 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Visual Representation Alignment Generation with GRPO
May 30, 2026Recent diffusion transformers have demonstrated strong image synthesis capabilities but remain inefficient to train due to weak alignment between generative and discriminative representations. While representation alignment frameworks such as REPA improve convergence by aligning noisy denoising features with pretrained visual encoders, their externally supervised alignment loss is static and lacks adaptivity during training and inference. Existing methods rely on fixed cosine alignment or contrastive objectives, which cannot dynamically balance representation consistency and generation quality, resulting in limited discriminative benefit and failing to optimize alignment in a task-adaptive manner. To address this, we propose VRPO, a reinforcement-based optimization strategy that replaces REPA's static alignment loss with a generative representation policy optimization objective. Instead of enforcing a fixed similarity constraint, VRPO treats representation alignment as a reward-guided process: the model receives adaptive rewards based on generation fidelity, perceptual quality, and semantic coherence between the diffusion features and pretrained visual embeddings. This formulation enables the generator to continuously refine its internal representations toward semantically meaningful directions while improving image quality. Our VRPO-driven training seamlessly integrates into diffusion transformers, introducing negligible computation cost and preserving full compatibility with SiT and DiT architectures. Extensive experiments on ImageNet-256x256 demonstrate that our VRPO-Alignment substantially enhances both convergence and fidelity, achieving up to +1.8 FID improvement and 2.3x faster training compared to REPA under identical compute budgets.
LVRPO: Language-Visual Alignment with GRPO for Multimodal Understanding and Generation
Mar 29, 2026Unified multimodal pretraining has emerged as a promising paradigm for jointly modeling language and vision within a single foundation model. However, existing approaches largely rely on implicit or indirect alignment signals and remain suboptimal for simultaneously supporting multimodal understanding and generation, particularly in settings that require fine-grained language-visual reasoning and controllable generation. In this work, we propose LVRPO, a language-visual reinforcement-based preference optimization framework that explicitly aligns language and visual representations using Group Relative Policy Optimization (GRPO). Instead of introducing additional alignment losses at the representation level, LVRPO directly optimizes multimodal model behaviors through preference-driven reinforcement signals, encouraging consistent and semantically grounded interactions between language and vision across both understanding and generation tasks. This formulation enables effective alignment without requiring auxiliary encoders or handcrafted cross-modal objectives, and naturally extends to diverse multimodal capabilities. Empirically, LVRPO consistently outperforms strong unified-pretraining baselines on a broad suite of benchmarks spanning multimodal understanding, generation, and reasoning.
GMAIL: Generative Modality Alignment for generated Image Learning
Feb 17, 2026Generative models have made it possible to synthesize highly realistic images, potentially providing an abundant data source for training machine learning models. Despite the advantages of these synthesizable data sources, the indiscriminate use of generated images as real images for training can even cause mode collapse due to modality discrepancies between real and synthetic domains. In this paper, we propose a novel framework for discriminative use of generated images, coined GMAIL, that explicitly treats generated images as a separate modality from real images. Instead of indiscriminately replacing real images with generated ones in the pixel space, our approach bridges the two distinct modalities in the same latent space through a multi-modal learning approach. To be specific, we first fine-tune a model exclusively on generated images using a cross-modality alignment loss and then employ this aligned model to further train various vision-language models with generated images. By aligning the two modalities, our approach effectively leverages the benefits of recent advances in generative models, thereby boosting the effectiveness of generated image learning across a range of vision-language tasks. Our framework can be easily incorporated with various vision-language models, and we demonstrate its efficacy throughout extensive experiments. For example, our framework significantly improves performance on image captioning, zero-shot image retrieval, zero-shot image classification, and long caption retrieval tasks. It also shows positive generated data scaling trends and notable enhancements in the captioning performance of the large multimodal model, LLaVA.
Tabular Transfer Learning via Prompting LLMs
Aug 09, 2024Learning with a limited number of labeled data is a central problem in real-world applications of machine learning, as it is often expensive to obtain annotations. To deal with the scarcity of labeled data, transfer learning is a conventional approach; it suggests to learn a transferable knowledge by training a neural network from multiple other sources. In this paper, we investigate transfer learning of tabular tasks, which has been less studied and successful in the literature, compared to other domains, e.g., vision and language. This is because tables are inherently heterogeneous, i.e., they contain different columns and feature spaces, making transfer learning difficult. On the other hand, recent advances in natural language processing suggest that the label scarcity issue can be mitigated by utilizing in-context learning capability of large language models (LLMs). Inspired by this and the fact that LLMs can also process tables within a unified language space, we ask whether LLMs can be effective for tabular transfer learning, in particular, under the scenarios where the source and target datasets are of different format. As a positive answer, we propose a novel tabular transfer learning framework, coined Prompt to Transfer (P2T), that utilizes unlabeled (or heterogeneous) source data with LLMs. Specifically, P2T identifies a column feature in a source dataset that is strongly correlated with a target task feature to create examples relevant to the target task, thus creating pseudo-demonstrations for prompts. Experimental results demonstrate that P2T outperforms previous methods on various tabular learning benchmarks, showing good promise for the important, yet underexplored tabular transfer learning problem. Code is available at https://github.com/jaehyun513/P2T.
Web2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
DMT-JEPA: Discriminative Masked Targets for Joint-Embedding Predictive Architecture
May 28, 2024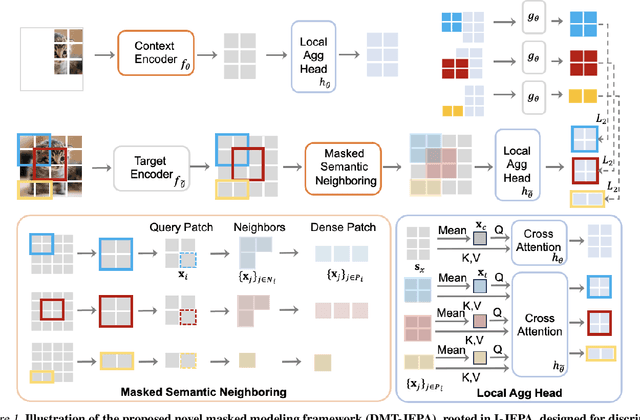



The joint-embedding predictive architecture (JEPA) recently has shown impressive results in extracting visual representations from unlabeled imagery under a masking strategy. However, we reveal its disadvantages, notably its insufficient understanding of local semantics. This deficiency originates from masked modeling in the embedding space, resulting in a reduction of discriminative power and can even lead to the neglect of critical local semantics. To bridge this gap, we introduce DMT-JEPA, a novel masked modeling objective rooted in JEPA, specifically designed to generate discriminative latent targets from neighboring information. Our key idea is simple: we consider a set of semantically similar neighboring patches as a target of a masked patch. To be specific, the proposed DMT-JEPA (a) computes feature similarities between each masked patch and its corresponding neighboring patches to select patches having semantically meaningful relations, and (b) employs lightweight cross-attention heads to aggregate features of neighboring patches as the masked targets. Consequently, DMT-JEPA demonstrates strong discriminative power, offering benefits across a diverse spectrum of downstream tasks. Through extensive experiments, we demonstrate our effectiveness across various visual benchmarks, including ImageNet-1K image classification, ADE20K semantic segmentation, and COCO object detection tasks. Code is available at: \url{https://github.com/DMTJEPA/DMTJEPA}.
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Apr 16, 2024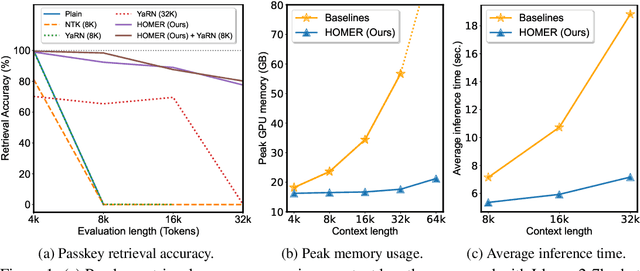
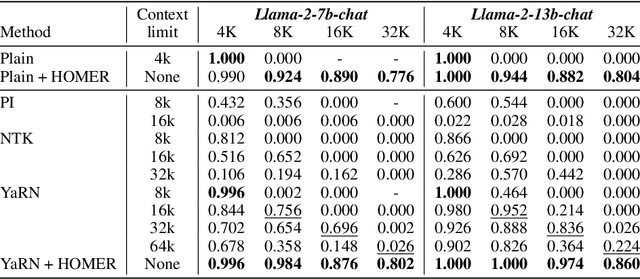
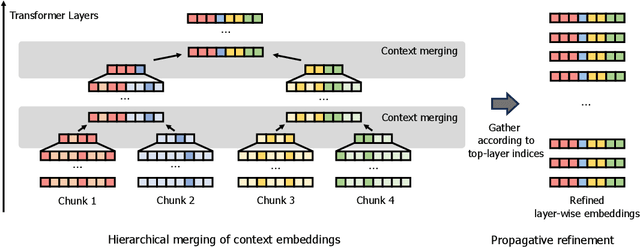
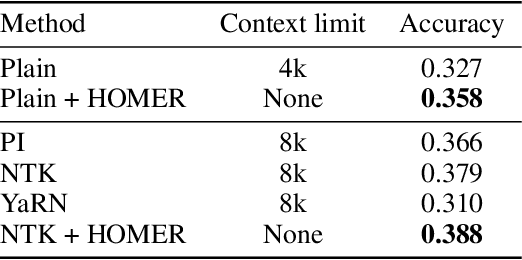
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
IFSeg: Image-free Semantic Segmentation via Vision-Language Model
Mar 25, 2023

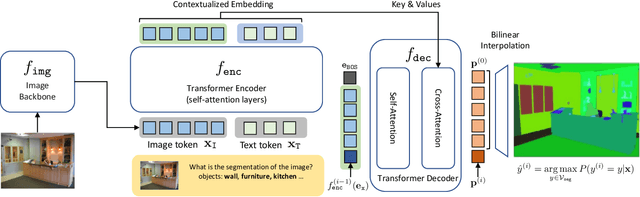

Vision-language (VL) pre-training has recently gained much attention for its transferability and flexibility in novel concepts (e.g., cross-modality transfer) across various visual tasks. However, VL-driven segmentation has been under-explored, and the existing approaches still have the burden of acquiring additional training images or even segmentation annotations to adapt a VL model to downstream segmentation tasks. In this paper, we introduce a novel image-free segmentation task where the goal is to perform semantic segmentation given only a set of the target semantic categories, but without any task-specific images and annotations. To tackle this challenging task, our proposed method, coined IFSeg, generates VL-driven artificial image-segmentation pairs and updates a pre-trained VL model to a segmentation task. We construct this artificial training data by creating a 2D map of random semantic categories and another map of their corresponding word tokens. Given that a pre-trained VL model projects visual and text tokens into a common space where tokens that share the semantics are located closely, this artificially generated word map can replace the real image inputs for such a VL model. Through an extensive set of experiments, our model not only establishes an effective baseline for this novel task but also demonstrates strong performances compared to existing methods that rely on stronger supervision, such as task-specific images and segmentation masks. Code is available at https://github.com/alinlab/ifseg.
Time Is MattEr: Temporal Self-supervision for Video Transformers
Jul 19, 2022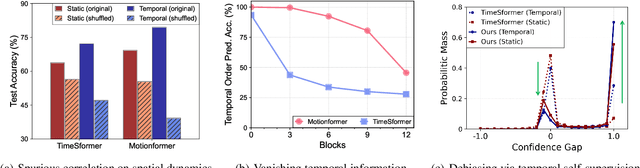
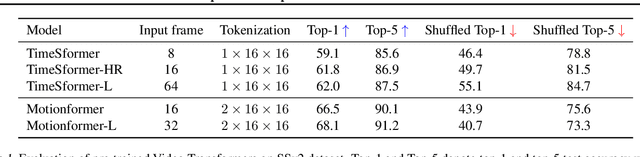
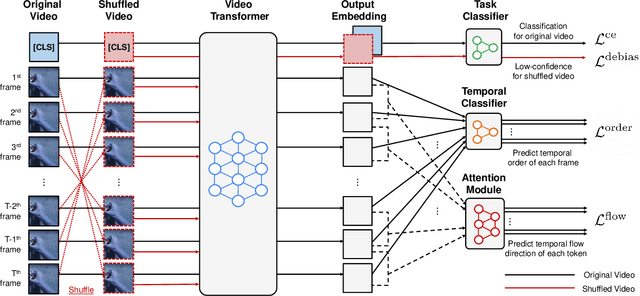
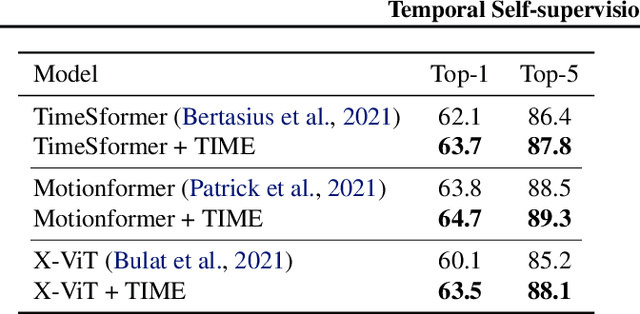
Understanding temporal dynamics of video is an essential aspect of learning better video representations. Recently, transformer-based architectural designs have been extensively explored for video tasks due to their capability to capture long-term dependency of input sequences. However, we found that these Video Transformers are still biased to learn spatial dynamics rather than temporal ones, and debiasing the spurious correlation is critical for their performance. Based on the observations, we design simple yet effective self-supervised tasks for video models to learn temporal dynamics better. Specifically, for debiasing the spatial bias, our method learns the temporal order of video frames as extra self-supervision and enforces the randomly shuffled frames to have low-confidence outputs. Also, our method learns the temporal flow direction of video tokens among consecutive frames for enhancing the correlation toward temporal dynamics. Under various video action recognition tasks, we demonstrate the effectiveness of our method and its compatibility with state-of-the-art Video Transformers.
Patch-level Representation Learning for Self-supervised Vision Transformers
Jun 17, 2022
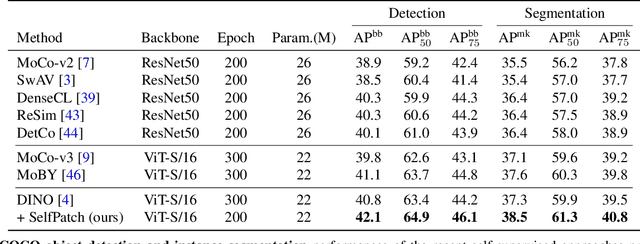
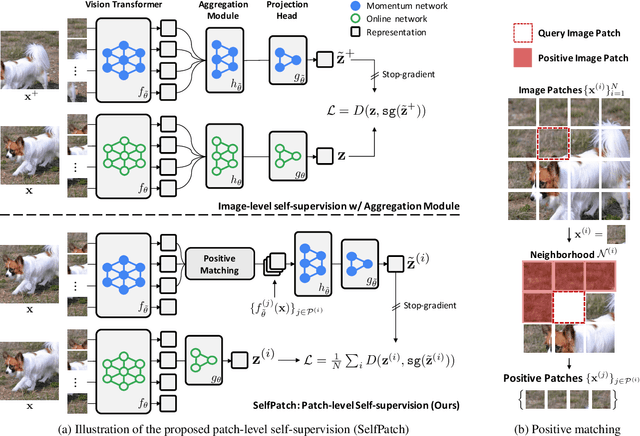
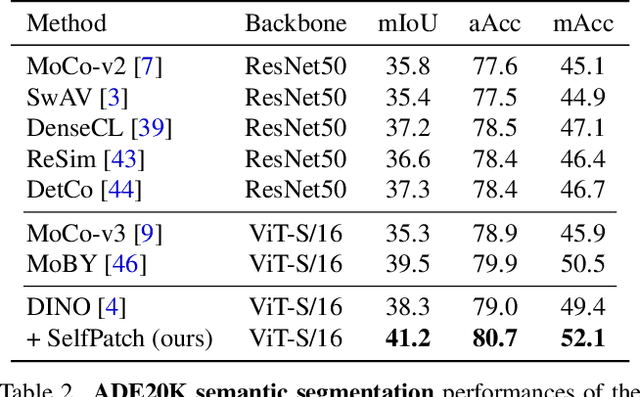
Recent self-supervised learning (SSL) methods have shown impressive results in learning visual representations from unlabeled images. This paper aims to improve their performance further by utilizing the architectural advantages of the underlying neural network, as the current state-of-the-art visual pretext tasks for SSL do not enjoy the benefit, i.e., they are architecture-agnostic. In particular, we focus on Vision Transformers (ViTs), which have gained much attention recently as a better architectural choice, often outperforming convolutional networks for various visual tasks. The unique characteristic of ViT is that it takes a sequence of disjoint patches from an image and processes patch-level representations internally. Inspired by this, we design a simple yet effective visual pretext task, coined SelfPatch, for learning better patch-level representations. To be specific, we enforce invariance against each patch and its neighbors, i.e., each patch treats similar neighboring patches as positive samples. Consequently, training ViTs with SelfPatch learns more semantically meaningful relations among patches (without using human-annotated labels), which can be beneficial, in particular, to downstream tasks of a dense prediction type. Despite its simplicity, we demonstrate that it can significantly improve the performance of existing SSL methods for various visual tasks, including object detection and semantic segmentation. Specifically, SelfPatch significantly improves the recent self-supervised ViT, DINO, by achieving +1.3 AP on COCO object detection, +1.2 AP on COCO instance segmentation, and +2.9 mIoU on ADE20K semantic segmentation.