 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmoVid: Relightful Video Portrait Harmonization
May 27, 2026We present a method for harmonizing the lighting of a foreground video to match a target background scene, adjusting shadows, color tone, and illumination intensity (relightful harmonization). Unlike images, acquiring labeled data for videos, where identical motions are recorded under different lighting conditions, is practically infeasible and non-scalable. While one way to create such paired data is to apply existing image-based harmonization models frame by frame to a video, the resulting outputs often suffer from significant temporal jitters. We overcome this problem by introducing a novel lighting deflickering model that can stabilize the global and local lighting flickering artifacts. Our video diffusion model learns from these upgraded deflickered data with a volume of real and synthetic videos to generate high-quality video harmonization results. We further propose an asymmetric alpha mask conditioning technique to learn the clean boundaries from real videos. Experiments demonstrate that our model achieves strong temporal coherence, naturalness, cleaner boundaries, and physically meaningful lighting behavior, while maintaining strong relighting expressiveness compared to prior image-based and video-based harmonization methods.
DAGE: Dual-Stream Architecture for Efficient and Fine-Grained Geometry Estimation
Mar 04, 2026Estimating accurate, view-consistent geometry and camera poses from uncalibrated multi-view/video inputs remains challenging - especially at high spatial resolutions and over long sequences. We present DAGE, a dual-stream transformer whose main novelty is to disentangle global coherence from fine detail. A low-resolution stream operates on aggressively downsampled frames with alternating frame/global attention to build a view-consistent representation and estimate cameras efficiently, while a high-resolution stream processes the original images per-frame to preserve sharp boundaries and small structures. A lightweight adapter fuses these streams via cross-attention, injecting global context without disturbing the pretrained single-frame pathway. This design scales resolution and clip length independently, supports inputs up to 2K, and maintains practical inference cost. DAGE delivers sharp depth/pointmaps, strong cross-view consistency, and accurate poses, establishing new state-of-the-art results for video geometry estimation and multi-view reconstruction.
VideoMaMa: Mask-Guided Video Matting via Generative Prior
Jan 20, 2026Generalizing video matting models to real-world videos remains a significant challenge due to the scarcity of labeled data. To address this, we present Video Mask-to-Matte Model (VideoMaMa) that converts coarse segmentation masks into pixel accurate alpha mattes, by leveraging pretrained video diffusion models. VideoMaMa demonstrates strong zero-shot generalization to real-world footage, even though it is trained solely on synthetic data. Building on this capability, we develop a scalable pseudo-labeling pipeline for large-scale video matting and construct the Matting Anything in Video (MA-V) dataset, which offers high-quality matting annotations for more than 50K real-world videos spanning diverse scenes and motions. To validate the effectiveness of this dataset, we fine-tune the SAM2 model on MA-V to obtain SAM2-Matte, which outperforms the same model trained on existing matting datasets in terms of robustness on in-the-wild videos. These findings emphasize the importance of large-scale pseudo-labeled video matting and showcase how generative priors and accessible segmentation cues can drive scalable progress in video matting research.
Multi-Granular Spatio-Temporal Token Merging for Training-Free Acceleration of Video LLMs
Jul 10, 2025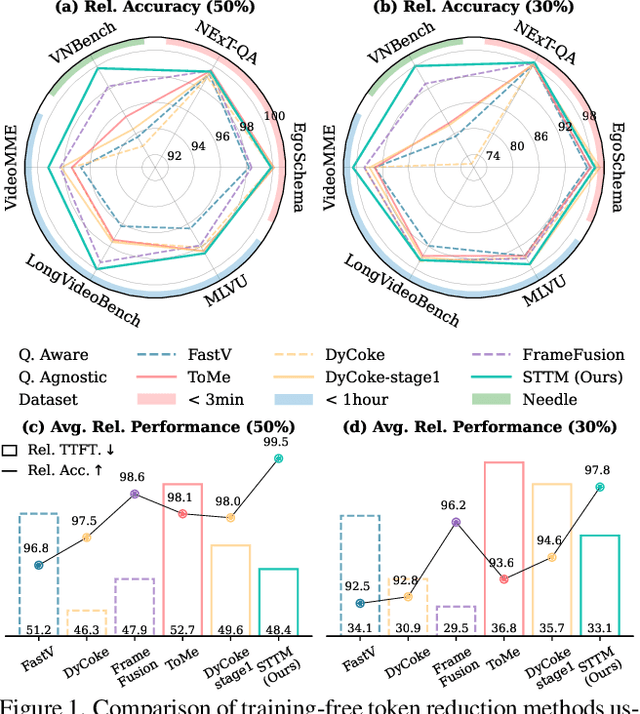

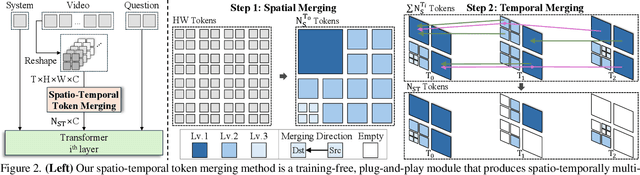

Video large language models (LLMs) achieve strong video understanding by leveraging a large number of spatio-temporal tokens, but suffer from quadratic computational scaling with token count. To address this, we propose a training-free spatio-temporal token merging method, named STTM. Our key insight is to exploit local spatial and temporal redundancy in video data which has been overlooked in prior work. STTM first transforms each frame into multi-granular spatial tokens using a coarse-to-fine search over a quadtree structure, then performs directed pairwise merging across the temporal dimension. This decomposed merging approach outperforms existing token reduction methods across six video QA benchmarks. Notably, STTM achieves a 2$\times$ speed-up with only a 0.5% accuracy drop under a 50% token budget, and a 3$\times$ speed-up with just a 2% drop under a 30% budget. Moreover, STTM is query-agnostic, allowing KV cache reuse across different questions for the same video. The project page is available at https://www.jshyun.me/projects/sttm.
Learning to Track Any Points from Human Motion
Jul 08, 2025



Human motion, with its inherent complexities, such as non-rigid deformations, articulated movements, clothing distortions, and frequent occlusions caused by limbs or other individuals, provides a rich and challenging source of supervision that is crucial for training robust and generalizable point trackers. Despite the suitability of human motion, acquiring extensive training data for point tracking remains difficult due to laborious manual annotation. Our proposed pipeline, AnthroTAP, addresses this by proposing an automated pipeline to generate pseudo-labeled training data, leveraging the Skinned Multi-Person Linear (SMPL) model. We first fit the SMPL model to detected humans in video frames, project the resulting 3D mesh vertices onto 2D image planes to generate pseudo-trajectories, handle occlusions using ray-casting, and filter out unreliable tracks based on optical flow consistency. A point tracking model trained on AnthroTAP annotated dataset achieves state-of-the-art performance on the TAP-Vid benchmark, surpassing other models trained on real videos while using 10,000 times less data and only 1 day in 4 GPUs, compared to 256 GPUs used in recent state-of-the-art.
FRAME: Pre-Training Video Feature Representations via Anticipation and Memory
Jun 05, 2025Dense video prediction tasks, such as object tracking and semantic segmentation, require video encoders that generate temporally consistent, spatially dense features for every frame. However, existing approaches fall short: image encoders like DINO or CLIP lack temporal awareness, while video models such as VideoMAE underperform compared to image encoders on dense prediction tasks. We address this gap with FRAME, a self-supervised video frame encoder tailored for dense video understanding. FRAME learns to predict current and future DINO patch features from past and present RGB frames, leading to spatially precise and temporally coherent representations. To our knowledge, FRAME is the first video encoder to leverage image-based models for dense prediction while outperforming them on tasks requiring fine-grained visual correspondence. As an auxiliary capability, FRAME aligns its class token with CLIP's semantic space, supporting language-driven tasks such as video classification. We evaluate FRAME across six dense prediction tasks on seven datasets, where it consistently outperforms image encoders and existing self-supervised video models. Despite its versatility, FRAME maintains a compact architecture suitable for a range of downstream applications.
Seurat: From Moving Points to Depth
Apr 20, 2025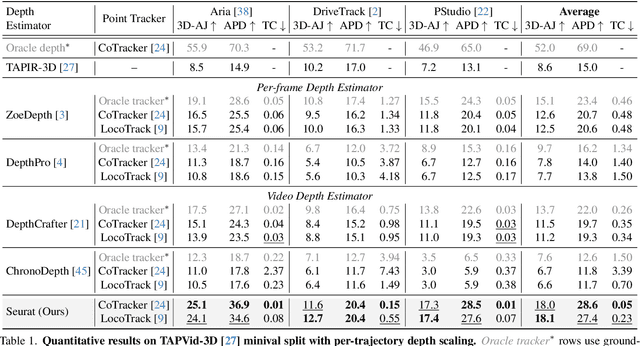
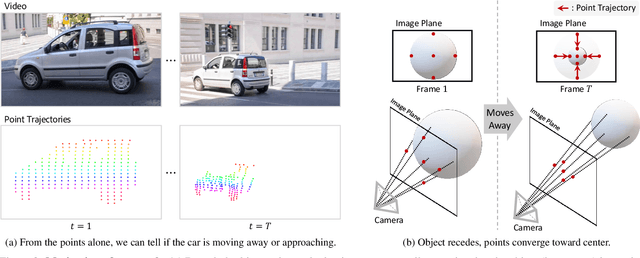
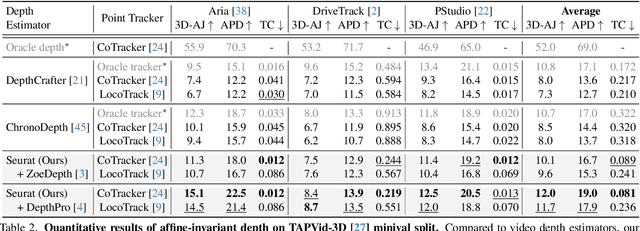
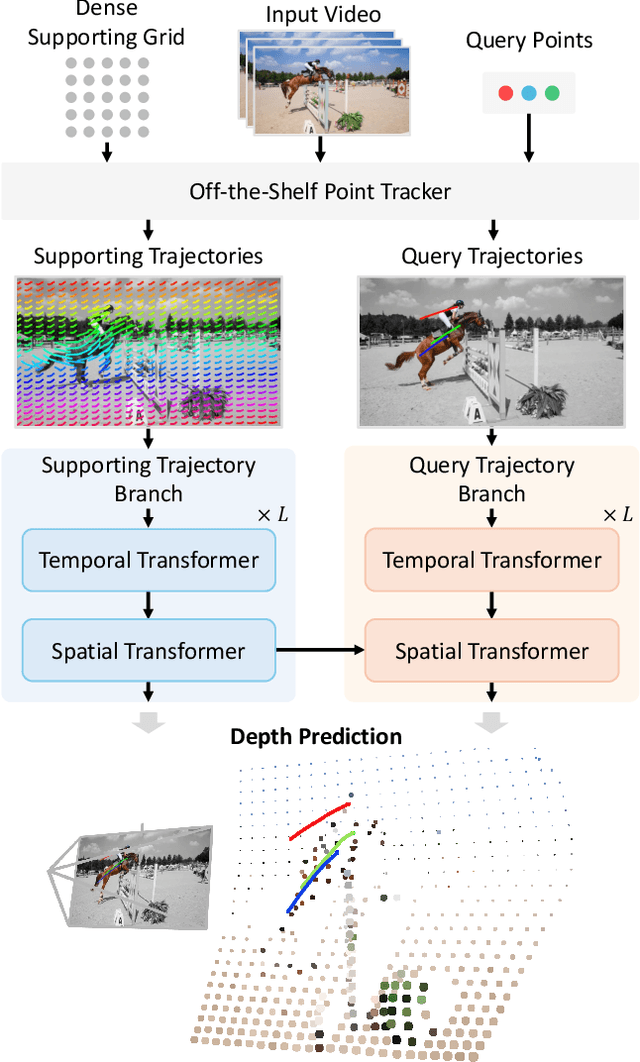
Accurate depth estimation from monocular videos remains challenging due to ambiguities inherent in single-view geometry, as crucial depth cues like stereopsis are absent. However, humans often perceive relative depth intuitively by observing variations in the size and spacing of objects as they move. Inspired by this, we propose a novel method that infers relative depth by examining the spatial relationships and temporal evolution of a set of tracked 2D trajectories. Specifically, we use off-the-shelf point tracking models to capture 2D trajectories. Then, our approach employs spatial and temporal transformers to process these trajectories and directly infer depth changes over time. Evaluated on the TAPVid-3D benchmark, our method demonstrates robust zero-shot performance, generalizing effectively from synthetic to real-world datasets. Results indicate that our approach achieves temporally smooth, high-accuracy depth predictions across diverse domains.
Tuning-Free Multi-Event Long Video Generation via Synchronized Coupled Sampling
Mar 11, 2025While recent advancements in text-to-video diffusion models enable high-quality short video generation from a single prompt, generating real-world long videos in a single pass remains challenging due to limited data and high computational costs. To address this, several works propose tuning-free approaches, i.e., extending existing models for long video generation, specifically using multiple prompts to allow for dynamic and controlled content changes. However, these methods primarily focus on ensuring smooth transitions between adjacent frames, often leading to content drift and a gradual loss of semantic coherence over longer sequences. To tackle such an issue, we propose Synchronized Coupled Sampling (SynCoS), a novel inference framework that synchronizes denoising paths across the entire video, ensuring long-range consistency across both adjacent and distant frames. Our approach combines two complementary sampling strategies: reverse and optimization-based sampling, which ensure seamless local transitions and enforce global coherence, respectively. However, directly alternating between these samplings misaligns denoising trajectories, disrupting prompt guidance and introducing unintended content changes as they operate independently. To resolve this, SynCoS synchronizes them through a grounded timestep and a fixed baseline noise, ensuring fully coupled sampling with aligned denoising paths. Extensive experiments show that SynCoS significantly improves multi-event long video generation, achieving smoother transitions and superior long-range coherence, outperforming previous approaches both quantitatively and qualitatively.
Exploring Temporally-Aware Features for Point Tracking
Jan 21, 2025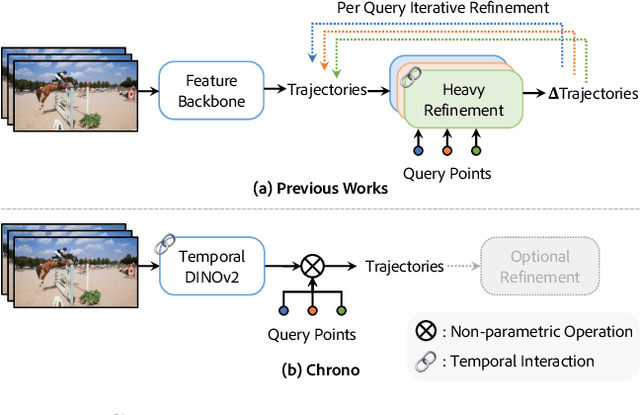
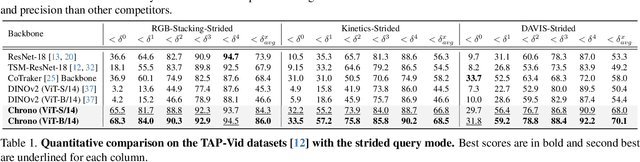


Point tracking in videos is a fundamental task with applications in robotics, video editing, and more. While many vision tasks benefit from pre-trained feature backbones to improve generalizability, point tracking has primarily relied on simpler backbones trained from scratch on synthetic data, which may limit robustness in real-world scenarios. Additionally, point tracking requires temporal awareness to ensure coherence across frames, but using temporally-aware features is still underexplored. Most current methods often employ a two-stage process: an initial coarse prediction followed by a refinement stage to inject temporal information and correct errors from the coarse stage. These approach, however, is computationally expensive and potentially redundant if the feature backbone itself captures sufficient temporal information. In this work, we introduce Chrono, a feature backbone specifically designed for point tracking with built-in temporal awareness. Leveraging pre-trained representations from self-supervised learner DINOv2 and enhanced with a temporal adapter, Chrono effectively captures long-term temporal context, enabling precise prediction even without the refinement stage. Experimental results demonstrate that Chrono achieves state-of-the-art performance in a refiner-free setting on the TAP-Vid-DAVIS and TAP-Vid-Kinetics datasets, among common feature backbones used in point tracking as well as DINOv2, with exceptional efficiency. Project page: https://cvlab-kaist.github.io/Chrono/
Generative Video Propagation
Dec 27, 2024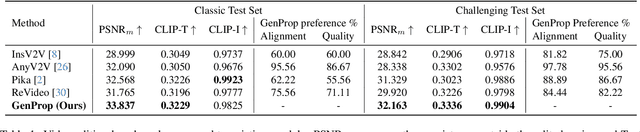
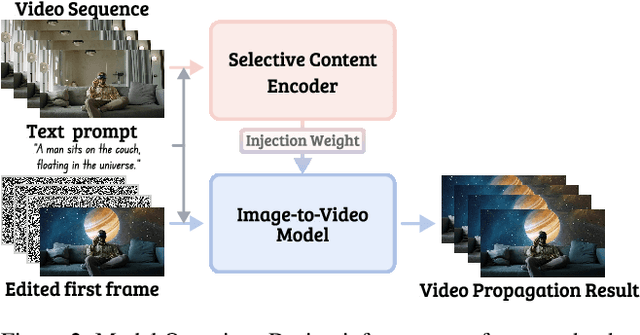
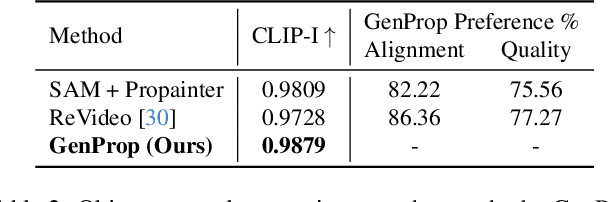
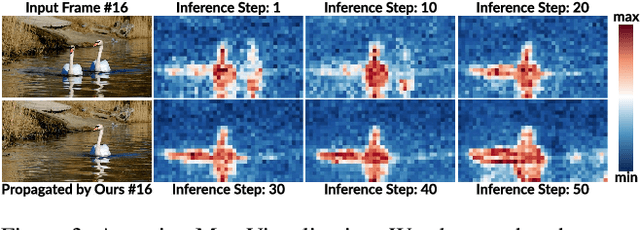
Large-scale video generation models have the inherent ability to realistically model natural scenes. In this paper, we demonstrate that through a careful design of a generative video propagation framework, various video tasks can be addressed in a unified way by leveraging the generative power of such models. Specifically, our framework, GenProp, encodes the original video with a selective content encoder and propagates the changes made to the first frame using an image-to-video generation model. We propose a data generation scheme to cover multiple video tasks based on instance-level video segmentation datasets. Our model is trained by incorporating a mask prediction decoder head and optimizing a region-aware loss to aid the encoder to preserve the original content while the generation model propagates the modified region. This novel design opens up new possibilities: In editing scenarios, GenProp allows substantial changes to an object's shape; for insertion, the inserted objects can exhibit independent motion; for removal, GenProp effectively removes effects like shadows and reflections from the whole video; for tracking, GenProp is capable of tracking objects and their associated effects together. Experiment results demonstrate the leading performance of our model in various video tasks, and we further provide in-depth analyses of the proposed framework.