 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePig behavior dataset and Spatial-temporal perception and enhancement networks based on the attention mechanism for pig behavior recognition
Mar 12, 2025The recognition of pig behavior plays a crucial role in smart farming and welfare assurance for pigs. Currently, in the field of pig behavior recognition, the lack of publicly available behavioral datasets not only limits the development of innovative algorithms but also hampers model robustness and algorithm optimization.This paper proposes a dataset containing 13 pig behaviors that significantly impact welfare.Based on this dataset, this paper proposes a spatial-temporal perception and enhancement networks based on the attention mechanism to model the spatiotemporal features of pig behaviors and their associated interaction areas in video data. The network is composed of a spatiotemporal perception network and a spatiotemporal feature enhancement network. The spatiotemporal perception network is responsible for establishing connections between the pigs and the key regions of their behaviors in the video data. The spatiotemporal feature enhancement network further strengthens the important spatial features of individual pigs and captures the long-term dependencies of the spatiotemporal features of individual behaviors by remodeling these connections, thereby enhancing the model's perception of spatiotemporal changes in pig behaviors. Experimental results demonstrate that on the dataset established in this paper, our proposed model achieves a MAP score of 75.92%, which is an 8.17% improvement over the best-performing traditional model. This study not only improces the accuracy and generalizability of individual pig behavior recognition but also provides new technological tools for modern smart farming. The dataset and related code will be made publicly available alongside this paper.
CZU-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and 10 wearable inertial sensors
Feb 07, 2022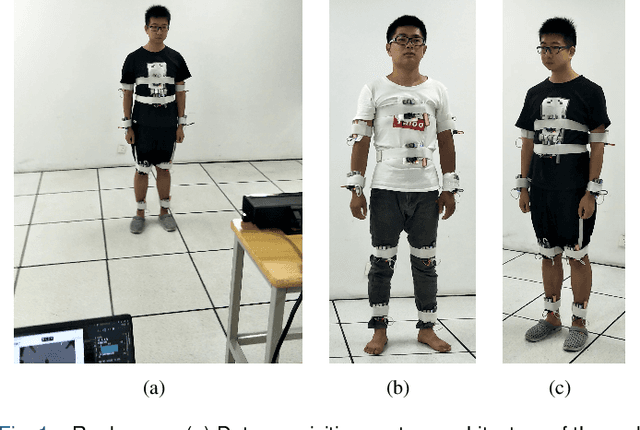
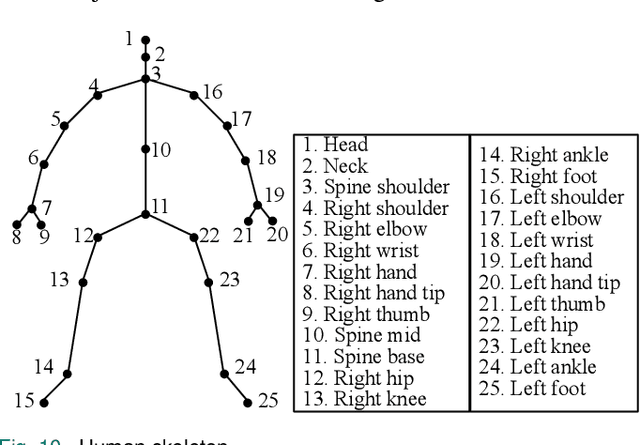
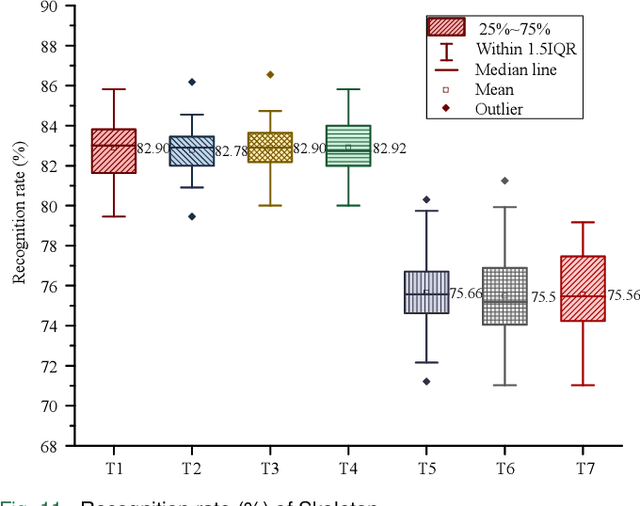
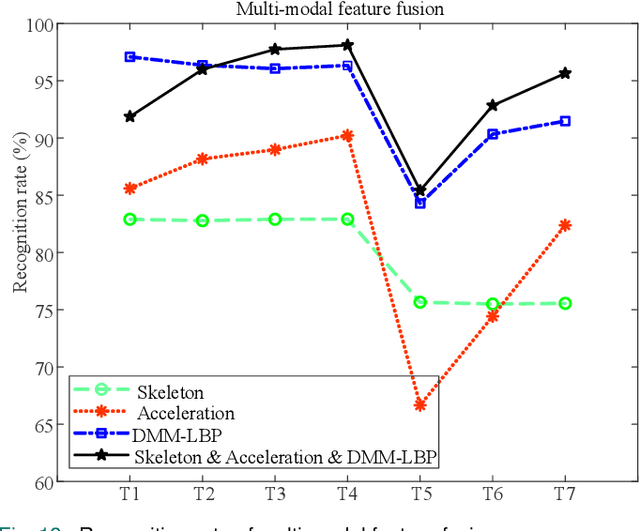
Human action recognition has been widely used in many fields of life, and many human action datasets have been published at the same time. However, most of the multi-modal databases have some shortcomings in the layout and number of sensors, which cannot fully represent the action features. Regarding the problems, this paper proposes a freely available dataset, named CZU-MHAD (Changzhou University: a comprehensive multi-modal human action dataset). It consists of 22 actions and three modals temporal synchronized data. These modals include depth videos and skeleton positions from a kinect v2 camera, and inertial signals from 10 wearable sensors. Compared with single modal sensors, multi-modal sensors can collect different modal data, so the use of multi-modal sensors can describe actions more accurately. Moreover, CZU-MHAD obtains the 3-axis acceleration and 3-axis angular velocity of 10 main motion joints by binding inertial sensors to them, and these data were captured at the same time. Experimental results are provided to show that this dataset can be used to study structural relationships between different parts of the human body when performing actions and fusion approaches that involve multi-modal sensor data.
SequentialPointNet: A strong parallelized point cloud sequence network for 3D action recognition
Nov 16, 2021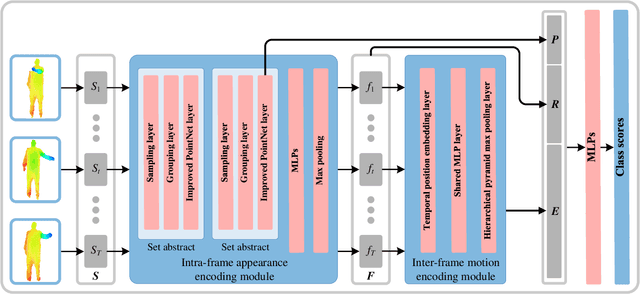
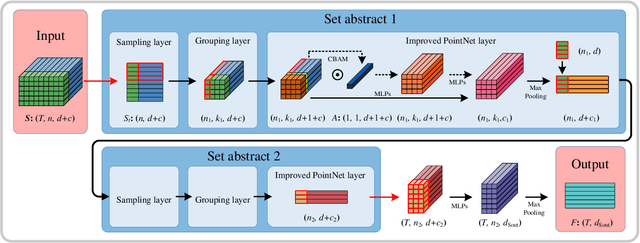
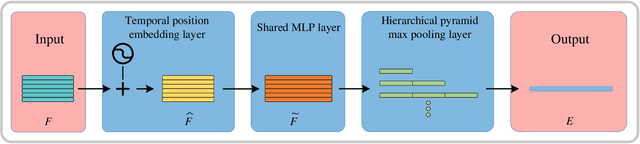

Point cloud sequences of 3D human actions exhibit unordered intra-frame spatial information and ordered interframe temporal information. In order to capture the spatiotemporal structures of the point cloud sequences, cross-frame spatio-temporal local neighborhoods around the centroids are usually constructed. However, the computationally expensive construction procedure of spatio-temporal local neighborhoods severely limits the parallelism of models. Moreover, it is unreasonable to treat spatial and temporal information equally in spatio-temporal local learning, because human actions are complicated along the spatial dimensions and simple along the temporal dimension. In this paper, to avoid spatio-temporal local encoding, we propose a strong parallelized point cloud sequence network referred to as SequentialPointNet for 3D action recognition. SequentialPointNet is composed of two serial modules, i.e., an intra-frame appearance encoding module and an inter-frame motion encoding module. For modeling the strong spatial structures of human actions, each point cloud frame is processed in parallel in the intra-frame appearance encoding module and the feature vector of each frame is output to form a feature vector sequence that characterizes static appearance changes along the temporal dimension. For modeling the weak temporal changes of human actions, in the inter-frame motion encoding module, the temporal position encoding and the hierarchical pyramid pooling strategy are implemented on the feature vector sequence. In addition, in order to better explore spatio-temporal content, multiple level features of human movements are aggregated before performing the end-to-end 3D action recognition. Extensive experiments conducted on three public datasets show that SequentialPointNet outperforms stateof-the-art approaches.