporates several novel techniques to put it into effects: (1) it encodes high-dimensional feature maps into low-dimensional, semantic vectors for low-cost yet accurate cache and lookup; (2) it uses a novel metric in determining the exit timing considering different layers' inherent characteristics; (3) it adaptively adjusts the cache size and semantic vectors to fit the scene dynamics. SMTM is prototyped on commodity CNN engine and runs on both mobile CPU and GPU. Extensive experiments on large-scale datasets and models show that SMTM can significantly speed up the model inference over standard approach (up to 2X) and prior cache designs (up to 1.5X), with acceptable accuracy loss.