 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndoUIC: Promptable Diffusion Transformer for Unified Illumination Correction in Capsule Endoscopy
Jun 19, 2024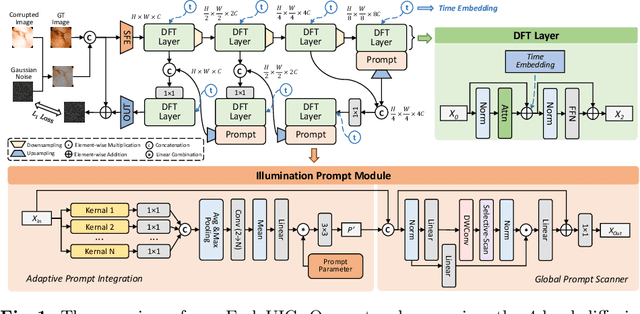



Wireless Capsule Endoscopy (WCE) is highly valued for its non-invasive and painless approach, though its effectiveness is compromised by uneven illumination from hardware constraints and complex internal dynamics, leading to overexposed or underexposed images. While researchers have discussed the challenges of low-light enhancement in WCE, the issue of correcting for different exposure levels remains underexplored. To tackle this, we introduce EndoUIC, a WCE unified illumination correction solution using an end-to-end promptable diffusion transformer (DFT) model. In our work, the illumination prompt module shall navigate the model to adapt to different exposure levels and perform targeted image enhancement, in which the Adaptive Prompt Integration (API) and Global Prompt Scanner (GPS) modules shall further boost the concurrent representation learning between the prompt parameters and features. Besides, the U-shaped restoration DFT model shall capture the long-range dependencies and contextual information for unified illumination restoration. Moreover, we present a novel Capsule-endoscopy Exposure Correction (CEC) dataset, including ground-truth and corrupted image pairs annotated by expert photographers. Extensive experiments against a variety of state-of-the-art (SOTA) methods on four datasets showcase the effectiveness of our proposed method and components in WCE illumination restoration, and the additional downstream experiments further demonstrate its utility for clinical diagnosis and surgical assistance.
Text in the Dark: Extremely Low-Light Text Image Enhancement
Apr 22, 2024



Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.