 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Loss to Rule Them All: Marked Time-to-Event for Structured EHR Foundation Models
Jan 31, 2026Clinical events captured in Electronic Health Records (EHR) are irregularly sampled and may consist of a mixture of discrete events and numerical measurements, such as laboratory values or treatment dosages. The sequential nature of EHR, analogous to natural language, has motivated the use of next-token prediction to train prior EHR Foundation Models (FMs) over events. However, this training fails to capture the full structure of EHR. We propose ORA, a marked time-to-event pretraining objective that jointly models event timing and associated measurements. Across multiple datasets, downstream tasks, and model architectures, this objective consistently yields more generalizable representations than next-token prediction and pretraining losses that ignore continuous measurements. Importantly, the proposed objective yields improvements beyond traditional classification evaluation, including better regression and time-to-event prediction. Beyond introducing a new family of FMs, our results suggest a broader takeaway: pretraining objectives that account for EHR structure are critical for expanding downstream capabilities and generalizability
Visual Spatial Tuning
Nov 07, 2025Capturing spatial relationships from visual inputs is a cornerstone of human-like general intelligence. Several previous studies have tried to enhance the spatial awareness of Vision-Language Models (VLMs) by adding extra expert encoders, which brings extra overhead and usually harms general capabilities. To enhance the spatial ability in general architectures, we introduce Visual Spatial Tuning (VST), a comprehensive framework to cultivate VLMs with human-like visuospatial abilities, from spatial perception to reasoning. We first attempt to enhance spatial perception in VLMs by constructing a large-scale dataset termed VST-P, which comprises 4.1 million samples spanning 19 skills across single views, multiple images, and videos. Then, we present VST-R, a curated dataset with 135K samples that instruct models to reason in space. In particular, we adopt a progressive training pipeline: supervised fine-tuning to build foundational spatial knowledge, followed by reinforcement learning to further improve spatial reasoning abilities. Without the side-effect to general capabilities, the proposed VST consistently achieves state-of-the-art results on several spatial benchmarks, including $34.8\%$ on MMSI-Bench and $61.2\%$ on VSIBench. It turns out that the Vision-Language-Action models can be significantly enhanced with the proposed spatial tuning paradigm, paving the way for more physically grounded AI.
Grasp Any Region: Towards Precise, Contextual Pixel Understanding for Multimodal LLMs
Oct 22, 2025While Multimodal Large Language Models (MLLMs) excel at holistic understanding, they struggle in capturing the dense world with complex scenes, requiring fine-grained analysis of intricate details and object inter-relationships. Region-level MLLMs have been a promising step. However, previous attempts are generally optimized to understand given regions in isolation, neglecting crucial global contexts. To address this, we introduce Grasp Any Region (GAR) for comprehen- sive region-level visual understanding. Empowered by an effective RoI-aligned feature replay technique, GAR supports (1) precise perception by leveraging necessary global contexts, and (2) modeling interactions between multiple prompts. Together, it then naturally achieves (3) advanced compositional reasoning to answer specific free-form questions about any region, shifting the paradigm from passive description to active dialogue. Moreover, we construct GAR-Bench, which not only provides a more accurate evaluation of single-region comprehension, but also, more importantly, measures interactions and complex reasoning across multiple regions. Extensive experiments have demonstrated that GAR-1B not only maintains the state-of-the-art captioning capabilities, e.g., outperforming DAM-3B +4.5 on DLC-Bench, but also excels at modeling relationships between multiple prompts with advanced comprehension capabilities, even surpassing InternVL3-78B on GAR-Bench-VQA. More importantly, our zero-shot GAR-8B even outperforms in-domain VideoRefer-7B on VideoRefer-BenchQ, indicating its strong capabilities can be easily transferred to videos.
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Mixed-R1: Unified Reward Perspective For Reasoning Capability in Multimodal Large Language Models
May 30, 2025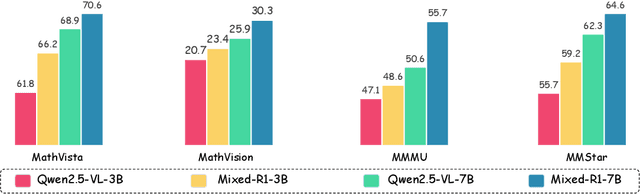
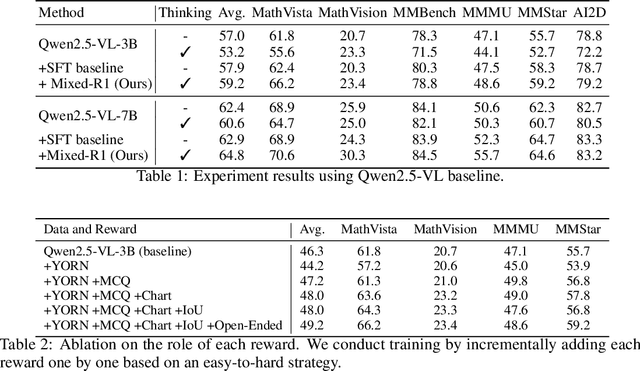
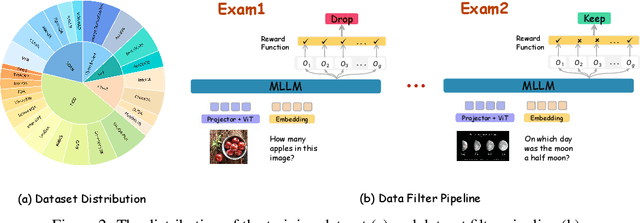

Recent works on large language models (LLMs) have successfully demonstrated the emergence of reasoning capabilities via reinforcement learning (RL). Although recent efforts leverage group relative policy optimization (GRPO) for MLLMs post-training, they constantly explore one specific aspect, such as grounding tasks, math problems, or chart analysis. There are no works that can leverage multi-source MLLM tasks for stable reinforcement learning. In this work, we present a unified perspective to solve this problem. We present Mixed-R1, a unified yet straightforward framework that contains a mixed reward function design (Mixed-Reward) and a mixed post-training dataset (Mixed-45K). We first design a data engine to select high-quality examples to build the Mixed-45K post-training dataset. Then, we present a Mixed-Reward design, which contains various reward functions for various MLLM tasks. In particular, it has four different reward functions: matching reward for binary answer or multiple-choice problems, chart reward for chart-aware datasets, IoU reward for grounding problems, and open-ended reward for long-form text responses such as caption datasets. To handle the various long-form text content, we propose a new open-ended reward named Bidirectional Max-Average Similarity (BMAS) by leveraging tokenizer embedding matching between the generated response and the ground truth. Extensive experiments show the effectiveness of our proposed method on various MLLMs, including Qwen2.5-VL and Intern-VL on various sizes. Our dataset and model are available at https://github.com/xushilin1/mixed-r1.
FoMoH: A clinically meaningful foundation model evaluation for structured electronic health records
May 22, 2025Foundation models hold significant promise in healthcare, given their capacity to extract meaningful representations independent of downstream tasks. This property has enabled state-of-the-art performance across several clinical applications trained on structured electronic health record (EHR) data, even in settings with limited labeled data, a prevalent challenge in healthcare. However, there is little consensus on these models' potential for clinical utility due to the lack of desiderata of comprehensive and meaningful tasks and sufficiently diverse evaluations to characterize the benefit over conventional supervised learning. To address this gap, we propose a suite of clinically meaningful tasks spanning patient outcomes, early prediction of acute and chronic conditions, including desiderata for robust evaluations. We evaluate state-of-the-art foundation models on EHR data consisting of 5 million patients from Columbia University Irving Medical Center (CUMC), a large urban academic medical center in New York City, across 14 clinically relevant tasks. We measure overall accuracy, calibration, and subpopulation performance to surface tradeoffs based on the choice of pre-training, tokenization, and data representation strategies. Our study aims to advance the empirical evaluation of structured EHR foundation models and guide the development of future healthcare foundation models.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Pixel-SAIL: Single Transformer For Pixel-Grounded Understanding
Apr 14, 2025



Multimodal Large Language Models (MLLMs) achieve remarkable performance for fine-grained pixel-level understanding tasks. However, all the works rely heavily on extra components, such as vision encoder (CLIP), segmentation experts, leading to high system complexity and limiting model scaling. In this work, our goal is to explore a highly simplified MLLM without introducing extra components. Our work is motivated by the recent works on Single trAnsformer as a unified vIsion-Language Model (SAIL) design, where these works jointly learn vision tokens and text tokens in transformers. We present Pixel-SAIL, a single transformer for pixel-wise MLLM tasks. In particular, we present three technical improvements on the plain baseline. First, we design a learnable upsampling module to refine visual token features. Secondly, we propose a novel visual prompt injection strategy to enable the single transformer to understand visual prompt inputs and benefit from the early fusion of visual prompt embeddings and vision tokens. Thirdly, we introduce a vision expert distillation strategy to efficiently enhance the single transformer's fine-grained feature extraction capability. In addition, we have collected a comprehensive pixel understanding benchmark (PerBench), using a manual check. It includes three tasks: detailed object description, visual prompt-based question answering, and visual-text referring segmentation. Extensive experiments on four referring segmentation benchmarks, one visual prompt benchmark, and our PerBench show that our Pixel-SAIL achieves comparable or even better results with a much simpler pipeline. Code and model will be released at https://github.com/magic-research/Sa2VA.
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
Feb 13, 2025



Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation. In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes. As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level. Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights: 1) Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results; 2) CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior; and 3) Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases. We hope MME-CoT serves as a foundation for advancing multimodal reasoning in LMMs. Project Page: https://mmecot.github.io/
Lyra: An Efficient and Speech-Centric Framework for Omni-Cognition
Dec 12, 2024



As Multi-modal Large Language Models (MLLMs) evolve, expanding beyond single-domain capabilities is essential to meet the demands for more versatile and efficient AI. However, previous omni-models have insufficiently explored speech, neglecting its integration with multi-modality. We introduce Lyra, an efficient MLLM that enhances multimodal abilities, including advanced long-speech comprehension, sound understanding, cross-modality efficiency, and seamless speech interaction. To achieve efficiency and speech-centric capabilities, Lyra employs three strategies: (1) leveraging existing open-source large models and a proposed multi-modality LoRA to reduce training costs and data requirements; (2) using a latent multi-modality regularizer and extractor to strengthen the relationship between speech and other modalities, thereby enhancing model performance; and (3) constructing a high-quality, extensive dataset that includes 1.5M multi-modal (language, vision, audio) data samples and 12K long speech samples, enabling Lyra to handle complex long speech inputs and achieve more robust omni-cognition. Compared to other omni-methods, Lyra achieves state-of-the-art performance on various vision-language, vision-speech, and speech-language benchmarks, while also using fewer computational resources and less training data.