 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGMiRAG: Intuition-Guided Retrieval-Augmented Generation with Adaptive Mining of In-Depth Memory
Feb 07, 2026Retrieval-augmented generation (RAG) equips large language models (LLMs) with reliable knowledge memory. To strengthen cross-text associations, recent research integrates graphs and hypergraphs into RAG to capture pairwise and multi-entity relations as structured links. However, their misaligned memory organization necessitates costly, disjointed retrieval. To address these limitations, we propose IGMiRAG, a framework inspired by human intuition-guided reasoning. It constructs a hierarchical heterogeneous hypergraph to align multi-granular knowledge, incorporating deductive pathways to simulate realistic memory structures. During querying, IGMiRAG distills intuitive strategies via a question parser to control mining depth and memory window, and activates instantaneous memories as anchors using dual-focus retrieval. Mirroring human intuition, the framework guides retrieval resource allocation dynamically. Furthermore, we design a bidirectional diffusion algorithm that navigates deductive paths to mine in-depth memories, emulating human reasoning processes. Extensive evaluations indicate IGMiRAG outperforms the state-of-the-art baseline by 4.8% EM and 5.0% F1 overall, with token costs adapting to task complexity (average 6.3k+, minimum 3.0k+). This work presents a cost-effective RAG paradigm that improves both efficiency and effectiveness.
MMRAG-RFT: Two-stage Reinforcement Fine-tuning for Explainable Multi-modal Retrieval-augmented Generation
Dec 19, 2025Multi-modal Retrieval-Augmented Generation (MMRAG) enables highly credible generation by integrating external multi-modal knowledge, thus demonstrating impressive performance in complex multi-modal scenarios. However, existing MMRAG methods fail to clarify the reasoning logic behind retrieval and response generation, which limits the explainability of the results. To address this gap, we propose to introduce reinforcement learning into multi-modal retrieval-augmented generation, enhancing the reasoning capabilities of multi-modal large language models through a two-stage reinforcement fine-tuning framework to achieve explainable multi-modal retrieval-augmented generation. Specifically, in the first stage, rule-based reinforcement fine-tuning is employed to perform coarse-grained point-wise ranking of multi-modal documents, effectively filtering out those that are significantly irrelevant. In the second stage, reasoning-based reinforcement fine-tuning is utilized to jointly optimize fine-grained list-wise ranking and answer generation, guiding multi-modal large language models to output explainable reasoning logic in the MMRAG process. Our method achieves state-of-the-art results on WebQA and MultimodalQA, two benchmark datasets for multi-modal retrieval-augmented generation, and its effectiveness is validated through comprehensive ablation experiments.
Cog-RAG: Cognitive-Inspired Dual-Hypergraph with Theme Alignment Retrieval-Augmented Generation
Nov 17, 2025Retrieval-Augmented Generation (RAG) enhances the response quality and domain-specific performance of large language models (LLMs) by incorporating external knowledge to combat hallucinations. In recent research, graph structures have been integrated into RAG to enhance the capture of semantic relations between entities. However, it primarily focuses on low-order pairwise entity relations, limiting the high-order associations among multiple entities. Hypergraph-enhanced approaches address this limitation by modeling multi-entity interactions via hyperedges, but they are typically constrained to inter-chunk entity-level representations, overlooking the global thematic organization and alignment across chunks. Drawing inspiration from the top-down cognitive process of human reasoning, we propose a theme-aligned dual-hypergraph RAG framework (Cog-RAG) that uses a theme hypergraph to capture inter-chunk thematic structure and an entity hypergraph to model high-order semantic relations. Furthermore, we design a cognitive-inspired two-stage retrieval strategy that first activates query-relevant thematic content from the theme hypergraph, and then guides fine-grained recall and diffusion in the entity hypergraph, achieving semantic alignment and consistent generation from global themes to local details. Our extensive experiments demonstrate that Cog-RAG significantly outperforms existing state-of-the-art baseline approaches.
* Accepted by AAAI 2026 main conference
Joint graph entropy knowledge distillation for point cloud classification and robustness against corruptions
Sep 26, 2025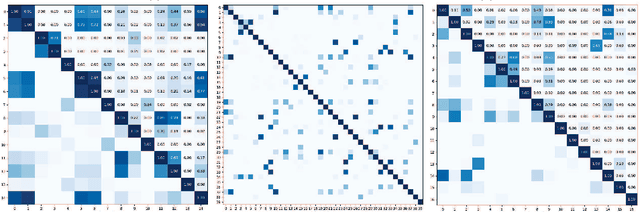



Classification tasks in 3D point clouds often assume that class events \replaced{are }{follow }independent and identically distributed (IID), although this assumption destroys the correlation between classes. This \replaced{study }{paper }proposes a classification strategy, \textbf{J}oint \textbf{G}raph \textbf{E}ntropy \textbf{K}nowledge \textbf{D}istillation (JGEKD), suitable for non-independent and identically distributed 3D point cloud data, \replaced{which }{the strategy } achieves knowledge transfer of class correlations through knowledge distillation by constructing a loss function based on joint graph entropy. First\deleted{ly}, we employ joint graphs to capture add{the }hidden relationships between classes\replaced{ and}{,} implement knowledge distillation to train our model by calculating the entropy of add{add }graph.\replaced{ Subsequently}{ Then}, to handle 3D point clouds \deleted{that is }invariant to spatial transformations, we construct \replaced{S}{s}iamese structures and develop two frameworks, self-knowledge distillation and teacher-knowledge distillation, to facilitate information transfer between different transformation forms of the same data. \replaced{In addition}{ Additionally}, we use the above framework to achieve knowledge transfer between point clouds and their corrupted forms, and increase the robustness against corruption of model. Extensive experiments on ScanObject, ModelNet40, ScanntV2\_cls and ModelNet-C demonstrate that the proposed strategy can achieve competitive results.
ERetinex: Event Camera Meets Retinex Theory for Low-Light Image Enhancement
Mar 04, 2025Low-light image enhancement aims to restore the under-exposure image captured in dark scenarios. Under such scenarios, traditional frame-based cameras may fail to capture the structure and color information due to the exposure time limitation. Event cameras are bio-inspired vision sensors that respond to pixel-wise brightness changes asynchronously. Event cameras' high dynamic range is pivotal for visual perception in extreme low-light scenarios, surpassing traditional cameras and enabling applications in challenging dark environments. In this paper, inspired by the success of the retinex theory for traditional frame-based low-light image restoration, we introduce the first methods that combine the retinex theory with event cameras and propose a novel retinex-based low-light image restoration framework named ERetinex. Among our contributions, the first is developing a new approach that leverages the high temporal resolution data from event cameras with traditional image information to estimate scene illumination accurately. This method outperforms traditional image-only techniques, especially in low-light environments, by providing more precise lighting information. Additionally, we propose an effective fusion strategy that combines the high dynamic range data from event cameras with the color information of traditional images to enhance image quality. Through this fusion, we can generate clearer and more detail-rich images, maintaining the integrity of visual information even under extreme lighting conditions. The experimental results indicate that our proposed method outperforms state-of-the-art (SOTA) methods, achieving a gain of 1.0613 dB in PSNR while reducing FLOPS by \textbf{84.28}\%.
SurroundSDF: Implicit 3D Scene Understanding Based on Signed Distance Field
Mar 21, 2024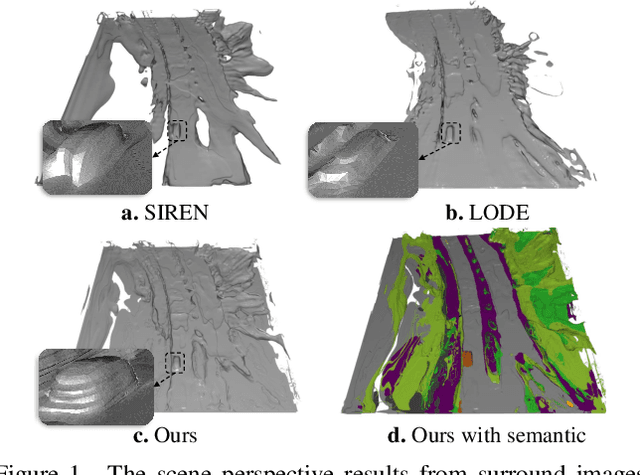



Vision-centric 3D environment understanding is both vital and challenging for autonomous driving systems. Recently, object-free methods have attracted considerable attention. Such methods perceive the world by predicting the semantics of discrete voxel grids but fail to construct continuous and accurate obstacle surfaces. To this end, in this paper, we propose SurroundSDF to implicitly predict the signed distance field (SDF) and semantic field for the continuous perception from surround images. Specifically, we introduce a query-based approach and utilize SDF constrained by the Eikonal formulation to accurately describe the surfaces of obstacles. Furthermore, considering the absence of precise SDF ground truth, we propose a novel weakly supervised paradigm for SDF, referred to as the Sandwich Eikonal formulation, which emphasizes applying correct and dense constraints on both sides of the surface, thereby enhancing the perceptual accuracy of the surface. Experiments suggest that our method achieves SOTA for both occupancy prediction and 3D scene reconstruction tasks on the nuScenes dataset.
Watch Your Head: Assembling Projection Heads to Save the Reliability of Federated Models
Feb 26, 2024Federated learning encounters substantial challenges with heterogeneous data, leading to performance degradation and convergence issues. While considerable progress has been achieved in mitigating such an impact, the reliability aspect of federated models has been largely disregarded. In this study, we conduct extensive experiments to investigate the reliability of both generic and personalized federated models. Our exploration uncovers a significant finding: \textbf{federated models exhibit unreliability when faced with heterogeneous data}, demonstrating poor calibration on in-distribution test data and low uncertainty levels on out-of-distribution data. This unreliability is primarily attributed to the presence of biased projection heads, which introduce miscalibration into the federated models. Inspired by this observation, we propose the "Assembled Projection Heads" (APH) method for enhancing the reliability of federated models. By treating the existing projection head parameters as priors, APH randomly samples multiple initialized parameters of projection heads from the prior and further performs targeted fine-tuning on locally available data under varying learning rates. Such a head ensemble introduces parameter diversity into the deterministic model, eliminating the bias and producing reliable predictions via head averaging. We evaluate the effectiveness of the proposed APH method across three prominent federated benchmarks. Experimental results validate the efficacy of APH in model calibration and uncertainty estimation. Notably, APH can be seamlessly integrated into various federated approaches but only requires less than 30\% additional computation cost for 100$\times$ inferences within large models.
Contrastive Label Enhancement
May 16, 2023
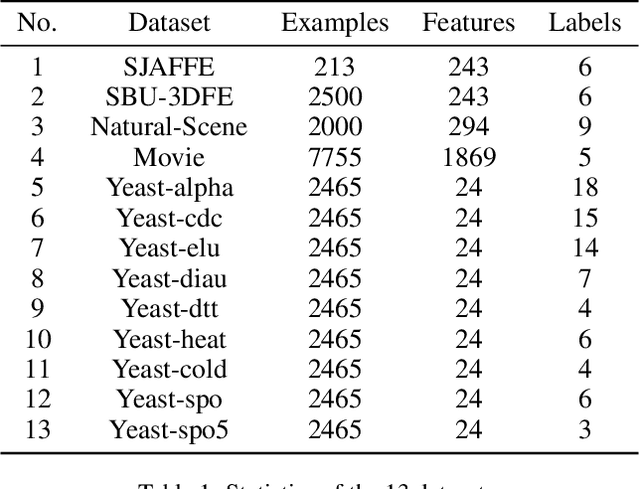
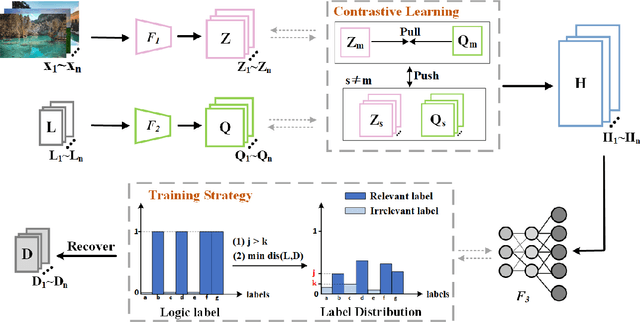

Label distribution learning (LDL) is a new machine learning paradigm for solving label ambiguity. Since it is difficult to directly obtain label distributions, many studies are focusing on how to recover label distributions from logical labels, dubbed label enhancement (LE). Existing LE methods estimate label distributions by simply building a mapping relationship between features and label distributions under the supervision of logical labels. They typically overlook the fact that both features and logical labels are descriptions of the instance from different views. Therefore, we propose a novel method called Contrastive Label Enhancement (ConLE) which integrates features and logical labels into the unified projection space to generate high-level features by contrastive learning strategy. In this approach, features and logical labels belonging to the same sample are pulled closer, while those of different samples are projected farther away from each other in the projection space. Subsequently, we leverage the obtained high-level features to gain label distributions through a welldesigned training strategy that considers the consistency of label attributes. Extensive experiments on LDL benchmark datasets demonstrate the effectiveness and superiority of our method.
HD2Reg: Hierarchical Descriptors and Detectors for Point Cloud Registration
May 05, 2023



Feature Descriptors and Detectors are two main components of feature-based point cloud registration. However, little attention has been drawn to the explicit representation of local and global semantics in the learning of descriptors and detectors. In this paper, we present a framework that explicitly extracts dual-level descriptors and detectors and performs coarse-to-fine matching with them. First, to explicitly learn local and global semantics, we propose a hierarchical contrastive learning strategy, training the robust matching ability of high-level descriptors, and refining the local feature space using low-level descriptors. Furthermore, we propose to learn dual-level saliency maps that extract two groups of keypoints in two different senses. To overcome the weak supervision of binary matchability labels, we propose a ranking strategy to label the significance ranking of keypoints, and thus provide more fine-grained supervision signals. Finally, we propose a global-to-local matching scheme to obtain robust and accurate correspondences by leveraging the complementary dual-level features.Quantitative experiments on 3DMatch and KITTI odometry datasets show that our method achieves robust and accurate point cloud registration and outperforms recent keypoint-based methods.
3DMNDT:3D multi-view registration method based on the normal distributions transform
Mar 20, 2021


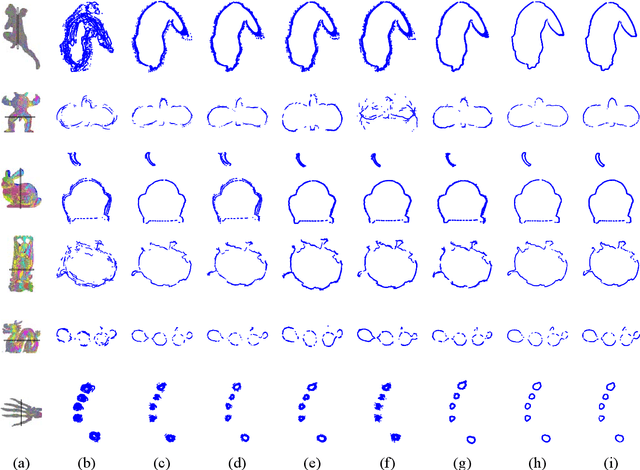
The normal distributions transform (NDT) is an effective paradigm for the point set registration. This method is originally designed for pair-wise registration and it will suffer from great challenges when applied to multi-view registration. Under the NDT framework, this paper proposes a novel multi-view registration method, named 3D multi-view registration based on the normal distributions transform (3DMNDT), which integrates the K-means clustering and Lie algebra solver to achieve multi-view registration. More specifically, the multi-view registration is cast into the problem of maximum likelihood estimation. Then, the K-means algorithm is utilized to divide all data points into different clusters, where a normal distribution is computed to locally models the probability of measuring a data point in each cluster. Subsequently, the registration problem is formulated by the NDT-based likelihood function. To maximize this likelihood function, the Lie algebra solver is developed to sequentially optimize each rigid transformation. The proposed method alternately implements data point clustering, NDT computing, and likelihood maximization until desired registration results are obtained. Experimental results tested on benchmark data sets illustrate that the proposed method can achieve state-of-the-art performance for multi-view registration.