 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoth Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing
Dec 12, 2025Recent advances in diffusion models (DMs) have achieved exceptional visual quality in image editing tasks. However, the global denoising dynamics of DMs inherently conflate local editing targets with the full-image context, leading to unintended modifications in non-target regions. In this paper, we shift our attention beyond DMs and turn to Masked Generative Transformers (MGTs) as an alternative approach to tackle this challenge. By predicting multiple masked tokens rather than holistic refinement, MGTs exhibit a localized decoding paradigm that endows them with the inherent capacity to explicitly preserve non-relevant regions during the editing process. Building upon this insight, we introduce the first MGT-based image editing framework, termed EditMGT. We first demonstrate that MGT's cross-attention maps provide informative localization signals for localizing edit-relevant regions and devise a multi-layer attention consolidation scheme that refines these maps to achieve fine-grained and precise localization. On top of these adaptive localization results, we introduce region-hold sampling, which restricts token flipping within low-attention areas to suppress spurious edits, thereby confining modifications to the intended target regions and preserving the integrity of surrounding non-target areas. To train EditMGT, we construct CrispEdit-2M, a high-resolution dataset spanning seven diverse editing categories. Without introducing additional parameters, we adapt a pre-trained text-to-image MGT into an image editing model through attention injection. Extensive experiments across four standard benchmarks demonstrate that, with fewer than 1B parameters, our model achieves similarity performance while enabling 6 times faster editing. Moreover, it delivers comparable or superior editing quality, with improvements of 3.6% and 17.6% on style change and style transfer tasks, respectively.
Training-Free Efficient Video Generation via Dynamic Token Carving
May 22, 2025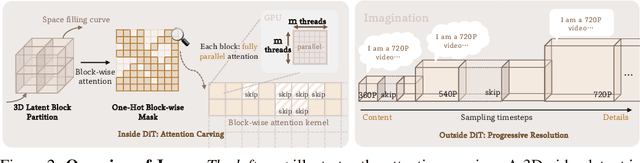
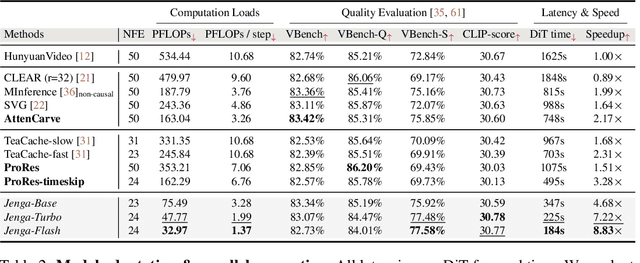
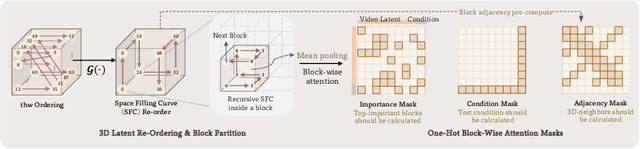
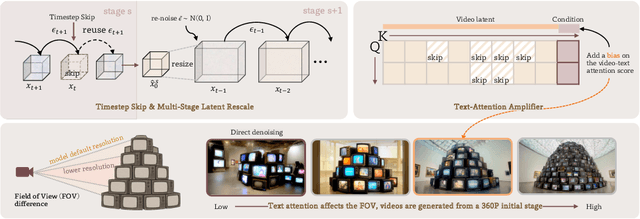
Despite the remarkable generation quality of video Diffusion Transformer (DiT) models, their practical deployment is severely hindered by extensive computational requirements. This inefficiency stems from two key challenges: the quadratic complexity of self-attention with respect to token length and the multi-step nature of diffusion models. To address these limitations, we present Jenga, a novel inference pipeline that combines dynamic attention carving with progressive resolution generation. Our approach leverages two key insights: (1) early denoising steps do not require high-resolution latents, and (2) later steps do not require dense attention. Jenga introduces a block-wise attention mechanism that dynamically selects relevant token interactions using 3D space-filling curves, alongside a progressive resolution strategy that gradually increases latent resolution during generation. Experimental results demonstrate that Jenga achieves substantial speedups across multiple state-of-the-art video diffusion models while maintaining comparable generation quality (8.83$\times$ speedup with 0.01\% performance drop on VBench). As a plug-and-play solution, Jenga enables practical, high-quality video generation on modern hardware by reducing inference time from minutes to seconds -- without requiring model retraining. Code: https://github.com/dvlab-research/Jenga
Generative Video Propagation
Dec 27, 2024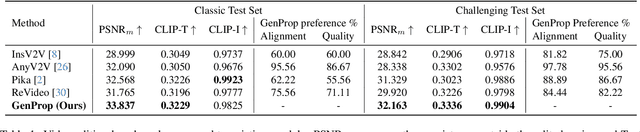
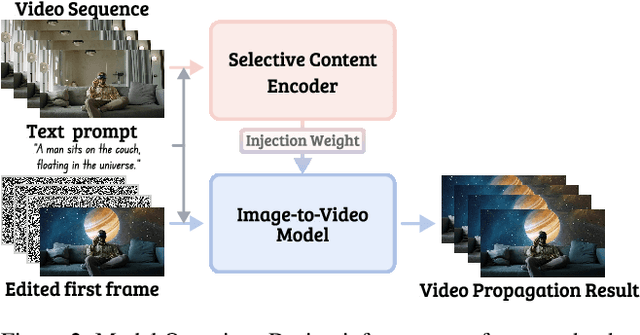
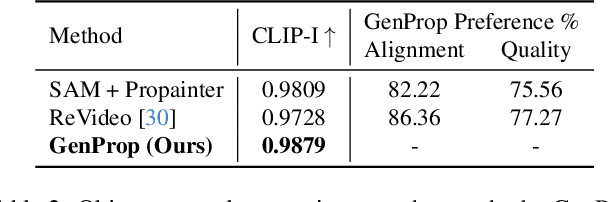
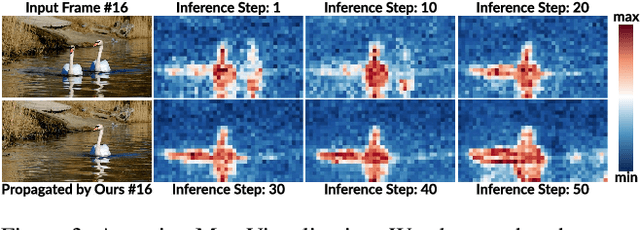
Large-scale video generation models have the inherent ability to realistically model natural scenes. In this paper, we demonstrate that through a careful design of a generative video propagation framework, various video tasks can be addressed in a unified way by leveraging the generative power of such models. Specifically, our framework, GenProp, encodes the original video with a selective content encoder and propagates the changes made to the first frame using an image-to-video generation model. We propose a data generation scheme to cover multiple video tasks based on instance-level video segmentation datasets. Our model is trained by incorporating a mask prediction decoder head and optimizing a region-aware loss to aid the encoder to preserve the original content while the generation model propagates the modified region. This novel design opens up new possibilities: In editing scenarios, GenProp allows substantial changes to an object's shape; for insertion, the inserted objects can exhibit independent motion; for removal, GenProp effectively removes effects like shadows and reflections from the whole video; for tracking, GenProp is capable of tracking objects and their associated effects together. Experiment results demonstrate the leading performance of our model in various video tasks, and we further provide in-depth analyses of the proposed framework.
Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models
Mar 27, 2024



In this work, we introduce Mini-Gemini, a simple and effective framework enhancing multi-modality Vision Language Models (VLMs). Despite the advancements in VLMs facilitating basic visual dialog and reasoning, a performance gap persists compared to advanced models like GPT-4 and Gemini. We try to narrow the gap by mining the potential of VLMs for better performance and any-to-any workflow from three aspects, i.e., high-resolution visual tokens, high-quality data, and VLM-guided generation. To enhance visual tokens, we propose to utilize an additional visual encoder for high-resolution refinement without increasing the visual token count. We further construct a high-quality dataset that promotes precise image comprehension and reasoning-based generation, expanding the operational scope of current VLMs. In general, Mini-Gemini further mines the potential of VLMs and empowers current frameworks with image understanding, reasoning, and generation simultaneously. Mini-Gemini supports a series of dense and MoE Large Language Models (LLMs) from 2B to 34B. It is demonstrated to achieve leading performance in several zero-shot benchmarks and even surpasses the developed private models. Code and models are available at https://github.com/dvlab-research/MiniGemini.
RL-GPT: Integrating Reinforcement Learning and Code-as-policy
Feb 29, 2024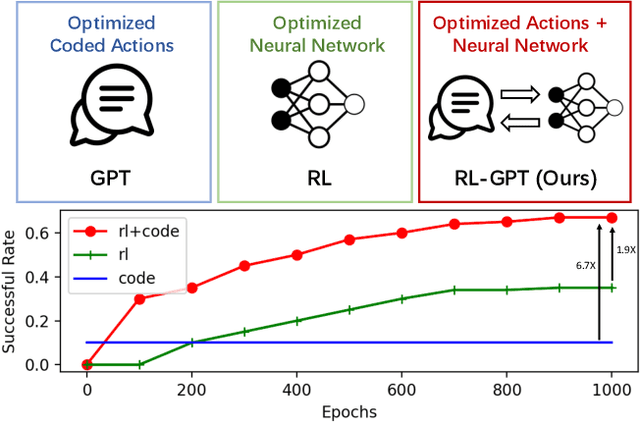

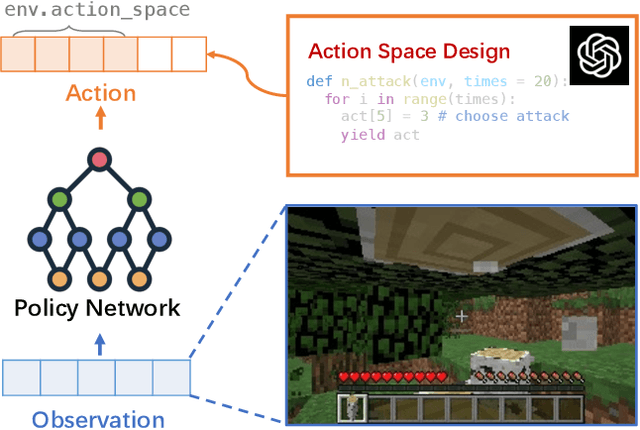

Large Language Models (LLMs) have demonstrated proficiency in utilizing various tools by coding, yet they face limitations in handling intricate logic and precise control. In embodied tasks, high-level planning is amenable to direct coding, while low-level actions often necessitate task-specific refinement, such as Reinforcement Learning (RL). To seamlessly integrate both modalities, we introduce a two-level hierarchical framework, RL-GPT, comprising a slow agent and a fast agent. The slow agent analyzes actions suitable for coding, while the fast agent executes coding tasks. This decomposition effectively focuses each agent on specific tasks, proving highly efficient within our pipeline. Our approach outperforms traditional RL methods and existing GPT agents, demonstrating superior efficiency. In the Minecraft game, it rapidly obtains diamonds within a single day on an RTX3090. Additionally, it achieves SOTA performance across all designated MineDojo tasks.
Direct Inversion: Boosting Diffusion-based Editing with 3 Lines of Code
Oct 19, 2023


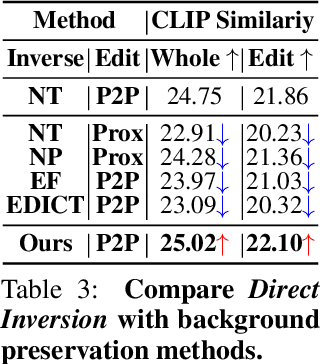
Text-guided diffusion models have revolutionized image generation and editing, offering exceptional realism and diversity. Specifically, in the context of diffusion-based editing, where a source image is edited according to a target prompt, the process commences by acquiring a noisy latent vector corresponding to the source image via the diffusion model. This vector is subsequently fed into separate source and target diffusion branches for editing. The accuracy of this inversion process significantly impacts the final editing outcome, influencing both essential content preservation of the source image and edit fidelity according to the target prompt. Prior inversion techniques aimed at finding a unified solution in both the source and target diffusion branches. However, our theoretical and empirical analyses reveal that disentangling these branches leads to a distinct separation of responsibilities for preserving essential content and ensuring edit fidelity. Building on this insight, we introduce "Direct Inversion," a novel technique achieving optimal performance of both branches with just three lines of code. To assess image editing performance, we present PIE-Bench, an editing benchmark with 700 images showcasing diverse scenes and editing types, accompanied by versatile annotations and comprehensive evaluation metrics. Compared to state-of-the-art optimization-based inversion techniques, our solution not only yields superior performance across 8 editing methods but also achieves nearly an order of speed-up.
Self-supervised Learning by View Synthesis
Apr 22, 2023



We present view-synthesis autoencoders (VSA) in this paper, which is a self-supervised learning framework designed for vision transformers. Different from traditional 2D pretraining methods, VSA can be pre-trained with multi-view data. In each iteration, the input to VSA is one view (or multiple views) of a 3D object and the output is a synthesized image in another target pose. The decoder of VSA has several cross-attention blocks, which use the source view as value, source pose as key, and target pose as query. They achieve cross-attention to synthesize the target view. This simple approach realizes large-angle view synthesis and learns spatial invariant representation, where the latter is decent initialization for transformers on downstream tasks, such as 3D classification on ModelNet40, ShapeNet Core55, and ScanObjectNN. VSA outperforms existing methods significantly for linear probing and is competitive for fine-tuning. The code will be made publicly available.
Video-P2P: Video Editing with Cross-attention Control
Mar 08, 2023



This paper presents Video-P2P, a novel framework for real-world video editing with cross-attention control. While attention control has proven effective for image editing with pre-trained image generation models, there are currently no large-scale video generation models publicly available. Video-P2P addresses this limitation by adapting an image generation diffusion model to complete various video editing tasks. Specifically, we propose to first tune a Text-to-Set (T2S) model to complete an approximate inversion and then optimize a shared unconditional embedding to achieve accurate video inversion with a small memory cost. For attention control, we introduce a novel decoupled-guidance strategy, which uses different guidance strategies for the source and target prompts. The optimized unconditional embedding for the source prompt improves reconstruction ability, while an initialized unconditional embedding for the target prompt enhances editability. Incorporating the attention maps of these two branches enables detailed editing. These technical designs enable various text-driven editing applications, including word swap, prompt refinement, and attention re-weighting. Video-P2P works well on real-world videos for generating new characters while optimally preserving their original poses and scenes. It significantly outperforms previous approaches.
Generative Model Watermarking Based on Human Visual System
Sep 30, 2022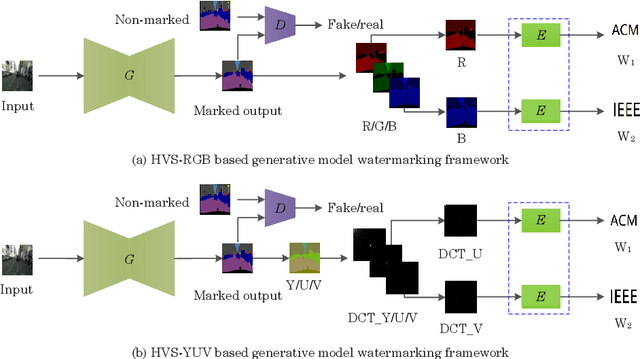
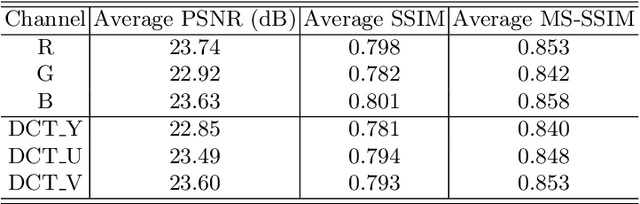


Intellectual property protection of deep neural networks is receiving attention from more and more researchers, and the latest research applies model watermarking to generative models for image processing. However, the existing watermarking methods designed for generative models do not take into account the effects of different channels of sample images on watermarking. As a result, the watermarking performance is still limited. To tackle this problem, in this paper, we first analyze the effects of embedding watermark information on different channels. Then, based on the characteristics of human visual system (HVS), we introduce two HVS-based generative model watermarking methods, which are realized in RGB color space and YUV color space respectively. In RGB color space, the watermark is embedded into the R and B channels based on the fact that HVS is more sensitive to G channel. In YUV color space, the watermark is embedded into the DCT domain of U and V channels based on the fact that HVS is more sensitive to brightness changes. Experimental results demonstrate the effectiveness of the proposed work, which improves the fidelity of the model to be protected and has good universality compared with previous methods.