 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyadic Partnership(DP): A Missing Link Towards Full Autonomy in Medical Robotics
Apr 13, 2026For the past decades medical robotic solutions were mostly based on the concept of tele-manipulation. While their design was extremely intelligent, allowing for better access, improved dexterity, reduced tremor, and improved imaging, their intelligence was limited. They therefore left cognition and decision making to the surgeon. As medical robotics advances towards high-level autonomy, the scientific community needs to explore the required pathway towards partial and full autonomy. Here, we introduce the concept of Dyadic Partnership(DP), a new paradigm in which robots and clinicians engage in intelligent, expert interaction and collaboration. The Dyadic Partners would discuss and agree on decisions and actions during their dynamic and interactive collaboration relying also on intuitive advanced media using generative AI, such as a world model, and advanced multi-modal visualization. This article outlines the foundational components needed to enable such systems, including foundation models for clinical intelligence, multi-modal intent recognition, co-learning frameworks, advanced visualization, and explainable, trust-aware interaction. We further discuss key challenges such as data scarcity, lack of standardization, and ethical acceptance. Dyadic partnership is introduced and is positioned as a powerful yet achievable, acceptable milestone offering a promising pathway toward safer, more intuitive collaboration and a gradual transition to full autonomy across diverse clinical settings.
From Scanning Guidelines to Action: A Robotic Ultrasound Agent with LLM-Based Reasoning
Mar 15, 2026Robotic ultrasound offers advantages over free-hand scanning, including improved reproducibility and reduced operator dependency. In clinical practice, US acquisition relies heavily on the sonographer's experience and situational judgment. When transferring this process to robotic systems, such expertise is often encoded explicitly through fixed procedures and task-specific models, yielding pipelines that can be difficult to adapt to new scanning tasks. In this work, we propose a unified framework for autonomous robotic US scanning that leverages a LLM-based agent to interpret US scanning guidelines and execute scans by dynamically invoking a set of provided software tools. Instead of encoding fixed scanning procedures, the LLM agent retrieves and reasons over guideline steps from scanning handbooks and adapts its planning decisions based on observations and the current scanning state. This enables the system to handle variable and decision-dependent workflows, such as adjusting scanning strategies, repeating steps, or selecting the appropriate next tool call in response to image quality or anatomical findings. Because the reasoning underlying tool selection is also critical for transparent and trustworthy planning, we further fine tune the LLM agent using a RL based strategy to improve both its reasoning quality and the correctness of tool selection and parameterization, while maintaining robust generalization to unseen guidelines and related tasks. We first validate the approach via verbal execution on 10 US scanning guidelines, assessing reasoning as well as tool selection and parameterization, and showing the benefit of RL fine tuning. We then demonstrate real world feasibility on robotic scanning of the gallbladder, spine, and kidney. Overall, the framework follows diverse guidelines and enables reliable autonomous scanning across multiple anatomical targets within a unified system.
Robotic Ultrasound Makes CBCT Alive
Mar 10, 2026Intraoperative Cone Beam Computed Tomography (CBCT) provides a reliable 3D anatomical context essential for interventional planning. However, its static nature fails to provide continuous monitoring of soft-tissue deformations induced by respiration, probe pressure, and surgical manipulation, leading to navigation discrepancies. We propose a deformation-aware CBCT updating framework that leverages robotic ultrasound as a dynamic proxy to infer tissue motion and update static CBCT slices in real time. Starting from calibration-initialized alignment with linear correlation of linear combination (LC2)-based rigid refinement, our method establishes accurate multimodal correspondence. To capture intraoperative dynamics, we introduce the ultrasound correlation UNet (USCorUNet), a lightweight network trained with optical flow-guided supervision to learn deformation-aware correlation representations, enabling accurate, real-time dense deformation field estimation from ultrasound streams. The inferred deformation is spatially regularized and transferred to the CBCT reference to produce deformation-consistent visualizations without repeated radiation exposure. We validate the proposed approach through deformation estimation and ultrasound-guided CBCT updating experiments. Results demonstrate real-time end-to-end CBCT slice updating and physically plausible deformation estimation, enabling dynamic refinement of static CBCT guidance during robotic ultrasound-assisted interventions. The source code is publicly available at https://github.com/anonymous-codebase/us-cbct-demo.
DAISS: Phase-Aware Imitation Learning for Dual-Arm Robotic Ultrasound-Guided Interventions
Mar 08, 2026Imitation learning has shown strong potential for automating complex robotic manipulation. In medical robotics, ultrasound-guided needle insertion demands precise bimanual coordination, as clinicians must simultaneously manipulate an ultrasound probe to maintain an optimal acoustic view while steering an interventional needle. Automating this asymmetric workflow -- and reliably transferring expert strategies to robots -- remains highly challenging. In this paper, we present the Dual-Arm Interventional Surgical System (DAISS), a teleoperated platform that collects high-fidelity dual-arm demonstrations and learns a phase-aware imitation policy for ultrasound-guided interventions. To avoid constraining the operator's natural behavior, DAISS uses a flexible NDI-based leader interface for teleoperating two coordinated follower arms. To support robust execution under real-time ultrasound feedback, we develop a lightweight, data-efficient imitation policy. Specifically, the policy incorporates a phase-aware architecture and a dynamic mask loss tailored to asymmetric bimanual control. Conditioned on a planned trajectory, the network fuses real-time ultrasound with external visual observations to generate smooth, coordinated dual-arm motions. Experimental results show that DAISS can learn personalized expert strategies from limited demonstrations. Overall, these findings highlight the promise of phase-aware imitation-learning-driven dual-arm robots for improving precision and reducing cognitive workload in image-guided interventions.
ConVibNet: Needle Detection during Continuous Insertion via Frequency-Inspired Features
Mar 01, 2026Purpose: Ultrasound-guided needle interventions are widely used in clinical practice, but their success critically depends on accurate needle placement, which is frequently hindered by the poor and intermittent visibility of needles in ultrasound images. Existing approaches remain limited by artifacts, occlusions, and low contrast, and often fail to support real-time continuous insertion. To overcome these challenges, this study introduces a robust real-time framework for continuous needle detection. Methods: We present ConVibNet, an extension of VibNet for detecting needles with significantly reduced visibility, addressing real-time, continuous needle tracking during insertion. ConVibNet leverages temporal dependencies across successive ultrasound frames to enable continuous estimation of both needle tip position and shaft angle in dynamic scenarios. To strengthen temporal awareness of needle-tip motion, we introduce a novel intersection-and-difference loss that explicitly leverages motion correlations across consecutive frames. In addition, we curated a dedicated dataset for model development and evaluation. Results: The performance of the proposed ConVibNet model was evaluated on our dataset, demonstrating superior accuracy compared to the baseline VibNet and UNet-LSTM models. Specifically, ConVibNet achieved a tip error of 2.80+-2.42 mm and an angle error of 1.69+-2.00 deg. These results represent a 0.75 mm improvement in tip localization accuracy over the best-performing baseline, while preserving real-time inference capability. Conclusion: ConVibNet advances real-time needle detection in ultrasound-guided interventions by integrating temporal correlation modeling with a novel intersection-and-difference loss, thereby improving accuracy and robustness and demonstrating high potential for integration into autonomous insertion systems.
RAG-RUSS: A Retrieval-Augmented Robotic Ultrasound for Autonomous Carotid Examination
Mar 01, 2026Robotic ultrasound (US) has recently attracted increasing attention as a means to overcome the limitations of conventional US examinations, such as the strong operator dependence. However, the decision-making process of existing methods is often either rule-based or relies on end-to-end learning models that operate as black boxes. This has been seen as a main limit for clinical acceptance and raises safety concerns for widespread adoption in routine practice. To tackle this challenge, we introduce the RAG-RUSS, an interpretable framework capable of performing a full carotid examination in accordance with the clinical workflow while explicitly explaining both the current stage and the next planned action. Furthermore, given the scarcity of medical data, we incorporate retrieval-augmented generation to enhance generalization and reduce dependence on large-scale training datasets. The method was trained on data acquired from 28 volunteers, while an additional four volumetric scans recorded from previously unseen volunteers were reserved for testing. The results demonstrate that the method can explain the current scanning stage and autonomously plan probe motions to complete the carotid examination, encompassing both transverse and longitudinal planes.
Ultrasound-Guided Real-Time Spinal Motion Visualization for Spinal Instability Assessment
Feb 13, 2026Purpose: Spinal instability is a widespread condition that causes pain, fatigue, and restricted mobility, profoundly affecting patients' quality of life. In clinical practice, the gold standard for diagnosis is dynamic X-ray imaging. However, X-ray provides only 2D motion information, while 3D modalities such as computed tomography (CT) or cone beam computed tomography (CBCT) cannot efficiently capture motion. Therefore, there is a need for a system capable of visualizing real-time 3D spinal motion while minimizing radiation exposure. Methods: We propose ultrasound as an auxiliary modality for 3D spine visualization. Due to acoustic limitations, ultrasound captures only the superficial spinal surface. Therefore, the partially compounded ultrasound volume is registered to preoperative 3D imaging. In this study, CBCT provides the neutral spine configuration, while robotic ultrasound acquisition is performed at maximal spinal bending. A kinematic model is applied to the CBCT-derived spine model for coarse registration, followed by ICP for fine registration, with kinematic parameters optimized based on the registration results. Real-time ultrasound motion tracking is then used to estimate continuous 3D spinal motion by interpolating between the neutral and maximally bent states. Results: The pipeline was evaluated on a bendable 3D-printed lumbar spine phantom. The registration error was $1.941 \pm 0.199$ mm and the interpolated spinal motion error was $2.01 \pm 0.309$ mm (median). Conclusion: The proposed robotic ultrasound framework enables radiation-reduced, real-time 3D visualization of spinal motion, offering a promising 3D alternative to conventional dynamic X-ray imaging for assessing spinal instability.
Vibration-Based Energy Metric for Restoring Needle Alignment in Autonomous Robotic Ultrasound
Aug 09, 2025Precise needle alignment is essential for percutaneous needle insertion in robotic ultrasound-guided procedures. However, inherent challenges such as speckle noise, needle-like artifacts, and low image resolution make robust needle detection difficult, particularly when visibility is reduced or lost. In this paper, we propose a method to restore needle alignment when the ultrasound imaging plane and the needle insertion plane are misaligned. Unlike many existing approaches that rely heavily on needle visibility in ultrasound images, our method uses a more robust feature by periodically vibrating the needle using a mechanical system. Specifically, we propose a vibration-based energy metric that remains effective even when the needle is fully out of plane. Using this metric, we develop a control strategy to reposition the ultrasound probe in response to misalignments between the imaging plane and the needle insertion plane in both translation and rotation. Experiments conducted on ex-vivo porcine tissue samples using a dual-arm robotic ultrasound-guided needle insertion system demonstrate the effectiveness of the proposed approach. The experimental results show the translational error of 0.41$\pm$0.27 mm and the rotational error of 0.51$\pm$0.19 degrees.
Tactile-Guided Robotic Ultrasound: Mapping Preplanned Scan Paths for Intercostal Imaging
Jul 27, 2025
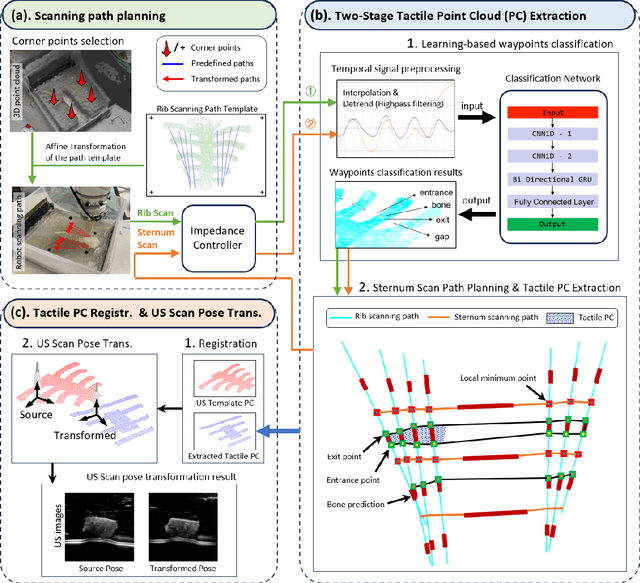
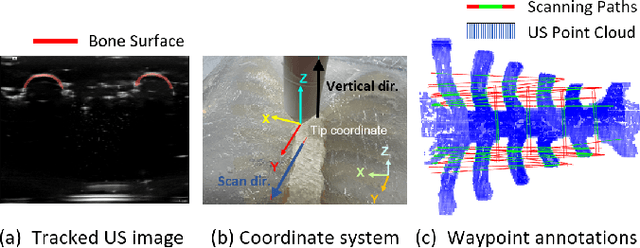
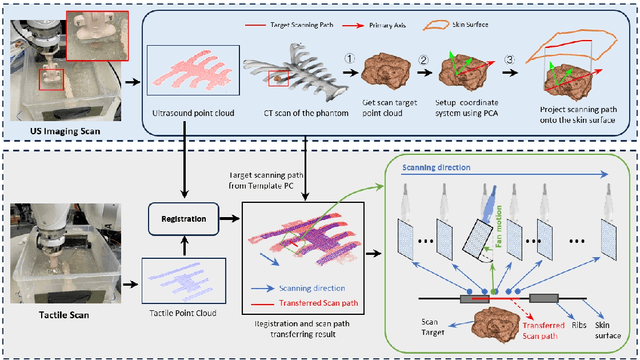
Medical ultrasound (US) imaging is widely used in clinical examinations due to its portability, real-time capability, and radiation-free nature. To address inter- and intra-operator variability, robotic ultrasound systems have gained increasing attention. However, their application in challenging intercostal imaging remains limited due to the lack of an effective scan path generation method within the constrained acoustic window. To overcome this challenge, we explore the potential of tactile cues for characterizing subcutaneous rib structures as an alternative signal for ultrasound segmentation-free bone surface point cloud extraction. Compared to 2D US images, 1D tactile-related signals offer higher processing efficiency and are less susceptible to acoustic noise and artifacts. By leveraging robotic tracking data, a sparse tactile point cloud is generated through a few scans along the rib, mimicking human palpation. To robustly map the scanning trajectory into the intercostal space, the sparse tactile bone location point cloud is first interpolated to form a denser representation. This refined point cloud is then registered to an image-based dense bone surface point cloud, enabling accurate scan path mapping for individual patients. Additionally, to ensure full coverage of the object of interest, we introduce an automated tilt angle adjustment method to visualize structures beneath the bone. To validate the proposed method, we conducted comprehensive experiments on four distinct phantoms. The final scanning waypoint mapping achieved Mean Nearest Neighbor Distance (MNND) and Hausdorff distance (HD) errors of 3.41 mm and 3.65 mm, respectively, while the reconstructed object beneath the bone had errors of 0.69 mm and 2.2 mm compared to the CT ground truth.
Intelligent Virtual Sonographer (IVS): Enhancing Physician-Robot-Patient Communication
Jul 17, 2025The advancement and maturity of large language models (LLMs) and robotics have unlocked vast potential for human-computer interaction, particularly in the field of robotic ultrasound. While existing research primarily focuses on either patient-robot or physician-robot interaction, the role of an intelligent virtual sonographer (IVS) bridging physician-robot-patient communication remains underexplored. This work introduces a conversational virtual agent in Extended Reality (XR) that facilitates real-time interaction between physicians, a robotic ultrasound system(RUS), and patients. The IVS agent communicates with physicians in a professional manner while offering empathetic explanations and reassurance to patients. Furthermore, it actively controls the RUS by executing physician commands and transparently relays these actions to the patient. By integrating LLM-powered dialogue with speech-to-text, text-to-speech, and robotic control, our system enhances the efficiency, clarity, and accessibility of robotic ultrasound acquisition. This work constitutes a first step toward understanding how IVS can bridge communication gaps in physician-robot-patient interaction, providing more control and therefore trust into physician-robot interaction while improving patient experience and acceptance of robotic ultrasound.