 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-aligned Latent Reasoning for Multi-modal Large Language Model
Feb 04, 2026Despite recent advancements in Multi-modal Large Language Models (MLLMs) on diverse understanding tasks, these models struggle to solve problems which require extensive multi-step reasoning. This is primarily due to the progressive dilution of visual information during long-context generation, which hinders their ability to fully exploit test-time scaling. To address this issue, we introduce Vision-aligned Latent Reasoning (VaLR), a simple, yet effective reasoning framework that dynamically generates vision-aligned latent tokens before each Chain of Thought reasoning step, guiding the model to reason based on perceptual cues in the latent space. Specifically, VaLR is trained to preserve visual knowledge during reasoning by aligning intermediate embeddings of MLLM with those from vision encoders. Empirical results demonstrate that VaLR consistently outperforms existing approaches across a wide range of benchmarks requiring long-context understanding or precise visual perception, while exhibiting test-time scaling behavior not observed in prior MLLMs. In particular, VaLR improves the performance significantly from 33.0% to 52.9% on VSI-Bench, achieving a 19.9%p gain over Qwen2.5-VL.
Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
Oct 31, 2025Recently, augmenting Vision-Language-Action models (VLAs) with world modeling has shown promise in improving robotic policy learning. However, it remains challenging to jointly predict next-state observations and action sequences because of the inherent difference between the two modalities. To address this, we propose DUal-STream diffusion (DUST), a world-model augmented VLA framework that handles the modality conflict and enhances the performance of VLAs across diverse tasks. Specifically, we propose a multimodal diffusion transformer architecture that explicitly maintains separate modality streams while still enabling cross-modal knowledge sharing. In addition, we introduce independent noise perturbations for each modality and a decoupled flow-matching loss. This design enables the model to learn the joint distribution in a bidirectional manner while avoiding the need for a unified latent space. Based on the decoupling of modalities during training, we also introduce a joint sampling method that supports test-time scaling, where action and vision tokens evolve asynchronously at different rates. Through experiments on simulated benchmarks such as RoboCasa and GR-1, DUST achieves up to 6% gains over baseline methods, while our test-time scaling approach provides an additional 2-5% boost. On real-world tasks with the Franka Research 3, DUST improves success rates by 13%, confirming its effectiveness beyond simulation. Furthermore, pre-training on action-free videos from BridgeV2 yields significant transfer gains on RoboCasa, underscoring DUST's potential for large-scale VLA pretraining.
ContextVLA: Vision-Language-Action Model with Amortized Multi-Frame Context
Oct 05, 2025Leveraging temporal context is crucial for success in partially observable robotic tasks. However, prior work in behavior cloning has demonstrated inconsistent performance gains when using multi-frame observations. In this paper, we introduce ContextVLA, a policy model that robustly improves robotic task performance by effectively leveraging multi-frame observations. Our approach is motivated by the key observation that Vision-Language-Action models (VLA), i.e., policy models built upon a Vision-Language Model (VLM), more effectively utilize multi-frame observations for action generation. This suggests that VLMs' inherent temporal understanding capability enables them to extract more meaningful context from multi-frame observations. However, the high dimensionality of video inputs introduces significant computational overhead, making VLA training and inference inefficient. To address this, ContextVLA compresses past observations into a single context token, allowing the policy to efficiently leverage temporal context for action generation. Our experiments show that ContextVLA consistently improves over single-frame VLAs and achieves the benefits of full multi-frame training but with reduced training and inference times.
HAMLET: Switch your Vision-Language-Action Model into a History-Aware Policy
Oct 02, 2025Inherently, robotic manipulation tasks are history-dependent: leveraging past context could be beneficial. However, most existing Vision-Language-Action models (VLAs) have been designed without considering this aspect, i.e., they rely solely on the current observation, ignoring preceding context. In this paper, we propose HAMLET, a scalable framework to adapt VLAs to attend to the historical context during action prediction. Specifically, we introduce moment tokens that compactly encode perceptual information at each timestep. Their representations are initialized with time-contrastive learning, allowing them to better capture temporally distinctive aspects. Next, we employ a lightweight memory module that integrates the moment tokens across past timesteps into memory features, which are then leveraged for action prediction. Through empirical evaluation, we show that HAMLET successfully transforms a state-of-the-art VLA into a history-aware policy, especially demonstrating significant improvements on long-horizon tasks that require historical context. In particular, on top of GR00T N1.5, HAMLET achieves an average success rate of 76.4% on history-dependent real-world tasks, surpassing the baseline performance by 47.2%. Furthermore, HAMLET pushes prior art performance from 64.1% to 66.4% on RoboCasa Kitchen (100-demo setup) and from 95.6% to 97.7% on LIBERO, highlighting its effectiveness even under generic robot-manipulation benchmarks.
Contrastive Representation Regularization for Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.
Collaborative LLM Inference via Planning for Efficient Reasoning
Jun 13, 2025



Large language models (LLMs) excel at complex reasoning tasks, but those with strong capabilities (e.g., whose numbers of parameters are larger than 100B) are often accessible only through paid APIs, making them too costly for applications of frequent use. In contrast, smaller open-sourced LLMs (e.g., whose numbers of parameters are less than 3B) are freely available and easy to deploy locally (e.g., under a single GPU having 8G VRAM), but lack suff icient reasoning ability. This trade-off raises a natural question: can small (free) and large (costly) models collaborate at test time to combine their strengths? We propose a test-time collaboration framework in which a planner model first generates a plan, defined as a distilled and high-level abstraction of the problem. This plan serves as a lightweight intermediate that guides a reasoner model, which generates a complete solution. Small and large models take turns acting as planner and reasoner, exchanging plans in a multi-round cascade to collaboratively solve complex tasks. Our method achieves accuracy comparable to strong proprietary models alone, while significantly reducing reliance on paid inference. These results highlight planning as an effective prior for orchestrating cost-aware, cross-model inference under real-world deployment constraints.
CLIP Meets Diffusion: A Synergistic Approach to Anomaly Detection
Jun 13, 2025Anomaly detection is a complex problem due to the ambiguity in defining anomalies, the diversity of anomaly types (e.g., local and global defect), and the scarcity of training data. As such, it necessitates a comprehensive model capable of capturing both low-level and high-level features, even with limited data. To address this, we propose CLIPFUSION, a method that leverages both discriminative and generative foundation models. Specifically, the CLIP-based discriminative model excels at capturing global features, while the diffusion-based generative model effectively captures local details, creating a synergistic and complementary approach. Notably, we introduce a methodology for utilizing cross-attention maps and feature maps extracted from diffusion models specifically for anomaly detection. Experimental results on benchmark datasets (MVTec-AD, VisA) demonstrate that CLIPFUSION consistently outperforms baseline methods, achieving outstanding performance in both anomaly segmentation and classification. We believe that our method underscores the effectiveness of multi-modal and multi-model fusion in tackling the multifaceted challenges of anomaly detection, providing a scalable solution for real-world applications.
Enhancing Motion Dynamics of Image-to-Video Models via Adaptive Low-Pass Guidance
Jun 10, 2025



Recent text-to-video (T2V) models have demonstrated strong capabilities in producing high-quality, dynamic videos. To improve the visual controllability, recent works have considered fine-tuning pre-trained T2V models to support image-to-video (I2V) generation. However, such adaptation frequently suppresses motion dynamics of generated outputs, resulting in more static videos compared to their T2V counterparts. In this work, we analyze this phenomenon and identify that it stems from the premature exposure to high-frequency details in the input image, which biases the sampling process toward a shortcut trajectory that overfits to the static appearance of the reference image. To address this, we propose adaptive low-pass guidance (ALG), a simple fix to the I2V model sampling procedure to generate more dynamic videos without compromising per-frame image quality. Specifically, ALG adaptively modulates the frequency content of the conditioning image by applying low-pass filtering at the early stage of denoising. Extensive experiments demonstrate that ALG significantly improves the temporal dynamics of generated videos, while preserving image fidelity and text alignment. Especially, under VBench-I2V test suite, ALG achieves an average improvement of 36% in dynamic degree without a significant drop in video quality or image fidelity.
FontAdapter: Instant Font Adaptation in Visual Text Generation
Jun 06, 2025

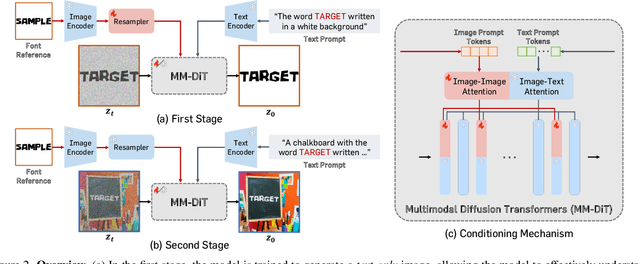
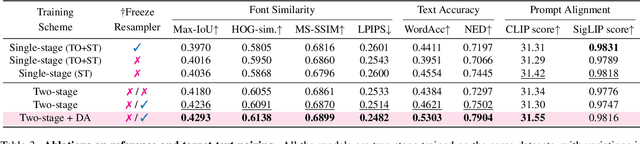
Text-to-image diffusion models have significantly improved the seamless integration of visual text into diverse image contexts. Recent approaches further improve control over font styles through fine-tuning with predefined font dictionaries. However, adapting unseen fonts outside the preset is computationally expensive, often requiring tens of minutes, making real-time customization impractical. In this paper, we present FontAdapter, a framework that enables visual text generation in unseen fonts within seconds, conditioned on a reference glyph image. To this end, we find that direct training on font datasets fails to capture nuanced font attributes, limiting generalization to new glyphs. To overcome this, we propose a two-stage curriculum learning approach: FontAdapter first learns to extract font attributes from isolated glyphs and then integrates these styles into diverse natural backgrounds. To support this two-stage training scheme, we construct synthetic datasets tailored to each stage, leveraging large-scale online fonts effectively. Experiments demonstrate that FontAdapter enables high-quality, robust font customization across unseen fonts without additional fine-tuning during inference. Furthermore, it supports visual text editing, font style blending, and cross-lingual font transfer, positioning FontAdapter as a versatile framework for font customization tasks.
Accelerated Test-Time Scaling with Model-Free Speculative Sampling
Jun 05, 2025Language models have demonstrated remarkable capabilities in reasoning tasks through test-time scaling techniques like best-of-N sampling and tree search. However, these approaches often demand substantial computational resources, creating a critical trade-off between performance and efficiency. We introduce STAND (STochastic Adaptive N-gram Drafting), a novel model-free speculative decoding approach that leverages the inherent redundancy in reasoning trajectories to achieve significant acceleration without compromising accuracy. Our analysis reveals that reasoning paths frequently reuse similar reasoning patterns, enabling efficient model-free token prediction without requiring separate draft models. By introducing stochastic drafting and preserving probabilistic information through a memory-efficient logit-based N-gram module, combined with optimized Gumbel-Top-K sampling and data-driven tree construction, STAND significantly improves token acceptance rates. Extensive evaluations across multiple models and reasoning tasks (AIME-2024, GPQA-Diamond, and LiveCodeBench) demonstrate that STAND reduces inference latency by 60-65% compared to standard autoregressive decoding while maintaining accuracy. Furthermore, STAND outperforms state-of-the-art speculative decoding methods by 14-28% in throughput and shows strong performance even in single-trajectory scenarios, reducing inference latency by 48-58%. As a model-free approach, STAND can be applied to any existing language model without additional training, being a powerful plug-and-play solution for accelerating language model reasoning.