 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Efficiently Adapt Foundation Models for Self-Supervised Endoscopic 3D Scene Reconstruction from Any Cameras
Mar 20, 2025

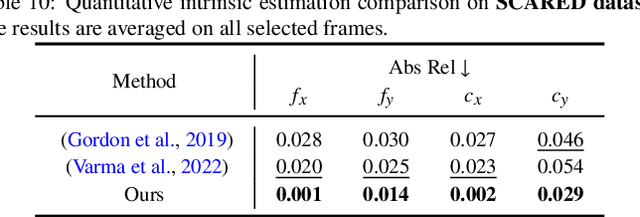
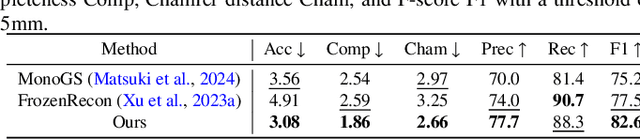
Accurate 3D scene reconstruction is essential for numerous medical tasks. Given the challenges in obtaining ground truth data, there has been an increasing focus on self-supervised learning (SSL) for endoscopic depth estimation as a basis for scene reconstruction. While foundation models have shown remarkable progress in visual tasks, their direct application to the medical domain often leads to suboptimal results. However, the visual features from these models can still enhance endoscopic tasks, emphasizing the need for efficient adaptation strategies, which still lack exploration currently. In this paper, we introduce Endo3DAC, a unified framework for endoscopic scene reconstruction that efficiently adapts foundation models. We design an integrated network capable of simultaneously estimating depth maps, relative poses, and camera intrinsic parameters. By freezing the backbone foundation model and training only the specially designed Gated Dynamic Vector-Based Low-Rank Adaptation (GDV-LoRA) with separate decoder heads, Endo3DAC achieves superior depth and pose estimation while maintaining training efficiency. Additionally, we propose a 3D scene reconstruction pipeline that optimizes depth maps' scales, shifts, and a few parameters based on our integrated network. Extensive experiments across four endoscopic datasets demonstrate that Endo3DAC significantly outperforms other state-of-the-art methods while requiring fewer trainable parameters. To our knowledge, we are the first to utilize a single network that only requires surgical videos to perform both SSL depth estimation and scene reconstruction tasks. The code will be released upon acceptance.
SurgicalVLM-Agent: Towards an Interactive AI Co-Pilot for Pituitary Surgery
Mar 12, 2025Image-guided surgery demands adaptive, real-time decision support, yet static AI models struggle with structured task planning and providing interactive guidance. Large vision-language models (VLMs) offer a promising solution by enabling dynamic task planning and predictive decision support. We introduce SurgicalVLM-Agent, an AI co-pilot for image-guided pituitary surgery, capable of conversation, planning, and task execution. The agent dynamically processes surgeon queries and plans the tasks such as MRI tumor segmentation, endoscope anatomy segmentation, overlaying preoperative imaging with intraoperative views, instrument tracking, and surgical visual question answering (VQA). To enable structured task planning, we develop the PitAgent dataset, a surgical context-aware dataset covering segmentation, overlaying, instrument localization, tool tracking, tool-tissue interactions, phase identification, and surgical activity recognition. Additionally, we propose FFT-GaLore, a fast Fourier transform (FFT)-based gradient projection technique for efficient low-rank adaptation, optimizing fine-tuning for LLaMA 3.2 in surgical environments. We validate SurgicalVLM-Agent by assessing task planning and prompt generation on our PitAgent dataset and evaluating zero-shot VQA using a public pituitary dataset. Results demonstrate state-of-the-art performance in task planning and query interpretation, with highly semantically meaningful VQA responses, advancing AI-driven surgical assistance.
Endo-FASt3r: Endoscopic Foundation model Adaptation for Structure from motion
Mar 10, 2025Accurate depth and camera pose estimation is essential for achieving high-quality 3D visualisations in robotic-assisted surgery. Despite recent advancements in foundation model adaptation to monocular depth estimation of endoscopic scenes via self-supervised learning (SSL), no prior work has explored their use for pose estimation. These methods rely on low rank-based adaptation approaches, which constrain model updates to a low-rank space. We propose Endo-FASt3r, the first monocular SSL depth and pose estimation framework that uses foundation models for both tasks. We extend the Reloc3r relative pose estimation foundation model by designing Reloc3rX, introducing modifications necessary for convergence in SSL. We also present DoMoRA, a novel adaptation technique that enables higher-rank updates and faster convergence. Experiments on the SCARED dataset show that Endo-FASt3r achieves a substantial $10\%$ improvement in pose estimation and a $2\%$ improvement in depth estimation over prior work. Similar performance gains on the Hamlyn and StereoMIS datasets reinforce the generalisability of Endo-FASt3r across different datasets.
PitVQA++: Vector Matrix-Low-Rank Adaptation for Open-Ended Visual Question Answering in Pituitary Surgery
Feb 19, 2025Vision-Language Models (VLMs) in visual question answering (VQA) offer a unique opportunity to enhance intra-operative decision-making, promote intuitive interactions, and significantly advancing surgical education. However, the development of VLMs for surgical VQA is challenging due to limited datasets and the risk of overfitting and catastrophic forgetting during full fine-tuning of pretrained weights. While parameter-efficient techniques like Low-Rank Adaptation (LoRA) and Matrix of Rank Adaptation (MoRA) address adaptation challenges, their uniform parameter distribution overlooks the feature hierarchy in deep networks, where earlier layers, that learn general features, require more parameters than later ones. This work introduces PitVQA++ with an open-ended PitVQA dataset and vector matrix-low-rank adaptation (Vector-MoLoRA), an innovative VLM fine-tuning approach for adapting GPT-2 to pituitary surgery. Open-Ended PitVQA comprises around 101,803 frames from 25 procedural videos with 745,972 question-answer sentence pairs, covering key surgical elements such as phase and step recognition, context understanding, tool detection, localization, and interactions recognition. Vector-MoLoRA incorporates the principles of LoRA and MoRA to develop a matrix-low-rank adaptation strategy that employs vector ranking to allocate more parameters to earlier layers, gradually reducing them in the later layers. Our approach, validated on the Open-Ended PitVQA and EndoVis18-VQA datasets, effectively mitigates catastrophic forgetting while significantly enhancing performance over recent baselines. Furthermore, our risk-coverage analysis highlights its enhanced reliability and trustworthiness in handling uncertain predictions. Our source code and dataset is available at~\url{https://github.com/HRL-Mike/PitVQA-Plus}.
Transferring Knowledge from High-Quality to Low-Quality MRI for Adult Glioma Diagnosis
Oct 24, 2024Glioma, a common and deadly brain tumor, requires early diagnosis for improved prognosis. However, low-quality Magnetic Resonance Imaging (MRI) technology in Sub-Saharan Africa (SSA) hinders accurate diagnosis. This paper presents our work in the BraTS Challenge on SSA Adult Glioma. We adopt the model from the BraTS-GLI 2021 winning solution and utilize it with three training strategies: (1) initially training on the BraTS-GLI 2021 dataset with fine-tuning on the BraTS-Africa dataset, (2) training solely on the BraTS-Africa dataset, and (3) training solely on the BraTS-Africa dataset with 2x super-resolution enhancement. Results show that initial training on the BraTS-GLI 2021 dataset followed by fine-tuning on the BraTS-Africa dataset has yielded the best results. This suggests the importance of high-quality datasets in providing prior knowledge during training. Our top-performing model achieves Dice scores of 0.882, 0.840, and 0.926, and Hausdorff Distance (95%) scores of 15.324, 37.518, and 13.971 for enhancing tumor, tumor core, and whole tumor, respectively, in the validation phase. In the final phase of the competition, our approach successfully secured second place overall, reflecting the strength and effectiveness of our model and training strategies. Our approach provides insights into improving glioma diagnosis in SSA, showing the potential of deep learning in resource-limited settings and the importance of transfer learning from high-quality datasets.
SurgicalGS: Dynamic 3D Gaussian Splatting for Accurate Robotic-Assisted Surgical Scene Reconstruction
Oct 11, 2024



Accurate 3D reconstruction of dynamic surgical scenes from endoscopic video is essential for robotic-assisted surgery. While recent 3D Gaussian Splatting methods have shown promise in achieving high-quality reconstructions with fast rendering speeds, their use of inverse depth loss functions compresses depth variations. This can lead to a loss of fine geometric details, limiting their ability to capture precise 3D geometry and effectiveness in intraoperative application. To address these challenges, we present SurgicalGS, a dynamic 3D Gaussian Splatting framework specifically designed for surgical scene reconstruction with improved geometric accuracy. Our approach first initialises a Gaussian point cloud using depth priors, employing binary motion masks to identify pixels with significant depth variations and fusing point clouds from depth maps across frames for initialisation. We use the Flexible Deformation Model to represent dynamic scene and introduce a normalised depth regularisation loss along with an unsupervised depth smoothness constraint to ensure more accurate geometric reconstruction. Extensive experiments on two real surgical datasets demonstrate that SurgicalGS achieves state-of-the-art reconstruction quality, especially in terms of accurate geometry, advancing the usability of 3D Gaussian Splatting in robotic-assisted surgery.
DARES: Depth Anything in Robotic Endoscopic Surgery with Self-supervised Vector-LoRA of the Foundation Model
Aug 30, 2024



Robotic-assisted surgery (RAS) relies on accurate depth estimation for 3D reconstruction and visualization. While foundation models like Depth Anything Models (DAM) show promise, directly applying them to surgery often yields suboptimal results. Fully fine-tuning on limited surgical data can cause overfitting and catastrophic forgetting, compromising model robustness and generalization. Although Low-Rank Adaptation (LoRA) addresses some adaptation issues, its uniform parameter distribution neglects the inherent feature hierarchy, where earlier layers, learning more general features, require more parameters than later ones. To tackle this issue, we introduce Depth Anything in Robotic Endoscopic Surgery (DARES), a novel approach that employs a new adaptation technique, Vector Low-Rank Adaptation (Vector-LoRA) on the DAM V2 to perform self-supervised monocular depth estimation in RAS scenes. To enhance learning efficiency, we introduce Vector-LoRA by integrating more parameters in earlier layers and gradually decreasing parameters in later layers. We also design a reprojection loss based on the multi-scale SSIM error to enhance depth perception by better tailoring the foundation model to the specific requirements of the surgical environment. The proposed method is validated on the SCARED dataset and demonstrates superior performance over recent state-of-the-art self-supervised monocular depth estimation techniques, achieving an improvement of 13.3% in the absolute relative error metric. The code and pre-trained weights are available at https://github.com/mobarakol/DARES.
Surgical-VQLA++: Adversarial Contrastive Learning for Calibrated Robust Visual Question-Localized Answering in Robotic Surgery
Aug 09, 2024Medical visual question answering (VQA) bridges the gap between visual information and clinical decision-making, enabling doctors to extract understanding from clinical images and videos. In particular, surgical VQA can enhance the interpretation of surgical data, aiding in accurate diagnoses, effective education, and clinical interventions. However, the inability of VQA models to visually indicate the regions of interest corresponding to the given questions results in incomplete comprehension of the surgical scene. To tackle this, we propose the surgical visual question localized-answering (VQLA) for precise and context-aware responses to specific queries regarding surgical images. Furthermore, to address the strong demand for safety in surgical scenarios and potential corruptions in image acquisition and transmission, we propose a novel approach called Calibrated Co-Attention Gated Vision-Language (C$^2$G-ViL) embedding to integrate and align multimodal information effectively. Additionally, we leverage the adversarial sample-based contrastive learning strategy to boost our performance and robustness. We also extend our EndoVis-18-VQLA and EndoVis-17-VQLA datasets to broaden the scope and application of our data. Extensive experiments on the aforementioned datasets demonstrate the remarkable performance and robustness of our solution. Our solution can effectively combat real-world image corruption. Thus, our proposed approach can serve as an effective tool for assisting surgical education, patient care, and enhancing surgical outcomes.
SAM 2 in Robotic Surgery: An Empirical Evaluation for Robustness and Generalization in Surgical Video Segmentation
Aug 08, 2024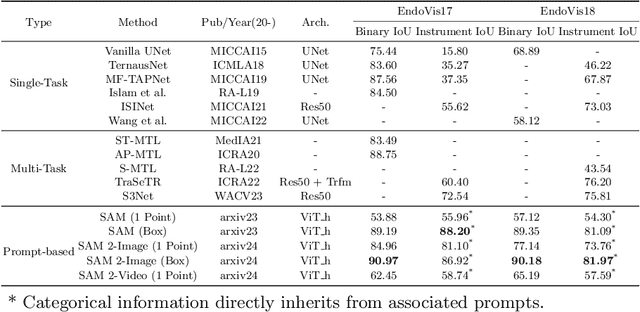



The recent Segment Anything Model (SAM) 2 has demonstrated remarkable foundational competence in semantic segmentation, with its memory mechanism and mask decoder further addressing challenges in video tracking and object occlusion, thereby achieving superior results in interactive segmentation for both images and videos. Building upon our previous empirical studies, we further explore the zero-shot segmentation performance of SAM 2 in robot-assisted surgery based on prompts, alongside its robustness against real-world corruption. For static images, we employ two forms of prompts: 1-point and bounding box, while for video sequences, the 1-point prompt is applied to the initial frame. Through extensive experimentation on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 2, when utilizing bounding box prompts, outperforms state-of-the-art (SOTA) methods in comparative evaluations. The results with point prompts also exhibit a substantial enhancement over SAM's capabilities, nearing or even surpassing existing unprompted SOTA methodologies. Besides, SAM 2 demonstrates improved inference speed and less performance degradation against various image corruption. Although slightly unsatisfactory results remain in specific edges or regions, SAM 2's robust adaptability to 1-point prompts underscores its potential for downstream surgical tasks with limited prompt requirements.
EndoUIC: Promptable Diffusion Transformer for Unified Illumination Correction in Capsule Endoscopy
Jun 19, 2024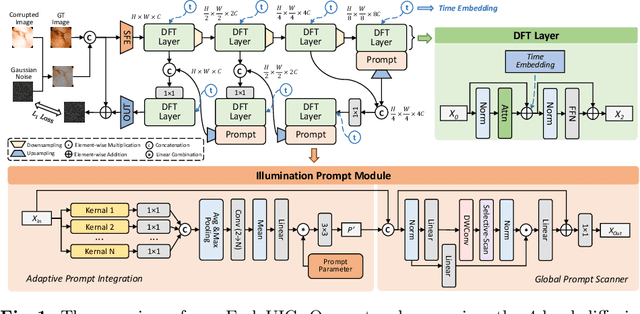



Wireless Capsule Endoscopy (WCE) is highly valued for its non-invasive and painless approach, though its effectiveness is compromised by uneven illumination from hardware constraints and complex internal dynamics, leading to overexposed or underexposed images. While researchers have discussed the challenges of low-light enhancement in WCE, the issue of correcting for different exposure levels remains underexplored. To tackle this, we introduce EndoUIC, a WCE unified illumination correction solution using an end-to-end promptable diffusion transformer (DFT) model. In our work, the illumination prompt module shall navigate the model to adapt to different exposure levels and perform targeted image enhancement, in which the Adaptive Prompt Integration (API) and Global Prompt Scanner (GPS) modules shall further boost the concurrent representation learning between the prompt parameters and features. Besides, the U-shaped restoration DFT model shall capture the long-range dependencies and contextual information for unified illumination restoration. Moreover, we present a novel Capsule-endoscopy Exposure Correction (CEC) dataset, including ground-truth and corrupted image pairs annotated by expert photographers. Extensive experiments against a variety of state-of-the-art (SOTA) methods on four datasets showcase the effectiveness of our proposed method and components in WCE illumination restoration, and the additional downstream experiments further demonstrate its utility for clinical diagnosis and surgical assistance.