 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimePerceiver: An Encoder-Decoder Framework for Generalized Time-Series Forecasting
Dec 27, 2025In machine learning, effective modeling requires a holistic consideration of how to encode inputs, make predictions (i.e., decoding), and train the model. However, in time-series forecasting, prior work has predominantly focused on encoder design, often treating prediction and training as separate or secondary concerns. In this paper, we propose TimePerceiver, a unified encoder-decoder forecasting framework that is tightly aligned with an effective training strategy. To be specific, we first generalize the forecasting task to include diverse temporal prediction objectives such as extrapolation, interpolation, and imputation. Since this generalization requires handling input and target segments that are arbitrarily positioned along the temporal axis, we design a novel encoder-decoder architecture that can flexibly perceive and adapt to these varying positions. For encoding, we introduce a set of latent bottleneck representations that can interact with all input segments to jointly capture temporal and cross-channel dependencies. For decoding, we leverage learnable queries corresponding to target timestamps to effectively retrieve relevant information. Extensive experiments demonstrate that our framework consistently and significantly outperforms prior state-of-the-art baselines across a wide range of benchmark datasets. The code is available at https://github.com/efficient-learning-lab/TimePerceiver.
Training-free Detection of AI-generated images via Cropping Robustness
Nov 18, 2025AI-generated image detection has become crucial with the rapid advancement of vision-generative models. Instead of training detectors tailored to specific datasets, we study a training-free approach leveraging self-supervised models without requiring prior data knowledge. These models, pre-trained with augmentations like RandomResizedCrop, learn to produce consistent representations across varying resolutions. Motivated by this, we propose WaRPAD, a training-free AI-generated image detection algorithm based on self-supervised models. Since neighborhood pixel differences in images are highly sensitive to resizing operations, WaRPAD first defines a base score function that quantifies the sensitivity of image embeddings to perturbations along high-frequency directions extracted via Haar wavelet decomposition. To simulate robustness against cropping augmentation, we rescale each image to a multiple of the models input size, divide it into smaller patches, and compute the base score for each patch. The final detection score is then obtained by averaging the scores across all patches. We validate WaRPAD on real datasets of diverse resolutions and domains, and images generated by 23 different generative models. Our method consistently achieves competitive performance and demonstrates strong robustness to test-time corruptions. Furthermore, as invariance to RandomResizedCrop is a common training scheme across self-supervised models, we show that WaRPAD is applicable across self-supervised models.
ReTabAD: A Benchmark for Restoring Semantic Context in Tabular Anomaly Detection
Oct 02, 2025In tabular anomaly detection (AD), textual semantics often carry critical signals, as the definition of an anomaly is closely tied to domain-specific context. However, existing benchmarks provide only raw data points without semantic context, overlooking rich textual metadata such as feature descriptions and domain knowledge that experts rely on in practice. This limitation restricts research flexibility and prevents models from fully leveraging domain knowledge for detection. ReTabAD addresses this gap by restoring textual semantics to enable context-aware tabular AD research. We provide (1) 20 carefully curated tabular datasets enriched with structured textual metadata, together with implementations of state-of-the-art AD algorithms including classical, deep learning, and LLM-based approaches, and (2) a zero-shot LLM framework that leverages semantic context without task-specific training, establishing a strong baseline for future research. Furthermore, this work provides insights into the role and utility of textual metadata in AD through experiments and analysis. Results show that semantic context improves detection performance and enhances interpretability by supporting domain-aware reasoning. These findings establish ReTabAD as a benchmark for systematic exploration of context-aware AD.
Diffusion based Semantic Outlier Generation via Nuisance Awareness for Out-of-Distribution Detection
Aug 27, 2024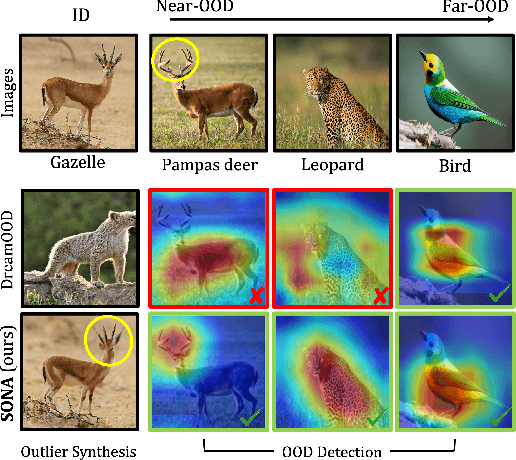
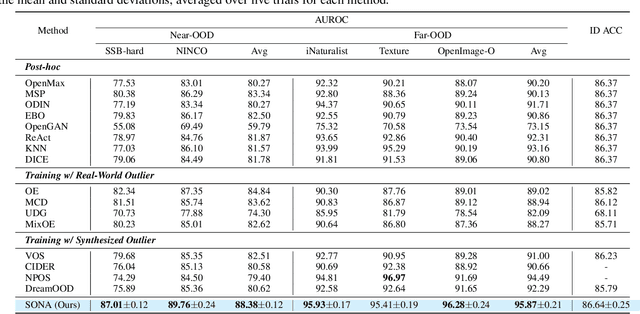
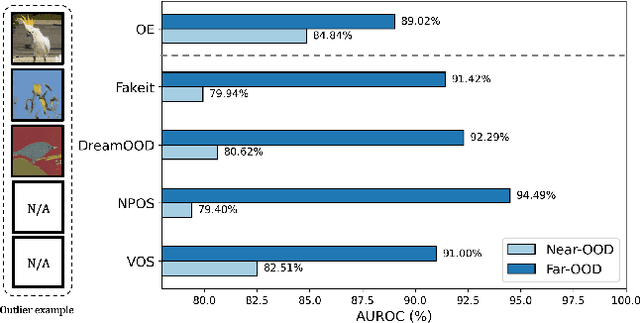
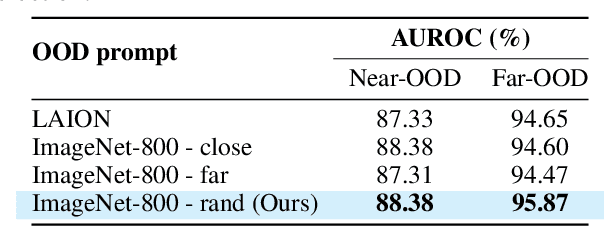
Out-of-distribution (OOD) detection, which determines whether a given sample is part of the in-distribution (ID), has recently shown promising results through training with synthetic OOD datasets. Nonetheless, existing methods often produce outliers that are considerably distant from the ID, showing limited efficacy for capturing subtle distinctions between ID and OOD. To address these issues, we propose a novel framework, Semantic Outlier generation via Nuisance Awareness (SONA), which notably produces challenging outliers by directly leveraging pixel-space ID samples through diffusion models. Our approach incorporates SONA guidance, providing separate control over semantic and nuisance regions of ID samples. Thereby, the generated outliers achieve two crucial properties: (i) they present explicit semantic-discrepant information, while (ii) maintaining various levels of nuisance resemblance with ID. Furthermore, the improved OOD detector training with SONA outliers facilitates learning with a focus on semantic distinctions. Extensive experiments demonstrate the effectiveness of our framework, achieving an impressive AUROC of 88% on near-OOD datasets, which surpasses the performance of baseline methods by a significant margin of approximately 6%.
Partial-Multivariate Model for Forecasting
Aug 19, 2024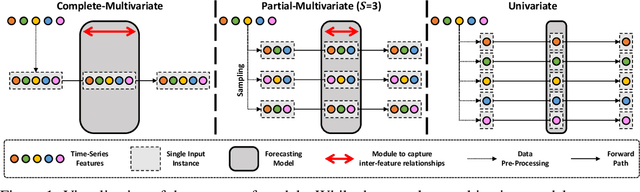
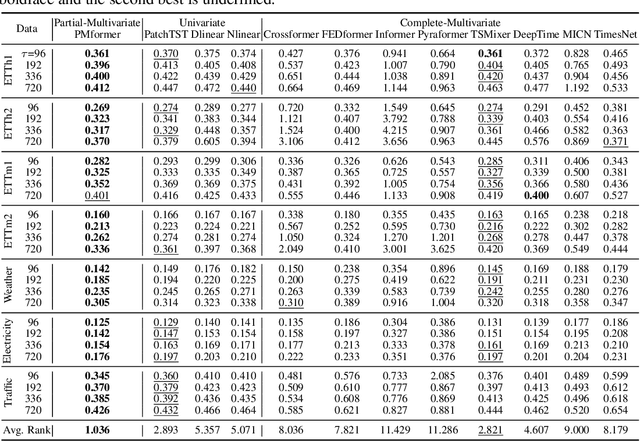

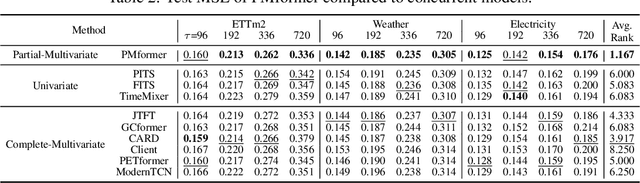
When solving forecasting problems including multiple time-series features, existing approaches often fall into two extreme categories, depending on whether to utilize inter-feature information: univariate and complete-multivariate models. Unlike univariate cases which ignore the information, complete-multivariate models compute relationships among a complete set of features. However, despite the potential advantage of leveraging the additional information, complete-multivariate models sometimes underperform univariate ones. Therefore, our research aims to explore a middle ground between these two by introducing what we term Partial-Multivariate models where a neural network captures only partial relationships, that is, dependencies within subsets of all features. To this end, we propose PMformer, a Transformer-based partial-multivariate model, with its training algorithm. We demonstrate that PMformer outperforms various univariate and complete-multivariate models, providing a theoretical rationale and empirical analysis for its superiority. Additionally, by proposing an inference technique for PMformer, the forecasting accuracy is further enhanced. Finally, we highlight other advantages of PMformer: efficiency and robustness under missing features.
Learning Equi-angular Representations for Online Continual Learning
Apr 02, 2024



Online continual learning suffers from an underfitted solution due to insufficient training for prompt model update (e.g., single-epoch training). To address the challenge, we propose an efficient online continual learning method using the neural collapse phenomenon. In particular, we induce neural collapse to form a simplex equiangular tight frame (ETF) structure in the representation space so that the continuously learned model with a single epoch can better fit to the streamed data by proposing preparatory data training and residual correction in the representation space. With an extensive set of empirical validations using CIFAR-10/100, TinyImageNet, ImageNet-200, and ImageNet-1K, we show that our proposed method outperforms state-of-the-art methods by a noticeable margin in various online continual learning scenarios such as disjoint and Gaussian scheduled continuous (i.e., boundary-free) data setups.
Projection Regret: Reducing Background Bias for Novelty Detection via Diffusion Models
Dec 05, 2023



Novelty detection is a fundamental task of machine learning which aims to detect abnormal ($\textit{i.e.}$ out-of-distribution (OOD)) samples. Since diffusion models have recently emerged as the de facto standard generative framework with surprising generation results, novelty detection via diffusion models has also gained much attention. Recent methods have mainly utilized the reconstruction property of in-distribution samples. However, they often suffer from detecting OOD samples that share similar background information to the in-distribution data. Based on our observation that diffusion models can \emph{project} any sample to an in-distribution sample with similar background information, we propose \emph{Projection Regret (PR)}, an efficient novelty detection method that mitigates the bias of non-semantic information. To be specific, PR computes the perceptual distance between the test image and its diffusion-based projection to detect abnormality. Since the perceptual distance often fails to capture semantic changes when the background information is dominant, we cancel out the background bias by comparing it against recursive projections. Extensive experiments demonstrate that PR outperforms the prior art of generative-model-based novelty detection methods by a significant margin.
Curve Your Attention: Mixed-Curvature Transformers for Graph Representation Learning
Sep 08, 2023Real-world graphs naturally exhibit hierarchical or cyclical structures that are unfit for the typical Euclidean space. While there exist graph neural networks that leverage hyperbolic or spherical spaces to learn representations that embed such structures more accurately, these methods are confined under the message-passing paradigm, making the models vulnerable against side-effects such as oversmoothing and oversquashing. More recent work have proposed global attention-based graph Transformers that can easily model long-range interactions, but their extensions towards non-Euclidean geometry are yet unexplored. To bridge this gap, we propose Fully Product-Stereographic Transformer, a generalization of Transformers towards operating entirely on the product of constant curvature spaces. When combined with tokenized graph Transformers, our model can learn the curvature appropriate for the input graph in an end-to-end fashion, without the need of additional tuning on different curvature initializations. We also provide a kernelized approach to non-Euclidean attention, which enables our model to run in time and memory cost linear to the number of nodes and edges while respecting the underlying geometry. Experiments on graph reconstruction and node classification demonstrate the benefits of generalizing Transformers to the non-Euclidean domain.
Enhancing Multiple Reliability Measures via Nuisance-extended Information Bottleneck
Mar 24, 2023In practical scenarios where training data is limited, many predictive signals in the data can be rather from some biases in data acquisition (i.e., less generalizable), so that one cannot prevent a model from co-adapting on such (so-called) "shortcut" signals: this makes the model fragile in various distribution shifts. To bypass such failure modes, we consider an adversarial threat model under a mutual information constraint to cover a wider class of perturbations in training. This motivates us to extend the standard information bottleneck to additionally model the nuisance information. We propose an autoencoder-based training to implement the objective, as well as practical encoder designs to facilitate the proposed hybrid discriminative-generative training concerning both convolutional- and Transformer-based architectures. Our experimental results show that the proposed scheme improves robustness of learned representations (remarkably without using any domain-specific knowledge), with respect to multiple challenging reliability measures. For example, our model could advance the state-of-the-art on a recent challenging OBJECTS benchmark in novelty detection by $78.4\% \rightarrow 87.2\%$ in AUROC, while simultaneously enjoying improved corruption, background and (certified) adversarial robustness. Code is available at https://github.com/jh-jeong/nuisance_ib.
Guiding Energy-based Models via Contrastive Latent Variables
Mar 06, 2023An energy-based model (EBM) is a popular generative framework that offers both explicit density and architectural flexibility, but training them is difficult since it is often unstable and time-consuming. In recent years, various training techniques have been developed, e.g., better divergence measures or stabilization in MCMC sampling, but there often exists a large gap between EBMs and other generative frameworks like GANs in terms of generation quality. In this paper, we propose a novel and effective framework for improving EBMs via contrastive representation learning (CRL). To be specific, we consider representations learned by contrastive methods as the true underlying latent variable. This contrastive latent variable could guide EBMs to understand the data structure better, so it can improve and accelerate EBM training significantly. To enable the joint training of EBM and CRL, we also design a new class of latent-variable EBMs for learning the joint density of data and the contrastive latent variable. Our experimental results demonstrate that our scheme achieves lower FID scores, compared to prior-art EBM methods (e.g., additionally using variational autoencoders or diffusion techniques), even with significantly faster and more memory-efficient training. We also show conditional and compositional generation abilities of our latent-variable EBMs as their additional benefits, even without explicit conditional training. The code is available at https://github.com/hankook/CLEL.