 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePig behavior dataset and Spatial-temporal perception and enhancement networks based on the attention mechanism for pig behavior recognition
Mar 12, 2025The recognition of pig behavior plays a crucial role in smart farming and welfare assurance for pigs. Currently, in the field of pig behavior recognition, the lack of publicly available behavioral datasets not only limits the development of innovative algorithms but also hampers model robustness and algorithm optimization.This paper proposes a dataset containing 13 pig behaviors that significantly impact welfare.Based on this dataset, this paper proposes a spatial-temporal perception and enhancement networks based on the attention mechanism to model the spatiotemporal features of pig behaviors and their associated interaction areas in video data. The network is composed of a spatiotemporal perception network and a spatiotemporal feature enhancement network. The spatiotemporal perception network is responsible for establishing connections between the pigs and the key regions of their behaviors in the video data. The spatiotemporal feature enhancement network further strengthens the important spatial features of individual pigs and captures the long-term dependencies of the spatiotemporal features of individual behaviors by remodeling these connections, thereby enhancing the model's perception of spatiotemporal changes in pig behaviors. Experimental results demonstrate that on the dataset established in this paper, our proposed model achieves a MAP score of 75.92%, which is an 8.17% improvement over the best-performing traditional model. This study not only improces the accuracy and generalizability of individual pig behavior recognition but also provides new technological tools for modern smart farming. The dataset and related code will be made publicly available alongside this paper.
ROI-based Robotic Grasp Detection for Object Overlapping Scenes
Mar 14, 2019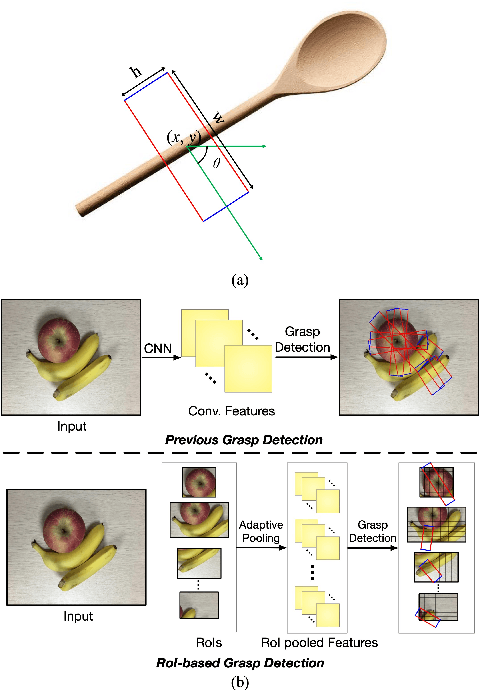
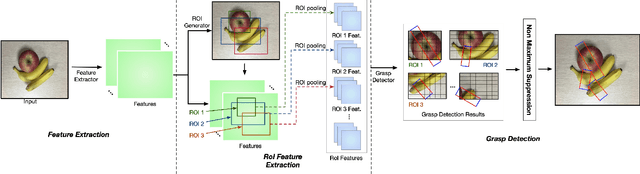
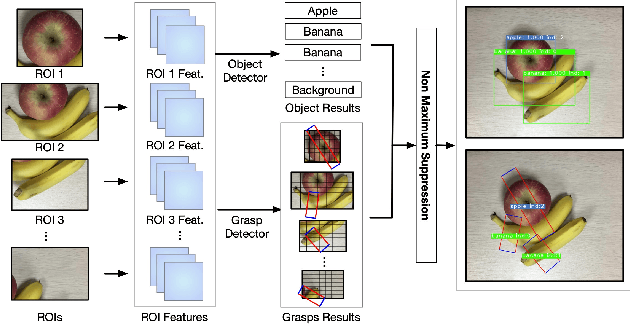

Grasp detection with consideration of the affiliations between grasps and their owner in object overlapping scenes is a necessary and challenging task for the practical use of the robotic grasping approach. In this paper, a robotic grasp detection algorithm named ROI-GD is proposed to provide a feasible solution to this problem based on Region of Interest (ROI), which is the region proposal for objects. ROI-GD uses features from ROIs to detect grasps instead of the whole scene. It has two stages: the first stage is to provide ROIs in the input image and the second-stage is the grasp detector based on ROI features. We also contribute a multi-object grasp dataset, which is much larger than Cornell Grasp Dataset, by labeling Visual Manipulation Relationship Dataset. Experimental results demonstrate that ROI-GD performs much better in object overlapping scenes and at the meantime, remains comparable with state-of-the-art grasp detection algorithms on Cornell Grasp Dataset and Jacquard Dataset. Robotic experiments demonstrate that ROI-GD can help robots grasp the target in single-object and multi-object scenes with the overall success rates of 92.5% and 83.8% respectively.
A Real-time Robotic Grasp Approach with Oriented Anchor Box
Sep 18, 2018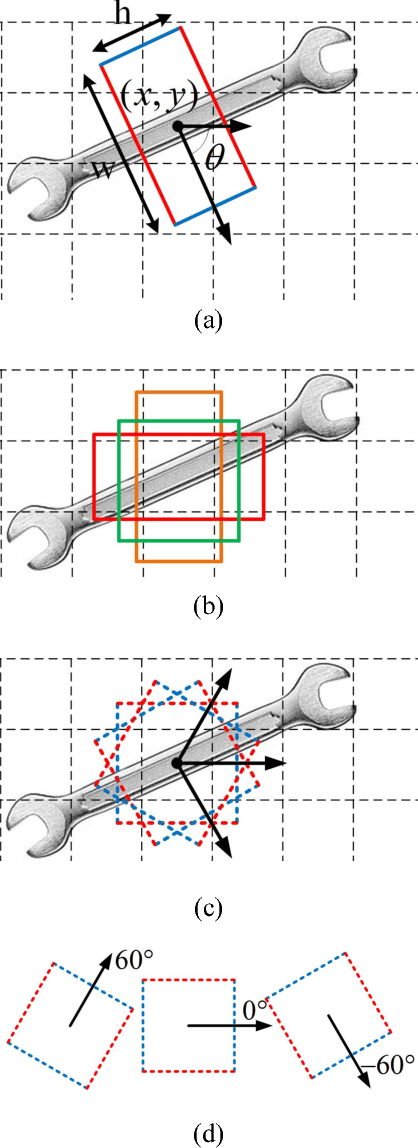
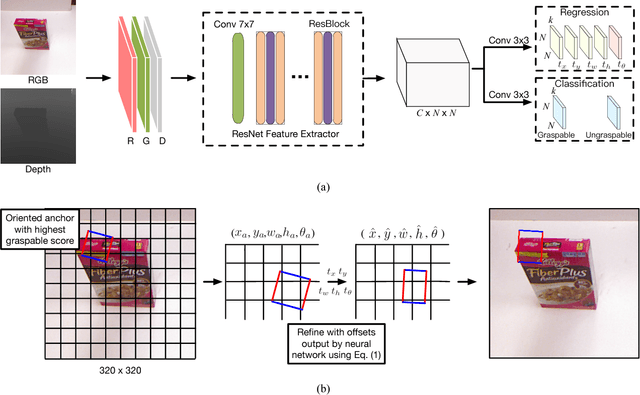
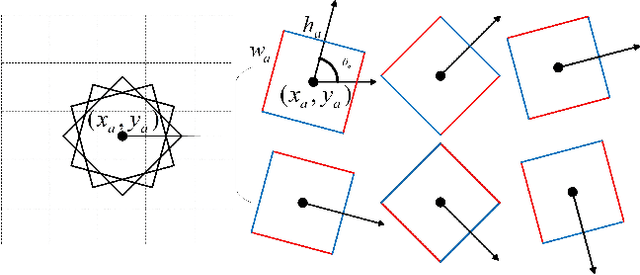

Grasp is an essential skill for robots to interact with humans and the environment. In this paper, we build a vision-based, robust and real-time robotic grasp approach with fully convolutional neural network. The main component of our approach is a grasp detection network with oriented anchor boxes as detection priors. Because the orientation of detected grasps is significant, which determines the rotation angle configuration of the gripper, we propose the Orientation Anchor Box Mechanism to regress grasp angle based on predefined assumption instead of classification or regression without any priors. With oriented anchor boxes, the grasps can be predicted more accurately and efficiently. Besides, to accelerate the network training and further improve the performance of angle regression, Angle Matching is proposed during training instead of Jaccard Index Matching. Five-fold cross validation results demonstrate that our proposed algorithm achieves an accuracy of 98.8% and 97.8% in image-wise split and object-wise split respectively, and the speed of our detection algorithm is 67 FPS with GTX 1080Ti, outperforming all the current state-of-the-art grasp detection algorithms on Cornell Dataset both in speed and accuracy. Robotic experiments demonstrate the robustness and generalization ability in unseen objects and real-world environment, with the average success rate of 90.0% and 84.2% of familiar things and unseen things respectively on Baxter robot platform.
Fully Convolutional Grasp Detection Network with Oriented Anchor Box
Mar 06, 2018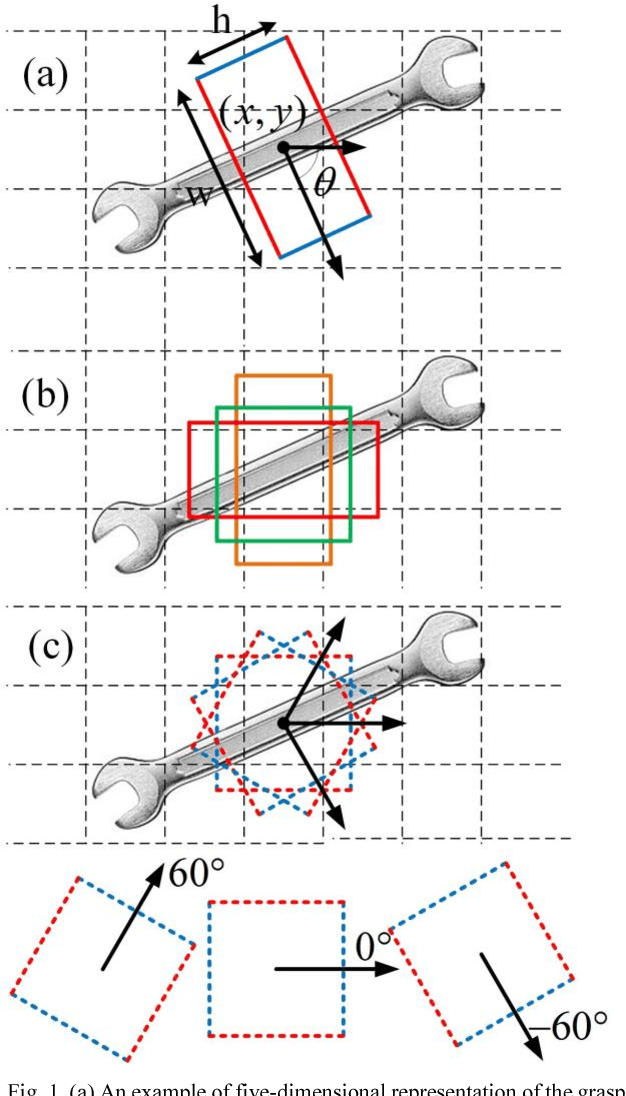
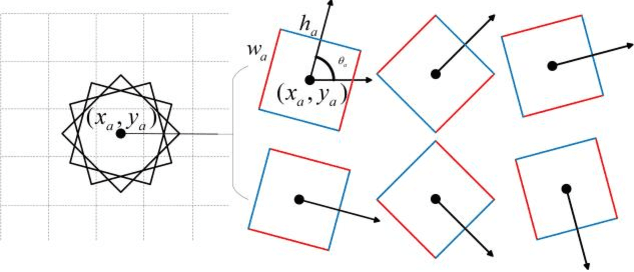
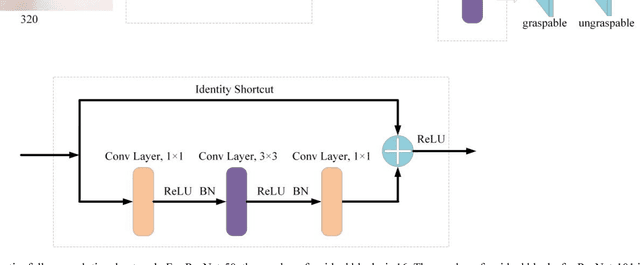

In this paper, we present a real-time approach to predict multiple grasping poses for a parallel-plate robotic gripper using RGB images. A model with oriented anchor box mechanism is proposed and a new matching strategy is used during the training process. An end-to-end fully convolutional neural network is employed in our work. The network consists of two parts: the feature extractor and multi-grasp predictor. The feature extractor is a deep convolutional neural network. The multi-grasp predictor regresses grasp rectangles from predefined oriented rectangles, called oriented anchor boxes, and classifies the rectangles into graspable and ungraspable. On the standard Cornell Grasp Dataset, our model achieves an accuracy of 97.74% and 96.61% on image-wise split and object-wise split respectively, and outperforms the latest state-of-the-art approach by 1.74% on image-wise split and 0.51% on object-wise split.
Visual Manipulation Relationship Network
Mar 02, 2018
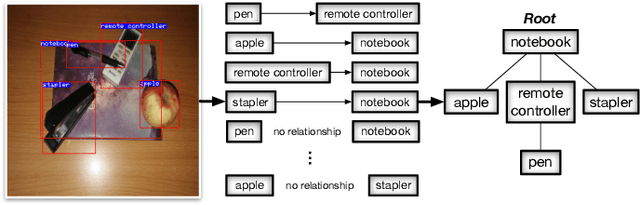
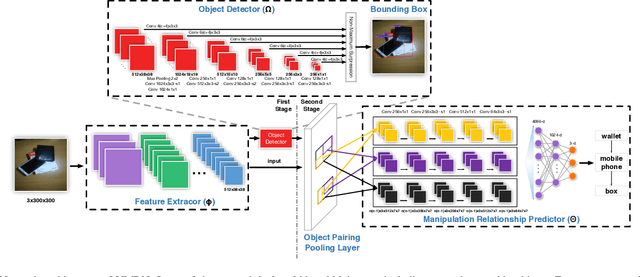
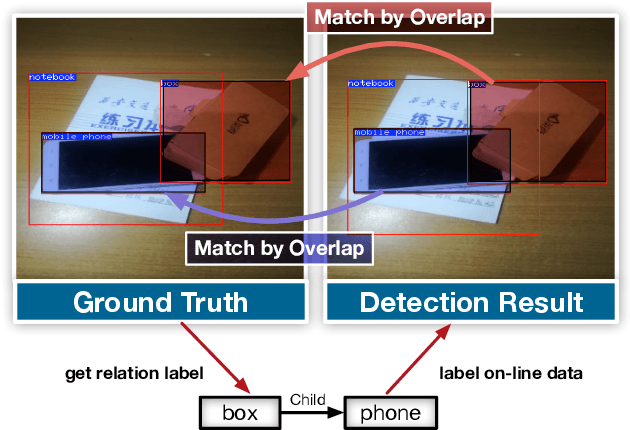
Robotic grasping detection is one of the most important fields in robotics, in which great progress has been made recent years with the help of convolutional neural network (CNN). However, including multiple objects in one scene can invalidate the existing CNN-based grasping detection algorithms, because manipulation relationships among objects are not considered, which are required to guide the robot to grasp things in the right order. This paper presents a new CNN architecture called Visual Manipulation Relationship Network (VMRN) to help robot detect targets and predict the manipulation relationships in real time. To implement end-to-end training and meet real-time requirements in robot tasks, we propose the Object Pairing Pooling Layer (OP2L) to help to predict all manipulation relationships in one forward process. Moreover, in order to train VMRN, we collect a dataset named Visual Manipulation Relationship Dataset (VMRD) consisting of 5185 images with more than 17000 object instances and the manipulation relationships between all possible pairs of objects in every image, which is labeled by the manipulation relationship tree. The experimental results show that the new network architecture can detect objects and predict manipulation relationships simultaneously and meet the real-time requirements in robot tasks.