 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Aware Structural Alignment for Zero-Shot Handwritten Chinese Character Recognition
Feb 03, 2026Zero-shot Handwritten Chinese Character Recognition (HCCR) aims to recognize unseen characters by leveraging radical-based semantic compositions. However, existing approaches often treat characters as flat radical sequences, neglecting the hierarchical topology and the uneven information density of different components. To address these limitations, we propose an Entropy-Aware Structural Alignment Network that bridges the visual-semantic gap through information-theoretic modeling. First, we introduce an Information Entropy Prior to dynamically modulate positional embeddings via multiplicative interaction, acting as a saliency detector that prioritizes discriminative roots over ubiquitous components. Second, we construct a Dual-View Radical Tree to extract multi-granularity structural features, which are integrated via an adaptive Sigmoid-based gating network to encode both global layout and local spatial roles. Finally, a Top-K Semantic Feature Fusion mechanism is devised to augment the decoding process by utilizing the centroid of semantic neighbors, effectively rectifying visual ambiguities through feature-level consensus. Extensive experiments demonstrate that our method establishes new state-of-the-art performance, significantly outperforming existing CLIP-based baselines in the challenging zero-shot setting. Furthermore, the framework exhibits exceptional data efficiency, demonstrating rapid adaptability with minimal support samples.
OSDEnhancer: Taming Real-World Space-Time Video Super-Resolution with One-Step Diffusion
Jan 28, 2026Diffusion models (DMs) have demonstrated exceptional success in video super-resolution (VSR), showcasing a powerful capacity for generating fine-grained details. However, their potential for space-time video super-resolution (STVSR), which necessitates not only recovering realistic visual content from low-resolution to high-resolution but also improving the frame rate with coherent temporal dynamics, remains largely underexplored. Moreover, existing STVSR methods predominantly address spatiotemporal upsampling under simplified degradation assumptions, which often struggle in real-world scenarios with complex unknown degradations. Such a high demand for reconstruction fidelity and temporal consistency makes the development of a robust STVSR framework particularly non-trivial. To address these challenges, we propose OSDEnhancer, a novel framework that, to the best of our knowledge, represents the first method to achieve real-world STVSR through an efficient one-step diffusion process. OSDEnhancer initializes essential spatiotemporal structures through a linear pre-interpolation strategy and pivots on training temporal refinement and spatial enhancement mixture of experts (TR-SE MoE), which allows distinct expert pathways to progressively learn robust, specialized representations for temporal coherence and spatial detail, further collaboratively reinforcing each other during inference. A bidirectional deformable variational autoencoder (VAE) decoder is further introduced to perform recurrent spatiotemporal aggregation and propagation, enhancing cross-frame reconstruction fidelity. Experiments demonstrate that the proposed method achieves state-of-the-art performance while maintaining superior generalization capability in real-world scenarios.
LoFT-LLM: Low-Frequency Time-Series Forecasting with Large Language Models
Dec 23, 2025Time-series forecasting in real-world applications such as finance and energy often faces challenges due to limited training data and complex, noisy temporal dynamics. Existing deep forecasting models typically supervise predictions using full-length temporal windows, which include substantial high-frequency noise and obscure long-term trends. Moreover, auxiliary variables containing rich domain-specific information are often underutilized, especially in few-shot settings. To address these challenges, we propose LoFT-LLM, a frequency-aware forecasting pipeline that integrates low-frequency learning with semantic calibration via a large language model (LLM). Firstly, a Patch Low-Frequency forecasting Module (PLFM) extracts stable low-frequency trends from localized spectral patches. Secondly, a residual learner then models high-frequency variations. Finally, a fine-tuned LLM refines the predictions by incorporating auxiliary context and domain knowledge through structured natural language prompts. Extensive experiments on financial and energy datasets demonstrate that LoFT-LLM significantly outperforms strong baselines under both full-data and few-shot regimes, delivering superior accuracy, robustness, and interpretability.
MCN-CL: Multimodal Cross-Attention Network and Contrastive Learning for Multimodal Emotion Recognition
Nov 14, 2025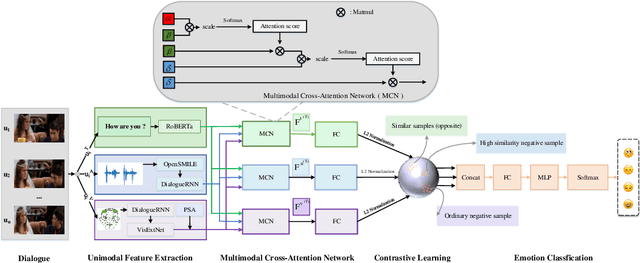
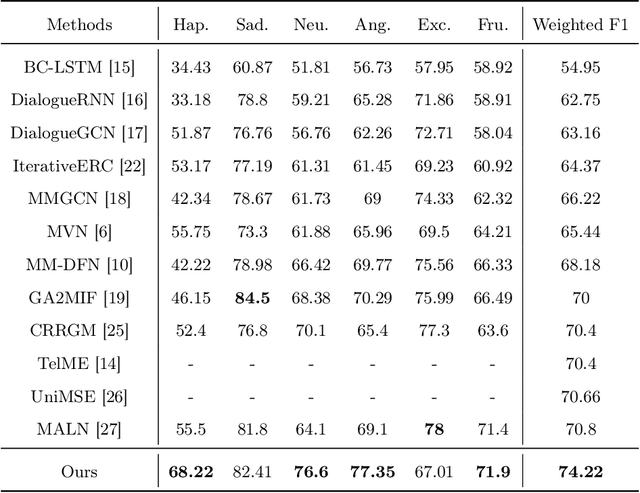
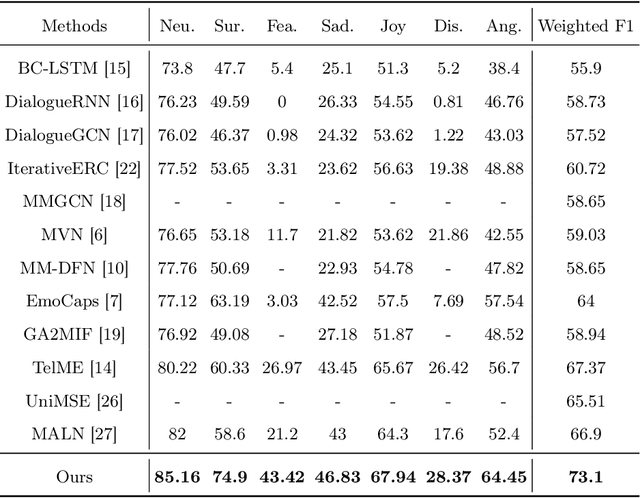
Multimodal emotion recognition plays a key role in many domains, including mental health monitoring, educational interaction, and human-computer interaction. However, existing methods often face three major challenges: unbalanced category distribution, the complexity of dynamic facial action unit time modeling, and the difficulty of feature fusion due to modal heterogeneity. With the explosive growth of multimodal data in social media scenarios, the need for building an efficient cross-modal fusion framework for emotion recognition is becoming increasingly urgent. To this end, this paper proposes Multimodal Cross-Attention Network and Contrastive Learning (MCN-CL) for multimodal emotion recognition. It uses a triple query mechanism and hard negative mining strategy to remove feature redundancy while preserving important emotional cues, effectively addressing the issues of modal heterogeneity and category imbalance. Experiment results on the IEMOCAP and MELD datasets show that our proposed method outperforms state-of-the-art approaches, with Weighted F1 scores improving by 3.42% and 5.73%, respectively.
FedeCouple: Fine-Grained Balancing of Global-Generalization and Local-Adaptability in Federated Learning
Nov 12, 2025
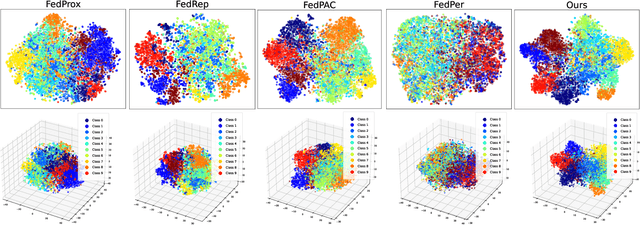
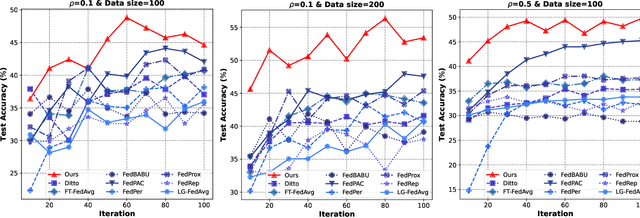
In privacy-preserving mobile network transmission scenarios with heterogeneous client data, personalized federated learning methods that decouple feature extractors and classifiers have demonstrated notable advantages in enhancing learning capability. However, many existing approaches primarily focus on feature space consistency and classification personalization during local training, often neglecting the local adaptability of the extractor and the global generalization of the classifier. This oversight results in insufficient coordination and weak coupling between the components, ultimately degrading the overall model performance. To address this challenge, we propose FedeCouple, a federated learning method that balances global generalization and local adaptability at a fine-grained level. Our approach jointly learns global and local feature representations while employing dynamic knowledge distillation to enhance the generalization of personalized classifiers. We further introduce anchors to refine the feature space; their strict locality and non-transmission inherently preserve privacy and reduce communication overhead. Furthermore, we provide a theoretical analysis proving that FedeCouple converges for nonconvex objectives, with iterates approaching a stationary point as the number of communication rounds increases. Extensive experiments conducted on five image-classification datasets demonstrate that FedeCouple consistently outperforms nine baseline methods in effectiveness, stability, scalability, and security. Notably, in experiments evaluating effectiveness, FedeCouple surpasses the best baseline by a significant margin of 4.3%.
LightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
Oct 27, 2025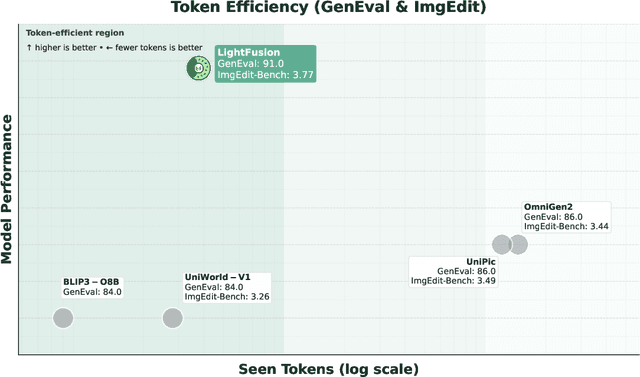
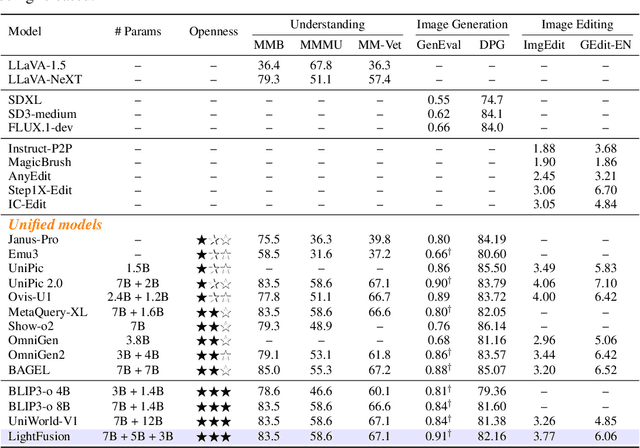
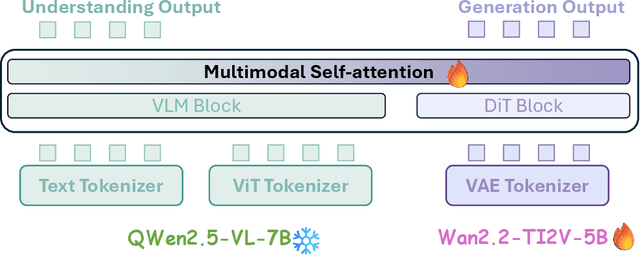
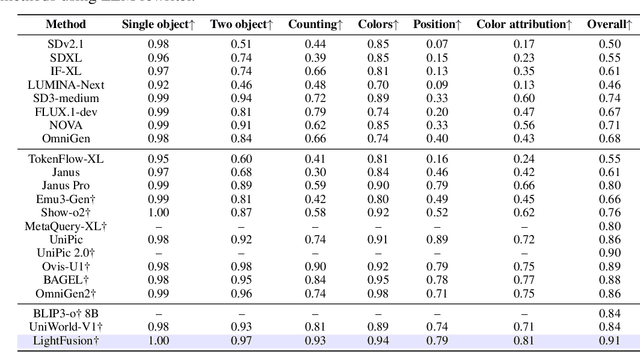
Unified multimodal models have recently shown remarkable gains in both capability and versatility, yet most leading systems are still trained from scratch and require substantial computational resources. In this paper, we show that competitive performance can be obtained far more efficiently by strategically fusing publicly available models specialized for either generation or understanding. Our key design is to retain the original blocks while additionally interleaving multimodal self-attention blocks throughout the networks. This double fusion mechanism (1) effectively enables rich multi-modal fusion while largely preserving the original strengths of the base models, and (2) catalyzes synergistic fusion of high-level semantic representations from the understanding encoder with low-level spatial signals from the generation encoder. By training with only ~ 35B tokens, this approach achieves strong results across multiple benchmarks: 0.91 on GenEval for compositional text-to-image generation, 82.16 on DPG-Bench for complex text-to-image generation, 6.06 on GEditBench, and 3.77 on ImgEdit-Bench for image editing. By fully releasing the entire suite of code, model weights, and datasets, we hope to support future research on unified multimodal modeling.
Probing Social Identity Bias in Chinese LLMs with Gendered Pronouns and Social Groups
Oct 08, 2025Large language models (LLMs) are increasingly deployed in user-facing applications, raising concerns about their potential to reflect and amplify social biases. We investigate social identity framing in Chinese LLMs using Mandarin-specific prompts across ten representative Chinese LLMs, evaluating responses to ingroup ("We") and outgroup ("They") framings, and extending the setting to 240 social groups salient in the Chinese context. To complement controlled experiments, we further analyze Chinese-language conversations from a corpus of real interactions between users and chatbots. Across models, we observe systematic ingroup-positive and outgroup-negative tendencies, which are not confined to synthetic prompts but also appear in naturalistic dialogue, indicating that bias dynamics might strengthen in real interactions. Our study provides a language-aware evaluation framework for Chinese LLMs, demonstrating that social identity biases documented in English generalize cross-linguistically and intensify in user-facing contexts.
Intelligent Virtual Sonographer (IVS): Enhancing Physician-Robot-Patient Communication
Jul 17, 2025The advancement and maturity of large language models (LLMs) and robotics have unlocked vast potential for human-computer interaction, particularly in the field of robotic ultrasound. While existing research primarily focuses on either patient-robot or physician-robot interaction, the role of an intelligent virtual sonographer (IVS) bridging physician-robot-patient communication remains underexplored. This work introduces a conversational virtual agent in Extended Reality (XR) that facilitates real-time interaction between physicians, a robotic ultrasound system(RUS), and patients. The IVS agent communicates with physicians in a professional manner while offering empathetic explanations and reassurance to patients. Furthermore, it actively controls the RUS by executing physician commands and transparently relays these actions to the patient. By integrating LLM-powered dialogue with speech-to-text, text-to-speech, and robotic control, our system enhances the efficiency, clarity, and accessibility of robotic ultrasound acquisition. This work constitutes a first step toward understanding how IVS can bridge communication gaps in physician-robot-patient interaction, providing more control and therefore trust into physician-robot interaction while improving patient experience and acceptance of robotic ultrasound.
SignAligner: Harmonizing Complementary Pose Modalities for Coherent Sign Language Generation
Jun 13, 2025Sign language generation aims to produce diverse sign representations based on spoken language. However, achieving realistic and naturalistic generation remains a significant challenge due to the complexity of sign language, which encompasses intricate hand gestures, facial expressions, and body movements. In this work, we introduce PHOENIX14T+, an extended version of the widely-used RWTH-PHOENIX-Weather 2014T dataset, featuring three new sign representations: Pose, Hamer and Smplerx. We also propose a novel method, SignAligner, for realistic sign language generation, consisting of three stages: text-driven pose modalities co-generation, online collaborative correction of multimodality, and realistic sign video synthesis. First, by incorporating text semantics, we design a joint sign language generator to simultaneously produce posture coordinates, gesture actions, and body movements. The text encoder, based on a Transformer architecture, extracts semantic features, while a cross-modal attention mechanism integrates these features to generate diverse sign language representations, ensuring accurate mapping and controlling the diversity of modal features. Next, online collaborative correction is introduced to refine the generated pose modalities using a dynamic loss weighting strategy and cross-modal attention, facilitating the complementarity of information across modalities, eliminating spatiotemporal conflicts, and ensuring semantic coherence and action consistency. Finally, the corrected pose modalities are fed into a pre-trained video generation network to produce high-fidelity sign language videos. Extensive experiments demonstrate that SignAligner significantly improves both the accuracy and expressiveness of the generated sign videos.
CLEAR: A Clinically-Grounded Tabular Framework for Radiology Report Evaluation
May 22, 2025



Existing metrics often lack the granularity and interpretability to capture nuanced clinical differences between candidate and ground-truth radiology reports, resulting in suboptimal evaluation. We introduce a Clinically-grounded tabular framework with Expert-curated labels and Attribute-level comparison for Radiology report evaluation (CLEAR). CLEAR not only examines whether a report can accurately identify the presence or absence of medical conditions, but also assesses whether it can precisely describe each positively identified condition across five key attributes: first occurrence, change, severity, descriptive location, and recommendation. Compared to prior works, CLEAR's multi-dimensional, attribute-level outputs enable a more comprehensive and clinically interpretable evaluation of report quality. Additionally, to measure the clinical alignment of CLEAR, we collaborate with five board-certified radiologists to develop CLEAR-Bench, a dataset of 100 chest X-ray reports from MIMIC-CXR, annotated across 6 curated attributes and 13 CheXpert conditions. Our experiments show that CLEAR achieves high accuracy in extracting clinical attributes and provides automated metrics that are strongly aligned with clinical judgment.