 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAN-HyperpointNet for Point Cloud Sequence-Based 3D Human Action Recognition
Sep 14, 2024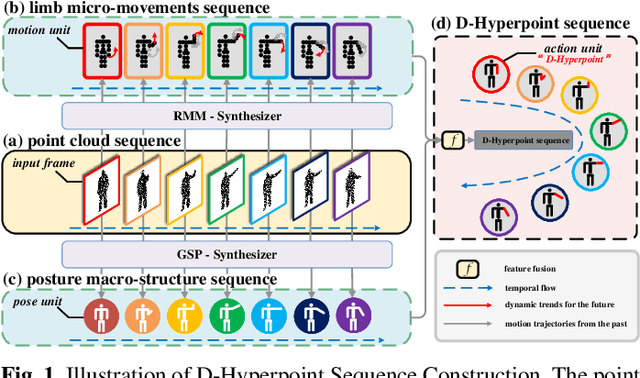
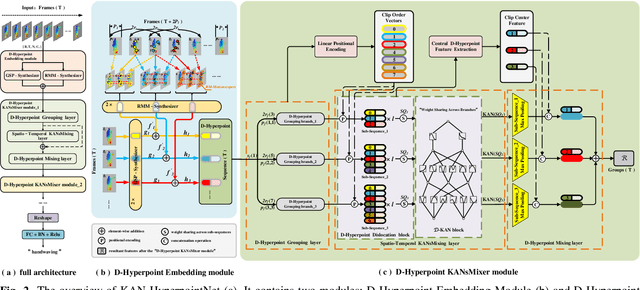
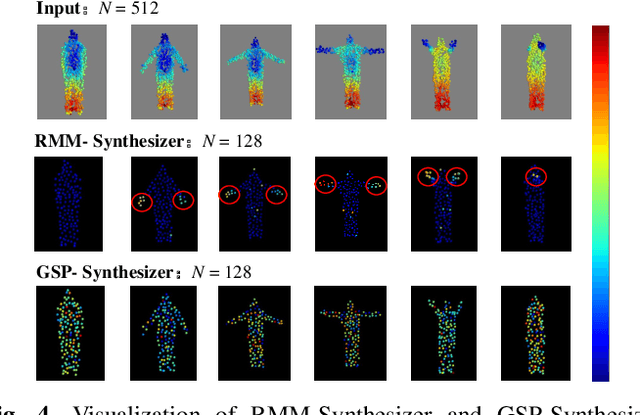
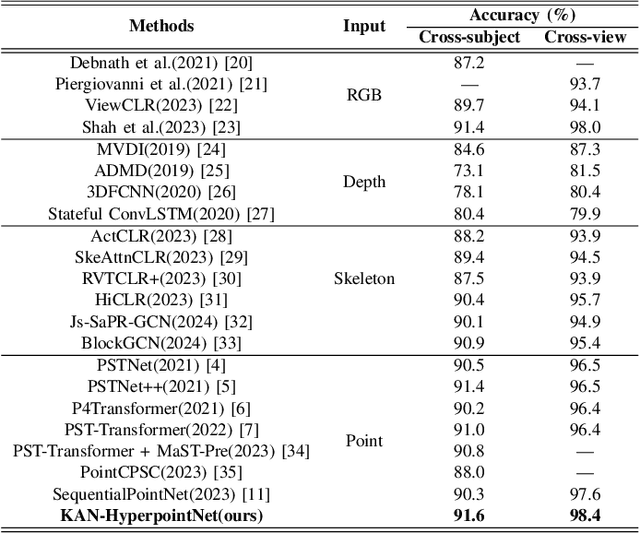
Point cloud sequence-based 3D action recognition has achieved impressive performance and efficiency. However, existing point cloud sequence modeling methods cannot adequately balance the precision of limb micro-movements with the integrity of posture macro-structure, leading to the loss of crucial information cues in action inference. To overcome this limitation, we introduce D-Hyperpoint, a novel data type generated through a D-Hyperpoint Embedding module. D-Hyperpoint encapsulates both regional-momentary motion and global-static posture, effectively summarizing the unit human action at each moment. In addition, we present a D-Hyperpoint KANsMixer module, which is recursively applied to nested groupings of D-Hyperpoints to learn the action discrimination information and creatively integrates Kolmogorov-Arnold Networks (KAN) to enhance spatio-temporal interaction within D-Hyperpoints. Finally, we propose KAN-HyperpointNet, a spatio-temporal decoupled network architecture for 3D action recognition. Extensive experiments on two public datasets: MSR Action3D and NTU-RGB+D 60, demonstrate the state-of-the-art performance of our method.
SequentialPointNet: A strong parallelized point cloud sequence network for 3D action recognition
Nov 16, 2021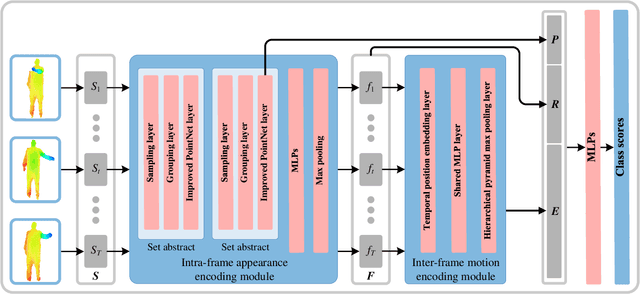
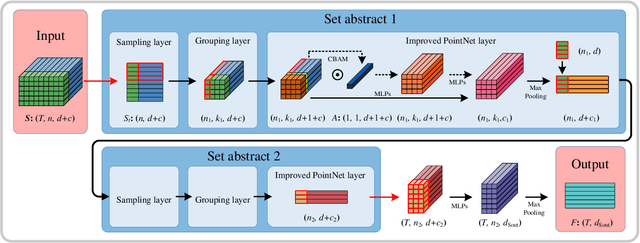
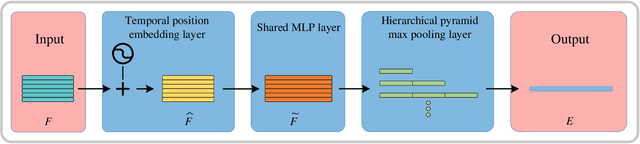

Point cloud sequences of 3D human actions exhibit unordered intra-frame spatial information and ordered interframe temporal information. In order to capture the spatiotemporal structures of the point cloud sequences, cross-frame spatio-temporal local neighborhoods around the centroids are usually constructed. However, the computationally expensive construction procedure of spatio-temporal local neighborhoods severely limits the parallelism of models. Moreover, it is unreasonable to treat spatial and temporal information equally in spatio-temporal local learning, because human actions are complicated along the spatial dimensions and simple along the temporal dimension. In this paper, to avoid spatio-temporal local encoding, we propose a strong parallelized point cloud sequence network referred to as SequentialPointNet for 3D action recognition. SequentialPointNet is composed of two serial modules, i.e., an intra-frame appearance encoding module and an inter-frame motion encoding module. For modeling the strong spatial structures of human actions, each point cloud frame is processed in parallel in the intra-frame appearance encoding module and the feature vector of each frame is output to form a feature vector sequence that characterizes static appearance changes along the temporal dimension. For modeling the weak temporal changes of human actions, in the inter-frame motion encoding module, the temporal position encoding and the hierarchical pyramid pooling strategy are implemented on the feature vector sequence. In addition, in order to better explore spatio-temporal content, multiple level features of human movements are aggregated before performing the end-to-end 3D action recognition. Extensive experiments conducted on three public datasets show that SequentialPointNet outperforms stateof-the-art approaches.