 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Motion Dynamics of Image-to-Video Models via Adaptive Low-Pass Guidance
Jun 10, 2025



Recent text-to-video (T2V) models have demonstrated strong capabilities in producing high-quality, dynamic videos. To improve the visual controllability, recent works have considered fine-tuning pre-trained T2V models to support image-to-video (I2V) generation. However, such adaptation frequently suppresses motion dynamics of generated outputs, resulting in more static videos compared to their T2V counterparts. In this work, we analyze this phenomenon and identify that it stems from the premature exposure to high-frequency details in the input image, which biases the sampling process toward a shortcut trajectory that overfits to the static appearance of the reference image. To address this, we propose adaptive low-pass guidance (ALG), a simple fix to the I2V model sampling procedure to generate more dynamic videos without compromising per-frame image quality. Specifically, ALG adaptively modulates the frequency content of the conditioning image by applying low-pass filtering at the early stage of denoising. Extensive experiments demonstrate that ALG significantly improves the temporal dynamics of generated videos, while preserving image fidelity and text alignment. Especially, under VBench-I2V test suite, ALG achieves an average improvement of 36% in dynamic degree without a significant drop in video quality or image fidelity.
Controllable Human Image Generation with Personalized Multi-Garments
Nov 25, 2024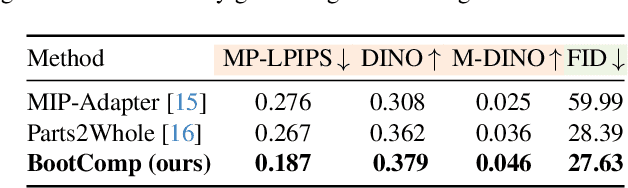
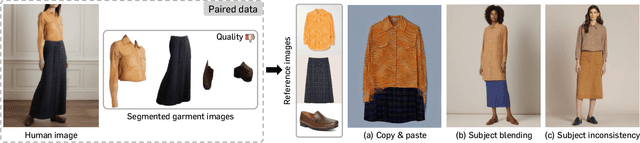

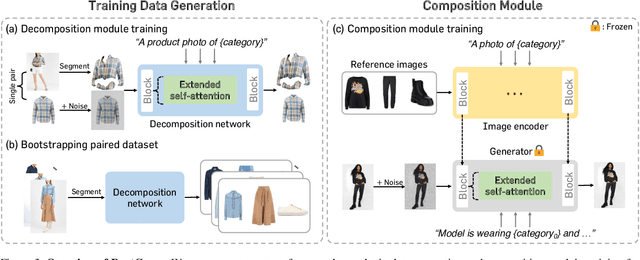
We present BootComp, a novel framework based on text-to-image diffusion models for controllable human image generation with multiple reference garments. Here, the main bottleneck is data acquisition for training: collecting a large-scale dataset of high-quality reference garment images per human subject is quite challenging, i.e., ideally, one needs to manually gather every single garment photograph worn by each human. To address this, we propose a data generation pipeline to construct a large synthetic dataset, consisting of human and multiple-garment pairs, by introducing a model to extract any reference garment images from each human image. To ensure data quality, we also propose a filtering strategy to remove undesirable generated data based on measuring perceptual similarities between the garment presented in human image and extracted garment. Finally, by utilizing the constructed synthetic dataset, we train a diffusion model having two parallel denoising paths that use multiple garment images as conditions to generate human images while preserving their fine-grained details. We further show the wide-applicability of our framework by adapting it to different types of reference-based generation in the fashion domain, including virtual try-on, and controllable human image generation with other conditions, e.g., pose, face, etc.
Improving Diffusion Models for Virtual Try-on
Mar 08, 2024This paper considers image-based virtual try-on, which renders an image of a person wearing a curated garment, given a pair of images depicting the person and the garment, respectively. Previous works adapt existing exemplar-based inpainting diffusion models for virtual try-on to improve the naturalness of the generated visuals compared to other methods (e.g., GAN-based), but they fail to preserve the identity of the garments. To overcome this limitation, we propose a novel diffusion model that improves garment fidelity and generates authentic virtual try-on images. Our method, coined IDM-VTON, uses two different modules to encode the semantics of garment image; given the base UNet of the diffusion model, 1) the high-level semantics extracted from a visual encoder are fused to the cross-attention layer, and then 2) the low-level features extracted from parallel UNet are fused to the self-attention layer. In addition, we provide detailed textual prompts for both garment and person images to enhance the authenticity of the generated visuals. Finally, we present a customization method using a pair of person-garment images, which significantly improves fidelity and authenticity. Our experimental results show that our method outperforms previous approaches (both diffusion-based and GAN-based) in preserving garment details and generating authentic virtual try-on images, both qualitatively and quantitatively. Furthermore, the proposed customization method demonstrates its effectiveness in a real-world scenario.