 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance
Jul 09, 2024



Text-to-image diffusion models have significantly advanced in conditional image generation. However, these models usually struggle with accurately rendering images featuring humans, resulting in distorted limbs and other anomalies. This issue primarily stems from the insufficient recognition and evaluation of limb qualities in diffusion models. To address this issue, we introduce AbHuman, the first large-scale synthesized human benchmark focusing on anatomical anomalies. This benchmark consists of 56K synthesized human images, each annotated with detailed, bounding-box level labels identifying 147K human anomalies in 18 different categories. Based on this, the recognition of human anomalies can be established, which in turn enhances image generation through traditional techniques such as negative prompting and guidance. To further boost the improvement, we propose HumanRefiner, a novel plug-and-play approach for the coarse-to-fine refinement of human anomalies in text-to-image generation. Specifically, HumanRefiner utilizes a self-diagnostic procedure to detect and correct issues related to both coarse-grained abnormal human poses and fine-grained anomaly levels, facilitating pose-reversible diffusion generation. Experimental results on the AbHuman benchmark demonstrate that HumanRefiner significantly reduces generative discrepancies, achieving a 2.9x improvement in limb quality compared to the state-of-the-art open-source generator SDXL and a 1.4x improvement over DALL-E 3 in human evaluations. Our data and code are available at https://github.com/Enderfga/HumanRefiner.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
Boosting Text-to-Image Diffusion Models with Fine-Grained Semantic Rewards
Jun 01, 2023

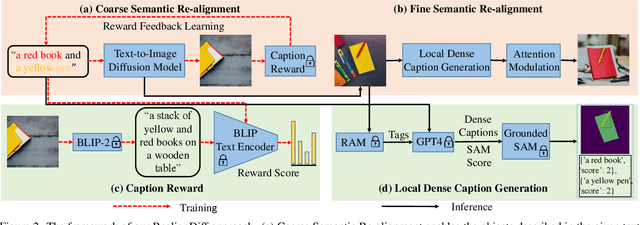
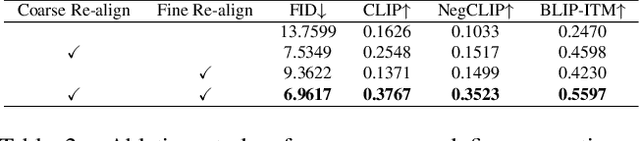
Recent advances in text-to-image diffusion models have achieved remarkable success in generating high-quality, realistic images from given text prompts. However, previous methods fail to perform accurate modality alignment between text concepts and generated images due to the lack of fine-level semantic guidance that successfully diagnoses the modality discrepancy. In this paper, we propose FineRewards to improve the alignment between text and images in text-to-image diffusion models by introducing two new fine-grained semantic rewards: the caption reward and the Semantic Segment Anything (SAM) reward. From the global semantic view, the caption reward generates a corresponding detailed caption that depicts all important contents in the synthetic image via a BLIP-2 model and then calculates the reward score by measuring the similarity between the generated caption and the given prompt. From the local semantic view, the SAM reward segments the generated images into local parts with category labels, and scores the segmented parts by measuring the likelihood of each category appearing in the prompted scene via a large language model, i.e., Vicuna-7B. Additionally, we adopt an assemble reward-ranked learning strategy to enable the integration of multiple reward functions to jointly guide the model training. Adapting results of text-to-image models on the MS-COCO benchmark show that the proposed semantic reward outperforms other baseline reward functions with a considerable margin on both visual quality and semantic similarity with the input prompt. Moreover, by adopting the assemble reward-ranked learning strategy, we further demonstrate that model performance is further improved when adapting under the unifying of the proposed semantic reward with the current image rewards.
3D-TOGO: Towards Text-Guided Cross-Category 3D Object Generation
Dec 02, 2022



Text-guided 3D object generation aims to generate 3D objects described by user-defined captions, which paves a flexible way to visualize what we imagined. Although some works have been devoted to solving this challenging task, these works either utilize some explicit 3D representations (e.g., mesh), which lack texture and require post-processing for rendering photo-realistic views; or require individual time-consuming optimization for every single case. Here, we make the first attempt to achieve generic text-guided cross-category 3D object generation via a new 3D-TOGO model, which integrates a text-to-views generation module and a views-to-3D generation module. The text-to-views generation module is designed to generate different views of the target 3D object given an input caption. prior-guidance, caption-guidance and view contrastive learning are proposed for achieving better view-consistency and caption similarity. Meanwhile, a pixelNeRF model is adopted for the views-to-3D generation module to obtain the implicit 3D neural representation from the previously-generated views. Our 3D-TOGO model generates 3D objects in the form of the neural radiance field with good texture and requires no time-cost optimization for every single caption. Besides, 3D-TOGO can control the category, color and shape of generated 3D objects with the input caption. Extensive experiments on the largest 3D object dataset (i.e., ABO) are conducted to verify that 3D-TOGO can better generate high-quality 3D objects according to the input captions across 98 different categories, in terms of PSNR, SSIM, LPIPS and CLIP-score, compared with text-NeRF and Dreamfields.
Dynamic Slimmable Denoising Network
Oct 17, 2021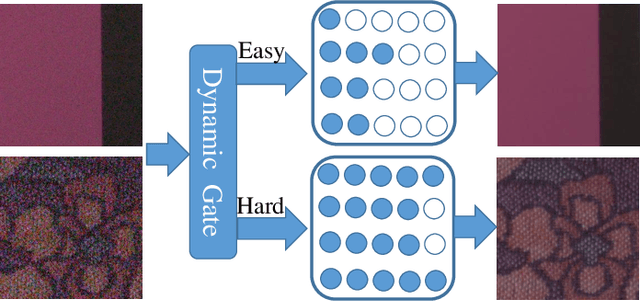

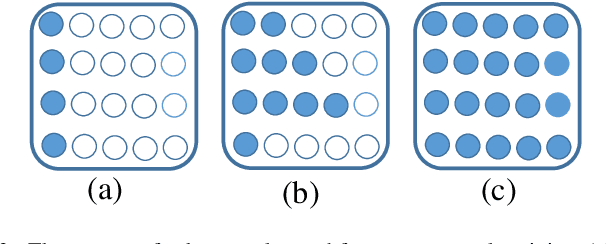
Recently, tremendous human-designed and automatically searched neural networks have been applied to image denoising. However, previous works intend to handle all noisy images in a pre-defined static network architecture, which inevitably leads to high computational complexity for good denoising quality. Here, we present dynamic slimmable denoising network (DDS-Net), a general method to achieve good denoising quality with less computational complexity, via dynamically adjusting the channel configurations of networks at test time with respect to different noisy images. Our DDS-Net is empowered with the ability of dynamic inference by a dynamic gate, which can predictively adjust the channel configuration of networks with negligible extra computation cost. To ensure the performance of each candidate sub-network and the fairness of the dynamic gate, we propose a three-stage optimization scheme. In the first stage, we train a weight-shared slimmable super network. In the second stage, we evaluate the trained slimmable super network in an iterative way and progressively tailor the channel numbers of each layer with minimal denoising quality drop. By a single pass, we can obtain several sub-networks with good performance under different channel configurations. In the last stage, we identify easy and hard samples in an online way and train a dynamic gate to predictively select the corresponding sub-network with respect to different noisy images. Extensive experiments demonstrate our DDS-Net consistently outperforms the state-of-the-art individually trained static denoising networks.
K-means clustering for efficient and robust registration of multi-view point sets
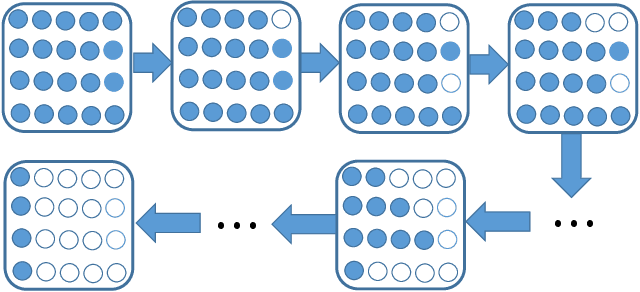
Apr 30, 2018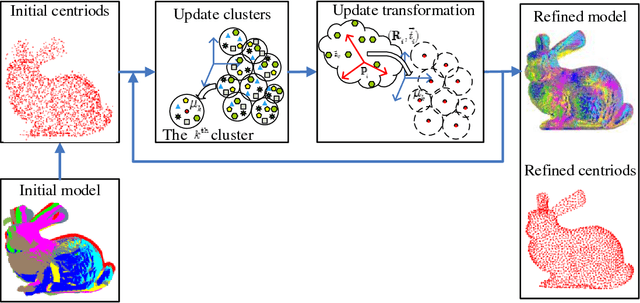
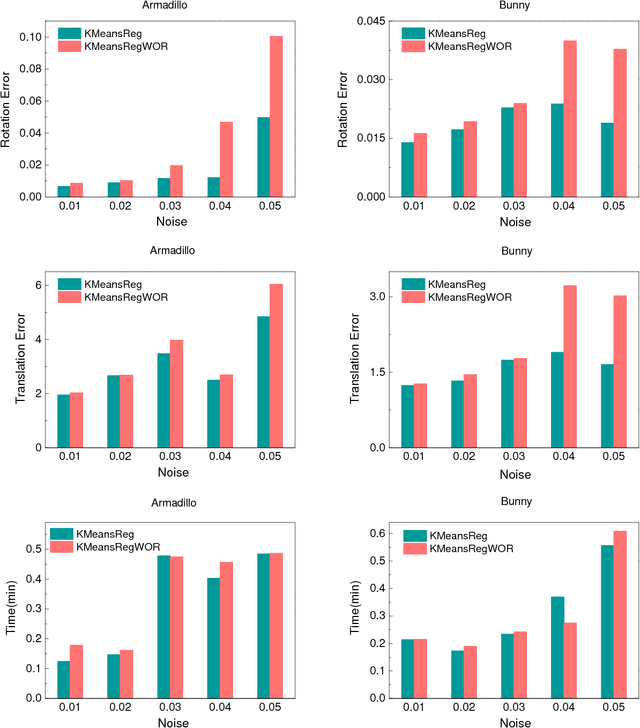
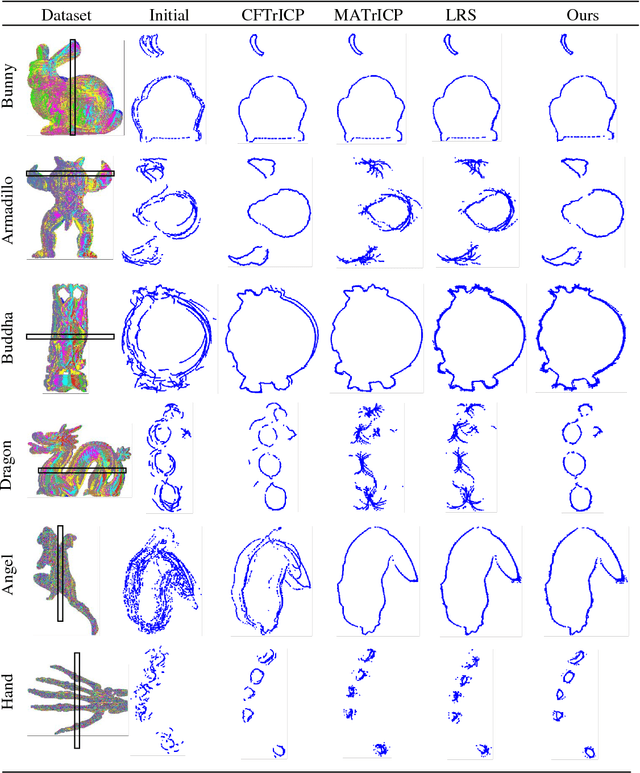
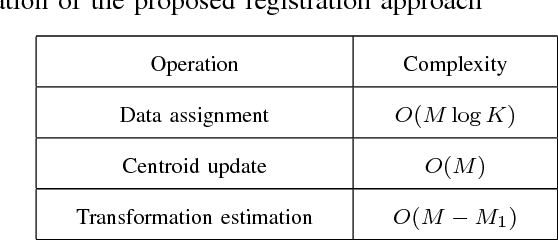
Generally, there are three main factors that determine the practical usability of registration, i.e., accuracy, robustness, and efficiency. In real-time applications, efficiency and robustness are more important. To promote these two abilities, we cast the multi-view registration into a clustering task. All the centroids are uniformly sampled from the initially aligned point sets involved in the multi-view registration, which makes it rather efficient and effective for the clustering. Then, each point is assigned to a single cluster and each cluster centroid is updated accordingly. Subsequently, the shape comprised by all cluster centroids is used to sequentially estimate the rigid transformation for each point set. For accuracy and stability, clustering and transformation estimation are alternately and iteratively applied to all point sets. We tested our proposed approach on several benchmark datasets and compared it with state-of-the-art approaches. Experimental results validate its efficiency and robustness for the registration of multi-view point sets.
Multi-view registration of unordered range scans by fast correspondence propagation of multi-scale descriptors
Apr 21, 2018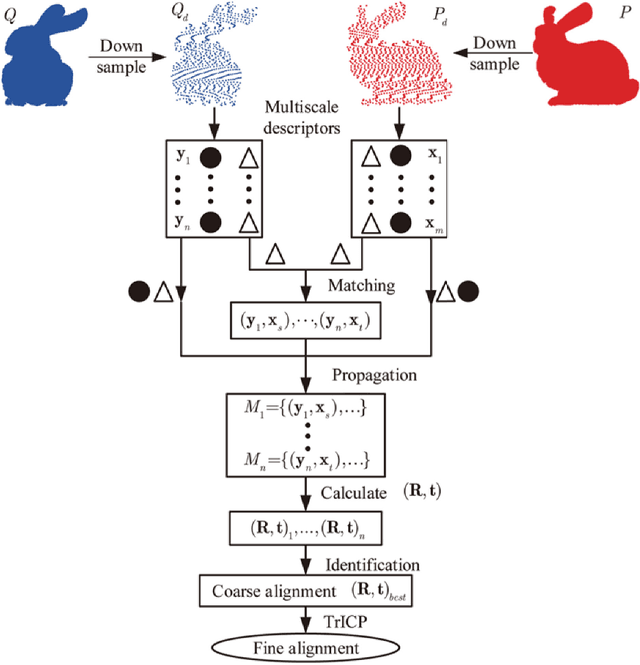
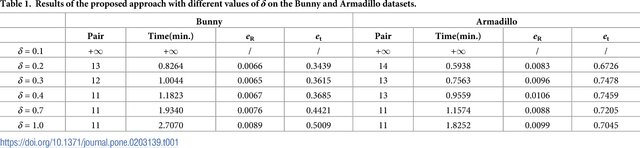
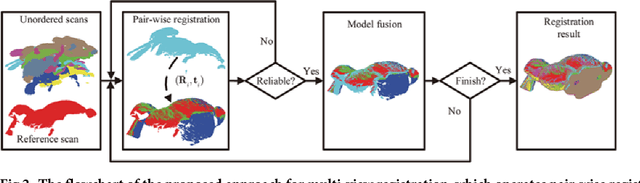

This paper proposes a global approach for the multi-view registration of unordered range scans. As the basis of multi-view registration, pair-wise registration is very pivotal. Therefore, we first select a good descriptor and accelerate its correspondence propagation for the pair-wise registration. Then, we design an effective rule to judge the reliability of pair-wise registration results. Subsequently, we propose a model augmentation method, which can utilize reliable results of pair-wise registration to augment the model shape. Finally, multi-view registration can be accomplished by operating the pair-wise registration and judgment, and model augmentation alternately. Experimental results on public available data sets show, that this approach can automatically achieve the multi-view registration of unordered range scans with good accuracy and effectiveness.
Simultaneous merging multiple grid maps using the robust motion averaging
Jun 14, 2017
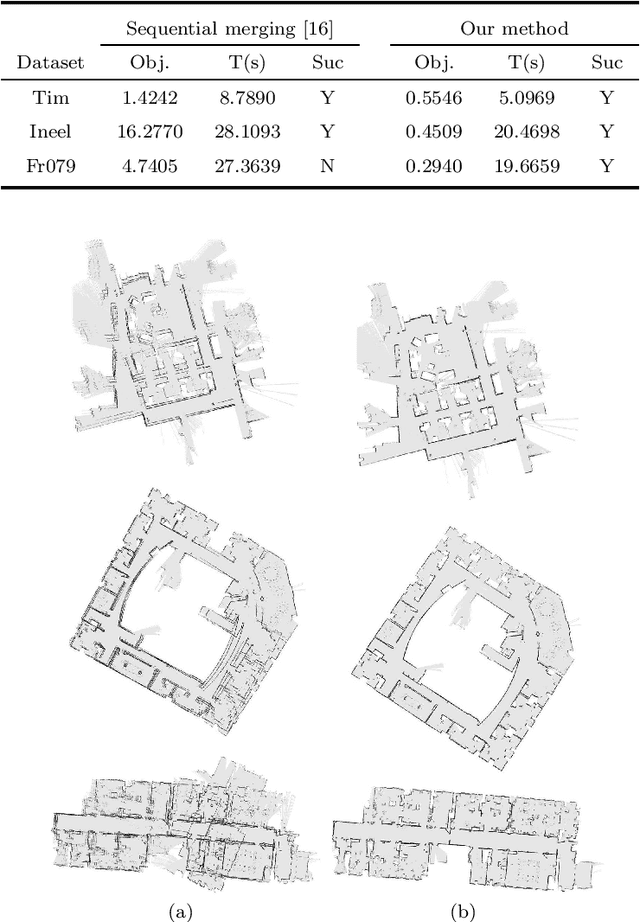
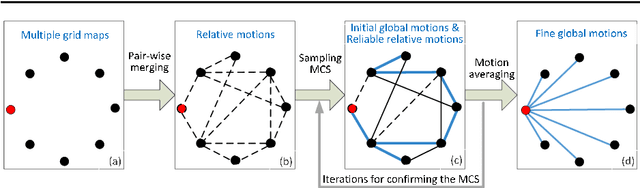
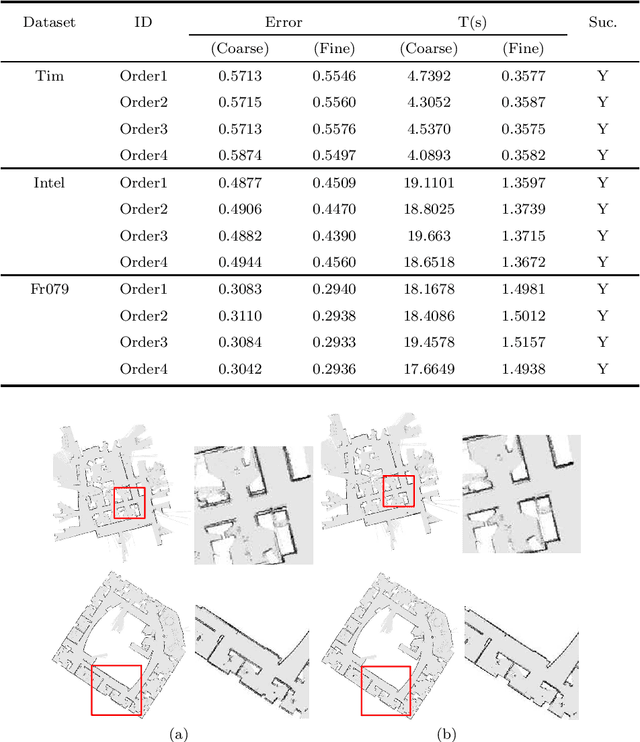
Mapping in the GPS-denied environment is an important and challenging task in the field of robotics. In the large environment, mapping can be significantly accelerated by multiple robots exploring different parts of the environment. Accordingly, a key problem is how to integrate these local maps built by different robots into a single global map. In this paper, we propose an approach for simultaneous merging of multiple grid maps by the robust motion averaging. The main idea of this approach is to recover all global motions for map merging from a set of relative motions. Therefore, it firstly adopts the pair-wise map merging method to estimate relative motions for grid map pairs. To obtain as many reliable relative motions as possible, a graph-based sampling scheme is utilized to efficiently remove unreliable relative motions obtained from the pair-wise map merging. Subsequently, the accurate global motions can be recovered from the set of reliable relative motions by the motion averaging. Experimental results carried on real robot data sets demonstrate that proposed approach can achieve simultaneous merging of multiple grid maps with good performances.