 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamControl: Human-Inspired Whole-Body Humanoid Control for Scene Interaction via Guided Diffusion
Sep 17, 2025
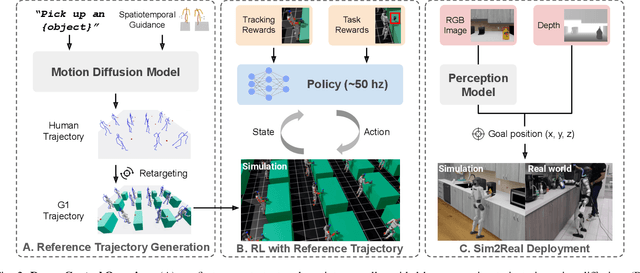

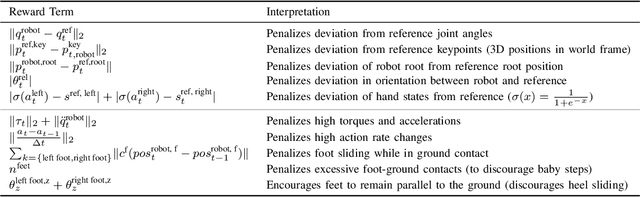
We introduce DreamControl, a novel methodology for learning autonomous whole-body humanoid skills. DreamControl leverages the strengths of diffusion models and Reinforcement Learning (RL): our core innovation is the use of a diffusion prior trained on human motion data, which subsequently guides an RL policy in simulation to complete specific tasks of interest (e.g., opening a drawer or picking up an object). We demonstrate that this human motion-informed prior allows RL to discover solutions unattainable by direct RL, and that diffusion models inherently promote natural looking motions, aiding in sim-to-real transfer. We validate DreamControl's effectiveness on a Unitree G1 robot across a diverse set of challenging tasks involving simultaneous lower and upper body control and object interaction.
FontAdapter: Instant Font Adaptation in Visual Text Generation
Jun 06, 2025

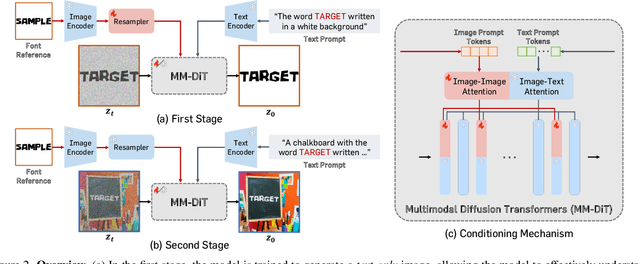
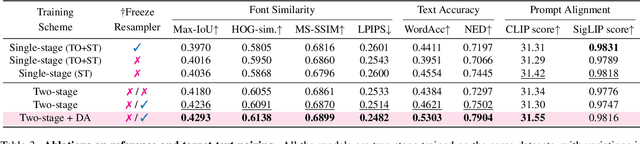
Text-to-image diffusion models have significantly improved the seamless integration of visual text into diverse image contexts. Recent approaches further improve control over font styles through fine-tuning with predefined font dictionaries. However, adapting unseen fonts outside the preset is computationally expensive, often requiring tens of minutes, making real-time customization impractical. In this paper, we present FontAdapter, a framework that enables visual text generation in unseen fonts within seconds, conditioned on a reference glyph image. To this end, we find that direct training on font datasets fails to capture nuanced font attributes, limiting generalization to new glyphs. To overcome this, we propose a two-stage curriculum learning approach: FontAdapter first learns to extract font attributes from isolated glyphs and then integrates these styles into diverse natural backgrounds. To support this two-stage training scheme, we construct synthetic datasets tailored to each stage, leveraging large-scale online fonts effectively. Experiments demonstrate that FontAdapter enables high-quality, robust font customization across unseen fonts without additional fine-tuning during inference. Furthermore, it supports visual text editing, font style blending, and cross-lingual font transfer, positioning FontAdapter as a versatile framework for font customization tasks.
StarFT: Robust Fine-tuning of Zero-shot Models via Spuriosity Alignment
May 19, 2025Learning robust representations from data often requires scale, which has led to the success of recent zero-shot models such as CLIP. However, the obtained robustness can easily be deteriorated when these models are fine-tuned on other downstream tasks (e.g., of smaller scales). Previous works often interpret this phenomenon in the context of domain shift, developing fine-tuning methods that aim to preserve the original domain as much as possible. However, in a different context, fine-tuned models with limited data are also prone to learning features that are spurious to humans, such as background or texture. In this paper, we propose StarFT (Spurious Textual Alignment Regularization), a novel framework for fine-tuning zero-shot models to enhance robustness by preventing them from learning spuriosity. We introduce a regularization that aligns the output distribution for spuriosity-injected labels with the original zero-shot model, ensuring that the model is not induced to extract irrelevant features further from these descriptions.We leverage recent language models to get such spuriosity-injected labels by generating alternative textual descriptions that highlight potentially confounding features.Extensive experiments validate the robust generalization of StarFT and its emerging properties: zero-shot group robustness and improved zero-shot classification. Notably, StarFT boosts both worst-group and average accuracy by 14.30% and 3.02%, respectively, in the Waterbirds group shift scenario, where other robust fine-tuning baselines show even degraded performance.
Controllable Human Image Generation with Personalized Multi-Garments
Nov 25, 2024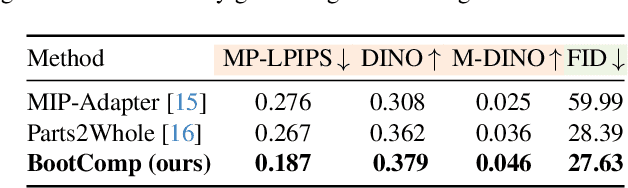
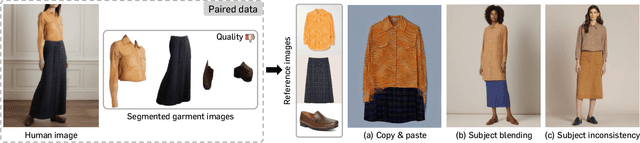

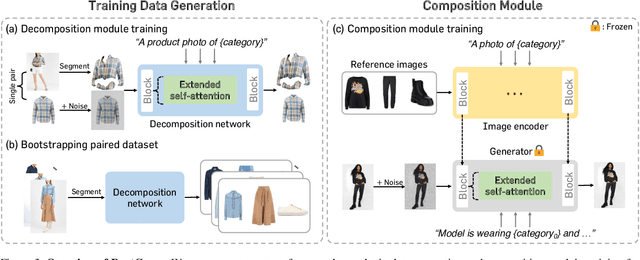
We present BootComp, a novel framework based on text-to-image diffusion models for controllable human image generation with multiple reference garments. Here, the main bottleneck is data acquisition for training: collecting a large-scale dataset of high-quality reference garment images per human subject is quite challenging, i.e., ideally, one needs to manually gather every single garment photograph worn by each human. To address this, we propose a data generation pipeline to construct a large synthetic dataset, consisting of human and multiple-garment pairs, by introducing a model to extract any reference garment images from each human image. To ensure data quality, we also propose a filtering strategy to remove undesirable generated data based on measuring perceptual similarities between the garment presented in human image and extracted garment. Finally, by utilizing the constructed synthetic dataset, we train a diffusion model having two parallel denoising paths that use multiple garment images as conditions to generate human images while preserving their fine-grained details. We further show the wide-applicability of our framework by adapting it to different types of reference-based generation in the fashion domain, including virtual try-on, and controllable human image generation with other conditions, e.g., pose, face, etc.
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Oct 09, 2024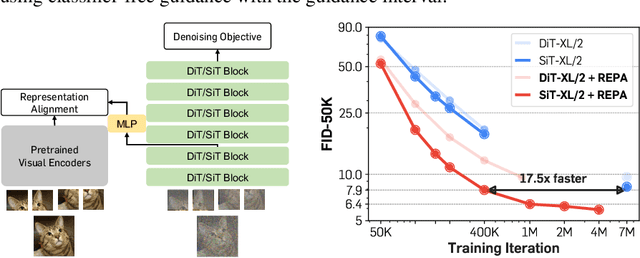

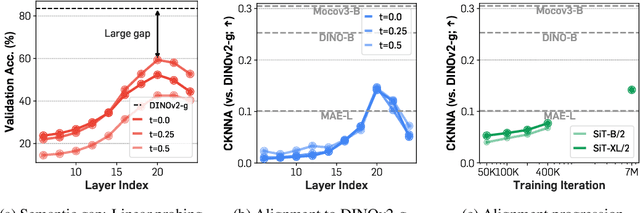
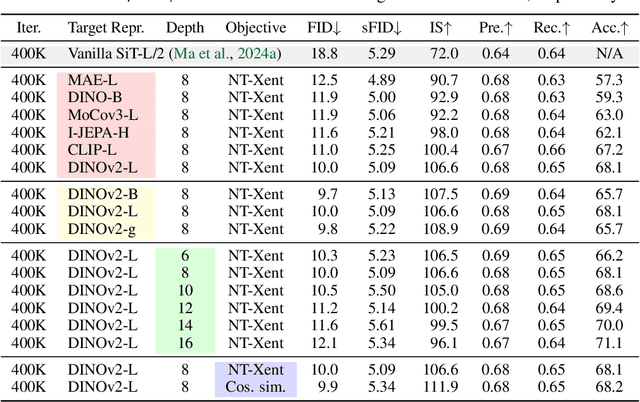
Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.
Improving Diffusion Models for Virtual Try-on
Mar 08, 2024This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario.
Direct Consistency Optimization for Compositional Text-to-Image Personalization
Feb 19, 2024Text-to-image (T2I) diffusion models, when fine-tuned on a few personal images, are able to generate visuals with a high degree of consistency. However, they still lack in synthesizing images of different scenarios or styles that are possible in the original pretrained models. To address this, we propose to fine-tune the T2I model by maximizing consistency to reference images, while penalizing the deviation from the pretrained model. We devise a novel training objective for T2I diffusion models that minimally fine-tunes the pretrained model to achieve consistency. Our method, dubbed \emph{Direct Consistency Optimization}, is as simple as regular diffusion loss, while significantly enhancing the compositionality of personalized T2I models. Also, our approach induces a new sampling method that controls the tradeoff between image fidelity and prompt fidelity. Lastly, we emphasize the necessity of using a comprehensive caption for reference images to further enhance the image-text alignment. We show the efficacy of the proposed method on the T2I personalization for subject, style, or both. In particular, our method results in a superior Pareto frontier to the baselines. Generated examples and codes are in our project page( https://dco-t2i.github.io/).