 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLDX-1 Technical Report
May 05, 2026While Vision-Language-Action models (VLAs) have shown remarkable progress toward human-like generalist robotic policies through the versatile intelligence (i.e. broad scene understanding and language-conditioned generalization) inherited from pre-trained Vision-Language Models, they still struggle with complex real-world tasks requiring broader functional capabilities (e.g. motion awareness, memory-aware decision making, and physical sensing). To address this, we introduce RLDX-1, a general-purpose robotic policy for dexterous manipulation built on the Multi-Stream Action Transformer (MSAT), an architecture that unifies these capabilities by integrating heterogeneous modalities through modality-specific streams with cross-modal joint self-attention. RLDX-1 further combines this architecture with system-level design choices, including synthesizing training data for rare manipulation scenarios, learning procedures specialized for human-like manipulation, and inference optimizations for real-time deployment. Through empirical evaluation, we show that RLDX-1 consistently outperforms recent frontier VLAs (e.g. $π_{0.5}$ and GR00T N1.6) across both simulation benchmarks and real-world tasks that require broad functional capabilities beyond general versatility. In particular, RLDX-1 shows superiority in ALLEX humanoid tasks by achieving success rates of 86.8% while $π_{0.5}$ and GR00T N1.6 achieve around 40%, highlighting the ability of RLDX-1 to control a high-DoF humanoid robot under diverse functional demands. Together, these results position RLDX-1 as a promising step toward reliable VLAs for complex, contact-rich, and dynamic real-world dexterous manipulation.
Modular Sensory Stream for Integrating Physical Feedback in Vision-Language-Action Models
Apr 25, 2026Humans understand and interact with the real world by relying on diverse physical feedback beyond visual perception. Motivated by this, recent approaches attempt to incorporate physical sensory signals into Vision-Language-Action models (VLAs). However, they typically focus on a single type of physical signal, failing to capture the heterogeneous and complementary nature of real-world interactions. In this paper, we propose MoSS, a modular sensory stream framework that adapts VLAs to leverage multiple sensory signals for action prediction. Specifically, we introduce decoupled modality streams that integrate heterogeneous physical signals into the action stream via joint cross-modal self-attention. To enable stable incorporation of new modalities, we adopt a two-stage training scheme that freezes pretrained VLA parameters in the early stage. Furthermore, to better capture contact interaction dynamics, we incorporate an auxiliary task that predicts future physical signals. Through extensive real-world experiments, we demonstrate that MoSS successfully augments VLAs to leverage diverse physical signals (i.e., tactile and torque), integrating multiple signals to achieve synergistic performance gains.
SpatialBoost: Enhancing Visual Representation through Language-Guided Reasoning
Mar 23, 2026Despite the remarkable success of large-scale pre-trained image representation models (i.e., vision encoders) across various vision tasks, they are predominantly trained on 2D image data and therefore often fail to capture 3D spatial relationships between objects and backgrounds in the real world, constraining their effectiveness in many downstream applications. To address this, we propose SpatialBoost, a scalable framework that enhances the spatial awareness of existing pre-trained vision encoders by injecting 3D spatial knowledge expressed in linguistic descriptions. The core idea involves converting dense 3D spatial information from 2D images into linguistic expressions, which is then used to inject such spatial knowledge into vision encoders through a Large Language Model (LLM). To this end, we adopt a multi-turn Chain-of-Thought (CoT) reasoning process that progressively incorporates dense spatial knowledge and builds hierarchical spatial understanding. To validate effectiveness, we adapt SpatialBoost to state-of-the-art vision encoders such as DINOv3, and evaluate its performance gains on a wide range of benchmarks requiring both 3D perception and general vision abilities. For instance, SpatialBoost improves DINOv3 performance from 55.9 to 59.7 mIoU on ADE20K, achieving state-of-the-art performance with 3.8% gain over the pre-trained DINOv3.
RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
Mar 22, 2026Improving embodied reasoning in multimodal-large-language models (MLLMs) is essential for building vision-language-action models (VLAs) on top of them to readily translate multimodal understanding into low-level actions. Accordingly, recent work has explored enhancing embodied reasoning in MLLMs through supervision of vision-question-answering type. However, these approaches have been reported to result in unstable VLA performance, often yielding only marginal or even negative gains. In this paper, we propose a more systematic MLLM training framework RoboAlign that reliably improves VLA performance. Our key idea is to sample action tokens via zero-shot natural language reasoning and refines this reasoning using reinforcement learning (RL) to improve action accuracy. As a result, RoboAlign bridges the modality gap between language and low-level actions in MLLMs, and facilitate knowledge transfer from MLLM to VLA. To validate the effectiveness of RoboAlign, we train VLAs by adding a diffusion-based action head on top of an MLLM backbone and evaluate them on major robotics benchmarks. Remarkably, by performing RL-based alignment after SFT using less than 1\% of the data, RoboAlign achieves performance improvements of 17.5\%, 18.9\%, and 106.6\% over SFT baselines on LIBERO, CALVIN, and real-world environments, respectively.
Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
Oct 31, 2025Recently, augmenting Vision-Language-Action models (VLAs) with world modeling has shown promise in improving robotic policy learning. However, it remains challenging to jointly predict next-state observations and action sequences because of the inherent difference between the two modalities. To address this, we propose DUal-STream diffusion (DUST), a world-model augmented VLA framework that handles the modality conflict and enhances the performance of VLAs across diverse tasks. Specifically, we propose a multimodal diffusion transformer architecture that explicitly maintains separate modality streams while still enabling cross-modal knowledge sharing. In addition, we introduce independent noise perturbations for each modality and a decoupled flow-matching loss. This design enables the model to learn the joint distribution in a bidirectional manner while avoiding the need for a unified latent space. Based on the decoupling of modalities during training, we also introduce a joint sampling method that supports test-time scaling, where action and vision tokens evolve asynchronously at different rates. Through experiments on simulated benchmarks such as RoboCasa and GR-1, DUST achieves up to 6% gains over baseline methods, while our test-time scaling approach provides an additional 2-5% boost. On real-world tasks with the Franka Research 3, DUST improves success rates by 13%, confirming its effectiveness beyond simulation. Furthermore, pre-training on action-free videos from BridgeV2 yields significant transfer gains on RoboCasa, underscoring DUST's potential for large-scale VLA pretraining.
ContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context
Oct 05, 2025Leveraging temporal context is crucial for success in partially observable robotic tasks. However, prior work in behavior cloning has demonstrated inconsistent performance gains when using multi-frame observations. In this paper, we introduce ContextVLA, a policy model that robustly improves robotic task performance by effectively leveraging multi-frame observations. Our approach is motivated by the key observation that Vision-Language-Action models (VLA), i.e., policy models built upon a Vision-Language Model (VLM), more effectively utilize multi-frame observations for action generation. This suggests that VLMs' inherent temporal understanding capability enables them to extract more meaningful context from multi-frame observations. However, the high dimensionality of video inputs introduces significant computational overhead, making VLA training and inference inefficient. To address this, ContextVLA compresses past observations into a single context token, allowing the policy to efficiently leverage temporal context for action generation. Our experiments show that ContextVLA consistently improves over single-frame VLAs and achieves the benefits of full multi-frame training but with reduced training and inference times.
Efficient Long Video Tokenization via Coordinate-based Patch Reconstruction
Nov 26, 2024



Efficient tokenization of videos remains a challenge in training vision models that can process long videos. One promising direction is to develop a tokenizer that can encode long video clips, as it would enable the tokenizer to leverage the temporal coherence of videos better for tokenization. However, training existing tokenizers on long videos often incurs a huge training cost as they are trained to reconstruct all the frames at once. In this paper, we introduce CoordTok, a video tokenizer that learns a mapping from coordinate-based representations to the corresponding patches of input videos, inspired by recent advances in 3D generative models. In particular, CoordTok encodes a video into factorized triplane representations and reconstructs patches that correspond to randomly sampled $(x,y,t)$ coordinates. This allows for training large tokenizer models directly on long videos without requiring excessive training resources. Our experiments show that CoordTok can drastically reduce the number of tokens for encoding long video clips. For instance, CoordTok can encode a 128-frame video with 128$\times$128 resolution into 1280 tokens, while baselines need 6144 or 8192 tokens to achieve similar reconstruction quality. We further show that this efficient video tokenization enables memory-efficient training of a diffusion transformer that can generate 128 frames at once.
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Oct 09, 2024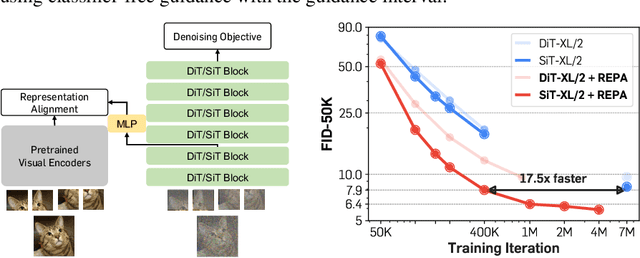

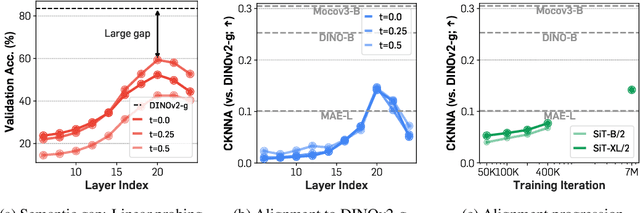
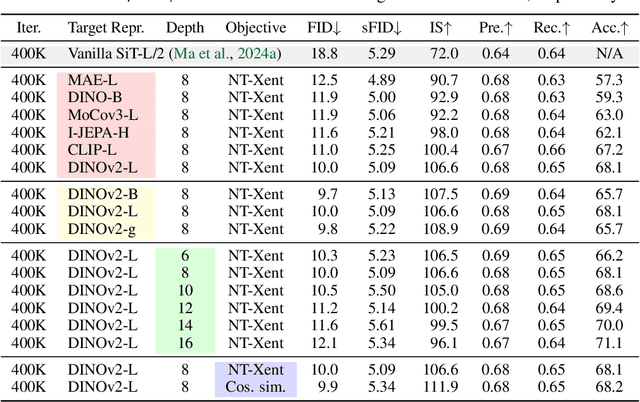
Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.
Adversarial Robustification via Text-to-Image Diffusion Models
Jul 26, 2024



Adversarial robustness has been conventionally believed as a challenging property to encode for neural networks, requiring plenty of training data. In the recent paradigm of adopting off-the-shelf models, however, access to their training data is often infeasible or not practical, while most of such models are not originally trained concerning adversarial robustness. In this paper, we develop a scalable and model-agnostic solution to achieve adversarial robustness without using any data. Our intuition is to view recent text-to-image diffusion models as "adaptable" denoisers that can be optimized to specify target tasks. Based on this, we propose: (a) to initiate a denoise-and-classify pipeline that offers provable guarantees against adversarial attacks, and (b) to leverage a few synthetic reference images generated from the text-to-image model that enables novel adaptation schemes. Our experiments show that our data-free scheme applied to the pre-trained CLIP could improve the (provable) adversarial robustness of its diverse zero-shot classification derivatives (while maintaining their accuracy), significantly surpassing prior approaches that utilize the full training data. Not only for CLIP, we also demonstrate that our framework is easily applicable for robustifying other visual classifiers efficiently.
Modality-Agnostic Self-Supervised Learning with Meta-Learned Masked Auto-Encoder
Oct 25, 2023Despite its practical importance across a wide range of modalities, recent advances in self-supervised learning (SSL) have been primarily focused on a few well-curated domains, e.g., vision and language, often relying on their domain-specific knowledge. For example, Masked Auto-Encoder (MAE) has become one of the popular architectures in these domains, but less has explored its potential in other modalities. In this paper, we develop MAE as a unified, modality-agnostic SSL framework. In turn, we argue meta-learning as a key to interpreting MAE as a modality-agnostic learner, and propose enhancements to MAE from the motivation to jointly improve its SSL across diverse modalities, coined MetaMAE as a result. Our key idea is to view the mask reconstruction of MAE as a meta-learning task: masked tokens are predicted by adapting the Transformer meta-learner through the amortization of unmasked tokens. Based on this novel interpretation, we propose to integrate two advanced meta-learning techniques. First, we adapt the amortized latent of the Transformer encoder using gradient-based meta-learning to enhance the reconstruction. Then, we maximize the alignment between amortized and adapted latents through task contrastive learning which guides the Transformer encoder to better encode the task-specific knowledge. Our experiment demonstrates the superiority of MetaMAE in the modality-agnostic SSL benchmark (called DABS), significantly outperforming prior baselines. Code is available at https://github.com/alinlab/MetaMAE.