 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Massive-scale Partial Correlation Networks in Clinical Multi-omics Studies with HP-ACCORD
Dec 16, 2024



Graphical model estimation from modern multi-omics data requires a balance between statistical estimation performance and computational scalability. We introduce a novel pseudolikelihood-based graphical model framework that reparameterizes the target precision matrix while preserving sparsity pattern and estimates it by minimizing an $\ell_1$-penalized empirical risk based on a new loss function. The proposed estimator maintains estimation and selection consistency in various metrics under high-dimensional assumptions. The associated optimization problem allows for a provably fast computation algorithm using a novel operator-splitting approach and communication-avoiding distributed matrix multiplication. A high-performance computing implementation of our framework was tested in simulated data with up to one million variables demonstrating complex dependency structures akin to biological networks. Leveraging this scalability, we estimated partial correlation network from a dual-omic liver cancer data set. The co-expression network estimated from the ultrahigh-dimensional data showed superior specificity in prioritizing key transcription factors and co-activators by excluding the impact of epigenomic regulation, demonstrating the value of computational scalability in multi-omic data analysis. %derived from the gene expression data.
Controllable Human Image Generation with Personalized Multi-Garments
Nov 25, 2024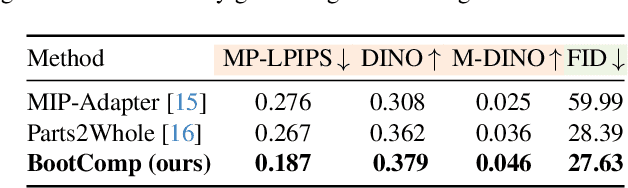

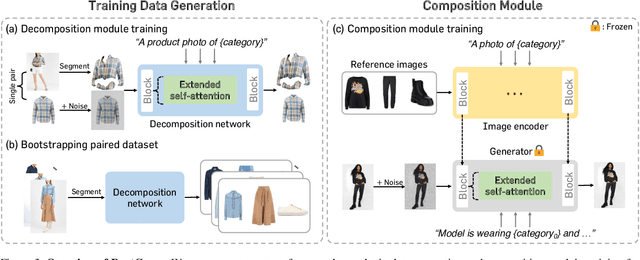
We present BootComp, a novel framework based on text-to-image diffusion models for controllable human image generation with multiple reference garments. Here, the main bottleneck is data acquisition for training: collecting a large-scale dataset of high-quality reference garment images per human subject is quite challenging, i.e., ideally, one needs to manually gather every single garment photograph worn by each human. To address this, we propose a data generation pipeline to construct a large synthetic dataset, consisting of human and multiple-garment pairs, by introducing a model to extract any reference garment images from each human image. To ensure data quality, we also propose a filtering strategy to remove undesirable generated data based on measuring perceptual similarities between the garment presented in human image and extracted garment. Finally, by utilizing the constructed synthetic dataset, we train a diffusion model having two parallel denoising paths that use multiple garment images as conditions to generate human images while preserving their fine-grained details. We further show the wide-applicability of our framework by adapting it to different types of reference-based generation in the fashion domain, including virtual try-on, and controllable human image generation with other conditions, e.g., pose, face, etc.
Exploiting Preferences in Loss Functions for Sequential Recommendation via Weak Transitivity
Aug 01, 2024



A choice of optimization objective is immensely pivotal in the design of a recommender system as it affects the general modeling process of a user's intent from previous interactions. Existing approaches mainly adhere to three categories of loss functions: pairwise, pointwise, and setwise loss functions. Despite their effectiveness, a critical and common drawback of such objectives is viewing the next observed item as a unique positive while considering all remaining items equally negative. Such a binary label assignment is generally limited to assuring a higher recommendation score of the positive item, neglecting potential structures induced by varying preferences between other unobserved items. To alleviate this issue, we propose a novel method that extends original objectives to explicitly leverage the different levels of preferences as relative orders between their scores. Finally, we demonstrate the superior performance of our method compared to baseline objectives.
Improving Diffusion Models for Virtual Try-on
Mar 08, 2024This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario.
Adiabatic Persistent Contrastive Divergence Learning
Feb 14, 2017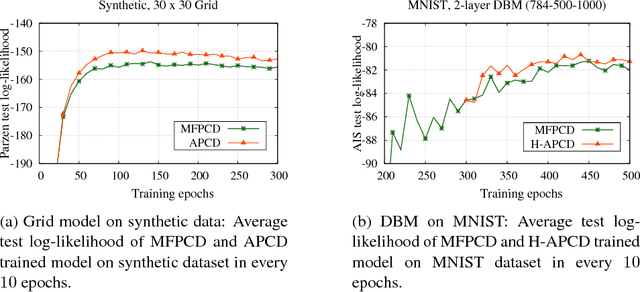

This paper studies the problem of parameter learning in probabilistic graphical models having latent variables, where the standard approach is the expectation maximization algorithm alternating expectation (E) and maximization (M) steps. However, both E and M steps are computationally intractable for high dimensional data, while the substitution of one step to a faster surrogate for combating against intractability can often cause failure in convergence. We propose a new learning algorithm which is computationally efficient and provably ensures convergence to a correct optimum. Its key idea is to run only a few cycles of Markov Chains (MC) in both E and M steps. Such an idea of running incomplete MC has been well studied only for M step in the literature, called Contrastive Divergence (CD) learning. While such known CD-based schemes find approximated gradients of the log-likelihood via the mean-field approach in E step, our proposed algorithm does exact ones via MC algorithms in both steps due to the multi-time-scale stochastic approximation theory. Despite its theoretical guarantee in convergence, the proposed scheme might suffer from the slow mixing of MC in E step. To tackle it, we also propose a hybrid approach applying both mean-field and MC approximation in E step, where the hybrid approach outperforms the bare mean-field CD scheme in our experiments on real-world datasets.