 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGASA: Integrated Geometry-Aware and Skip-Attention Modules for Enhanced Point Cloud Registration
Mar 13, 2026Point cloud registration (PCR) is a fundamental task in 3D vision and provides essential support for applications such as autonomous driving, robotics, and environmental modeling. Despite its widespread use, existing methods often fail when facing real-world challenges like heavy noise, significant occlusions, and large-scale transformations. These limitations frequently result in compromised registration accuracy and insufficient robustness in complex environments. In this paper, we propose IGASA as a novel registration framework constructed upon a Hierarchical Pyramid Architecture (HPA) designed for robust multi-scale feature extraction and fusion. The framework integrates two pivotal components consisting of the Hierarchical Cross-Layer Attention (HCLA) module and the Iterative Geometry-Aware Refinement (IGAR) module. The HCLA module utilizes skip attention mechanisms to align multi-resolution features and enhance local geometric consistency. Simultaneously, the IGAR module is designed for the fine matching phase by leveraging reliable correspondences established during coarse matching. This synergistic integration within the architecture allows IGASA to adapt effectively to diverse point cloud structures and intricate transformations. We evaluate the performance of IGASA on four widely recognized benchmark datasets including 3D(Lo)Match, KITTI, and nuScenes. Our extensive experiments consistently demonstrate that IGASA significantly surpasses state-of-the-art methods and achieves notable improvements in registration accuracy. This work provides a robust foundation for advancing point cloud registration techniques while offering valuable insights for practical 3D vision applications. The code for IGASA is available in \href{https://github.com/DongXu-Zhang/IGASA}{https://github.com/DongXu-Zhang/IGASA}.
PointCoT: A Multi-modal Benchmark for Explicit 3D Geometric Reasoning
Feb 27, 2026While Multimodal Large Language Models (MLLMs) demonstrate proficiency in 2D scenes, extending their perceptual intelligence to 3D point cloud understanding remains a significant challenge. Current approaches focus primarily on aligning 3D features with pre-trained models. However, they typically treat geometric reasoning as an implicit mapping process. These methods bypass intermediate logical steps and consequently suffer from geometric hallucinations. They confidently generate plausible responses that fail to ground in precise structural details. To bridge this gap, we present PointCoT, a novel framework that empowers MLLMs with explicit Chain-of-Thought (CoT) reasoning for 3D data. We advocate for a \textit{Look, Think, then Answer} paradigm. In this approach, the model is supervised to generate geometry-grounded rationales before predicting final answers. To facilitate this, we construct Point-Reason-Instruct, a large-scale benchmark comprising $\sim$86k instruction-tuning samples with hierarchical CoT annotations. By leveraging a dual-stream multi-modal architecture, our method synergizes semantic appearance with geometric truth. Extensive experiments demonstrate that PointCoT achieves state-of-the-art performance on complex reasoning tasks.
Chain-of-Thought Compression Should Not Be Blind: V-Skip for Efficient Multimodal Reasoning via Dual-Path Anchoring
Jan 21, 2026While Chain-of-Thought (CoT) reasoning significantly enhances the performance of Multimodal Large Language Models (MLLMs), its autoregressive nature incurs prohibitive latency constraints. Current efforts to mitigate this via token compression often fail by blindly applying text-centric metrics to multimodal contexts. We identify a critical failure mode termed Visual Amnesia, where linguistically redundant tokens are erroneously pruned, leading to hallucinations. To address this, we introduce V-Skip that reformulates token pruning as a Visual-Anchored Information Bottleneck (VA-IB) optimization problem. V-Skip employs a dual-path gating mechanism that weighs token importance through both linguistic surprisal and cross-modal attention flow, effectively rescuing visually salient anchors. Extensive experiments on Qwen2-VL and Llama-3.2 families demonstrate that V-Skip achieves a $2.9\times$ speedup with negligible accuracy loss. Specifically, it preserves fine-grained visual details, outperforming other baselines over 30\% on the DocVQA.
HumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance
Jul 09, 2024



Text-to-image diffusion models have significantly advanced in conditional image generation. However, these models usually struggle with accurately rendering images featuring humans, resulting in distorted limbs and other anomalies. This issue primarily stems from the insufficient recognition and evaluation of limb qualities in diffusion models. To address this issue, we introduce AbHuman, the first large-scale synthesized human benchmark focusing on anatomical anomalies. This benchmark consists of 56K synthesized human images, each annotated with detailed, bounding-box level labels identifying 147K human anomalies in 18 different categories. Based on this, the recognition of human anomalies can be established, which in turn enhances image generation through traditional techniques such as negative prompting and guidance. To further boost the improvement, we propose HumanRefiner, a novel plug-and-play approach for the coarse-to-fine refinement of human anomalies in text-to-image generation. Specifically, HumanRefiner utilizes a self-diagnostic procedure to detect and correct issues related to both coarse-grained abnormal human poses and fine-grained anomaly levels, facilitating pose-reversible diffusion generation. Experimental results on the AbHuman benchmark demonstrate that HumanRefiner significantly reduces generative discrepancies, achieving a 2.9x improvement in limb quality compared to the state-of-the-art open-source generator SDXL and a 1.4x improvement over DALL-E 3 in human evaluations. Our data and code are available at https://github.com/Enderfga/HumanRefiner.
Contrastive Label Enhancement
May 16, 2023
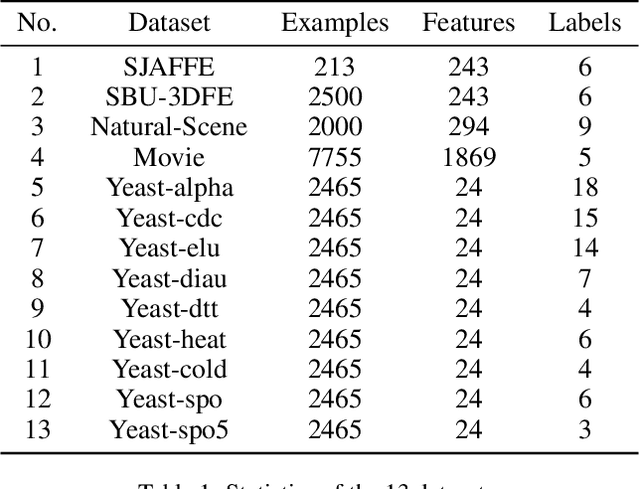
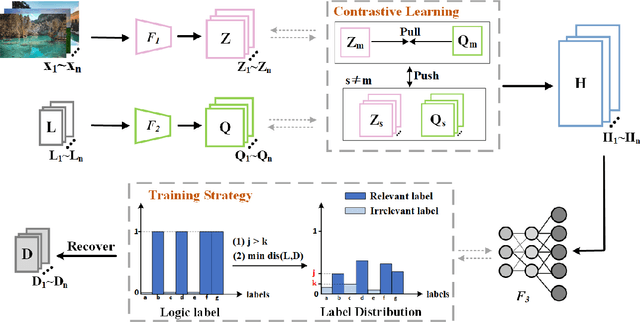

Label distribution learning (LDL) is a new machine learning paradigm for solving label ambiguity. Since it is difficult to directly obtain label distributions, many studies are focusing on how to recover label distributions from logical labels, dubbed label enhancement (LE). Existing LE methods estimate label distributions by simply building a mapping relationship between features and label distributions under the supervision of logical labels. They typically overlook the fact that both features and logical labels are descriptions of the instance from different views. Therefore, we propose a novel method called Contrastive Label Enhancement (ConLE) which integrates features and logical labels into the unified projection space to generate high-level features by contrastive learning strategy. In this approach, features and logical labels belonging to the same sample are pulled closer, while those of different samples are projected farther away from each other in the projection space. Subsequently, we leverage the obtained high-level features to gain label distributions through a welldesigned training strategy that considers the consistency of label attributes. Extensive experiments on LDL benchmark datasets demonstrate the effectiveness and superiority of our method.
Multi-view Semantic Consistency based Information Bottleneck for Clustering
Feb 28, 2023
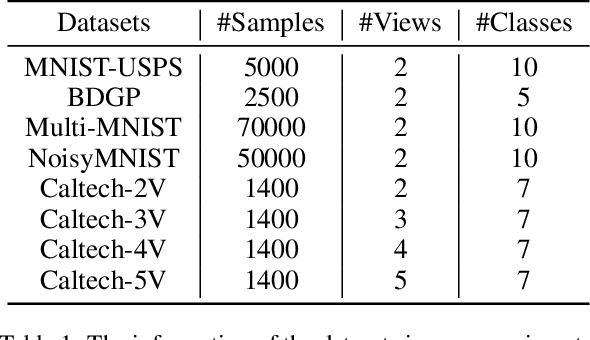

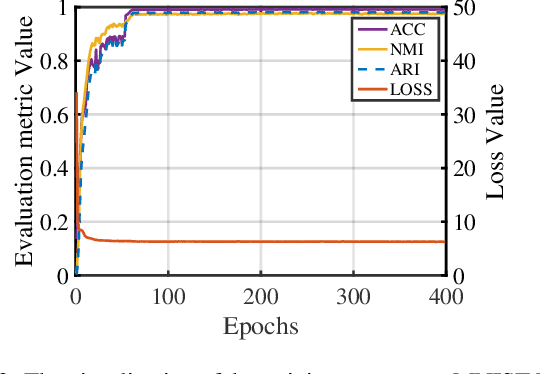
Multi-view clustering can make use of multi-source information for unsupervised clustering. Most existing methods focus on learning a fused representation matrix, while ignoring the influence of private information and noise. To address this limitation, we introduce a novel Multi-view Semantic Consistency based Information Bottleneck for clustering (MSCIB). Specifically, MSCIB pursues semantic consistency to improve the learning process of information bottleneck for different views. It conducts the alignment operation of multiple views in the semantic space and jointly achieves the valuable consistent information of multi-view data. In this way, the learned semantic consistency from multi-view data can improve the information bottleneck to more exactly distinguish the consistent information and learn a unified feature representation with more discriminative consistent information for clustering. Experiments on various types of multi-view datasets show that MSCIB achieves state-of-the-art performance.
MCoCo: Multi-level Consistency Collaborative Multi-view Clustering
Feb 26, 2023



Multi-view clustering can explore consistent information from different views to guide clustering. Most existing works focus on pursuing shallow consistency in the feature space and integrating the information of multiple views into a unified representation for clustering. These methods did not fully consider and explore the consistency in the semantic space. To address this issue, we proposed a novel Multi-level Consistency Collaborative learning framework (MCoCo) for multi-view clustering. Specifically, MCoCo jointly learns cluster assignments of multiple views in feature space and aligns semantic labels of different views in semantic space by contrastive learning. Further, we designed a multi-level consistency collaboration strategy, which utilizes the consistent information of semantic space as a self-supervised signal to collaborate with the cluster assignments in feature space. Thus, different levels of spaces collaborate with each other while achieving their own consistency goals, which makes MCoCo fully mine the consistent information of different views without fusion. Compared with state-of-the-art methods, extensive experiments demonstrate the effectiveness and superiority of our method.