 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDentalX: Context-Aware Dental Disease Detection with Radiographs
Jan 13, 2026Diagnosing dental diseases from radiographs is time-consuming and challenging due to the subtle nature of diagnostic evidence. Existing methods, which rely on object detection models designed for natural images with more distinct target patterns, struggle to detect dental diseases that present with far less visual support. To address this challenge, we propose {\bf DentalX}, a novel context-aware dental disease detection approach that leverages oral structure information to mitigate the visual ambiguity inherent in radiographs. Specifically, we introduce a structural context extraction module that learns an auxiliary task: semantic segmentation of dental anatomy. The module extracts meaningful structural context and integrates it into the primary disease detection task to enhance the detection of subtle dental diseases. Extensive experiments on a dedicated benchmark demonstrate that DentalX significantly outperforms prior methods in both tasks. This mutual benefit arises naturally during model optimization, as the correlation between the two tasks is effectively captured. Our code is available at https://github.com/zhiqin1998/DentYOLOX.
Bayesian Detector Combination for Object Detection with Crowdsourced Annotations
Jul 10, 2024



Acquiring fine-grained object detection annotations in unconstrained images is time-consuming, expensive, and prone to noise, especially in crowdsourcing scenarios. Most prior object detection methods assume accurate annotations; A few recent works have studied object detection with noisy crowdsourced annotations, with evaluation on distinct synthetic crowdsourced datasets of varying setups under artificial assumptions. To address these algorithmic limitations and evaluation inconsistency, we first propose a novel Bayesian Detector Combination (BDC) framework to more effectively train object detectors with noisy crowdsourced annotations, with the unique ability of automatically inferring the annotators' label qualities. Unlike previous approaches, BDC is model-agnostic, requires no prior knowledge of the annotators' skill level, and seamlessly integrates with existing object detection models. Due to the scarcity of real-world crowdsourced datasets, we introduce large synthetic datasets by simulating varying crowdsourcing scenarios. This allows consistent evaluation of different models at scale. Extensive experiments on both real and synthetic crowdsourced datasets show that BDC outperforms existing state-of-the-art methods, demonstrating its superiority in leveraging crowdsourced data for object detection. Our code and data are available at https://github.com/zhiqin1998/bdc.
Text in the Dark: Extremely Low-Light Text Image Enhancement
Apr 22, 2024



Extremely low-light text images are common in natural scenes, making scene text detection and recognition challenging. One solution is to enhance these images using low-light image enhancement methods before text extraction. However, previous methods often do not try to particularly address the significance of low-level features, which are crucial for optimal performance on downstream scene text tasks. Further research is also hindered by the lack of extremely low-light text datasets. To address these limitations, we propose a novel encoder-decoder framework with an edge-aware attention module to focus on scene text regions during enhancement. Our proposed method uses novel text detection and edge reconstruction losses to emphasize low-level scene text features, leading to successful text extraction. Additionally, we present a Supervised Deep Curve Estimation (Supervised-DCE) model to synthesize extremely low-light images based on publicly available scene text datasets such as ICDAR15 (IC15). We also labeled texts in the extremely low-light See In the Dark (SID) and ordinary LOw-Light (LOL) datasets to allow for objective assessment of extremely low-light image enhancement through scene text tasks. Extensive experiments show that our model outperforms state-of-the-art methods in terms of both image quality and scene text metrics on the widely-used LOL, SID, and synthetic IC15 datasets. Code and dataset will be released publicly at https://github.com/chunchet-ng/Text-in-the-Dark.
An Embarrassingly Simple Approach for Intellectual Property Rights Protection on Recurrent Neural Networks
Oct 04, 2022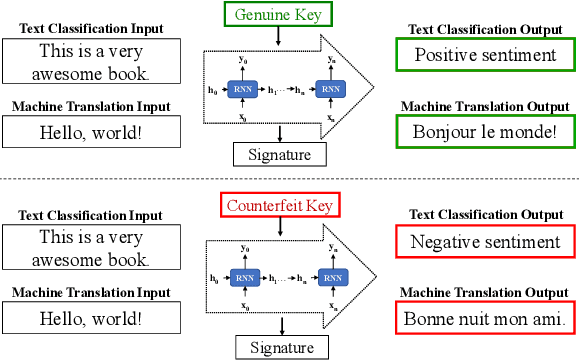

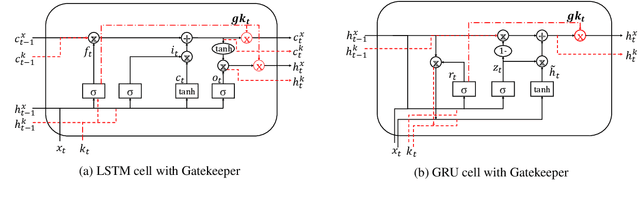
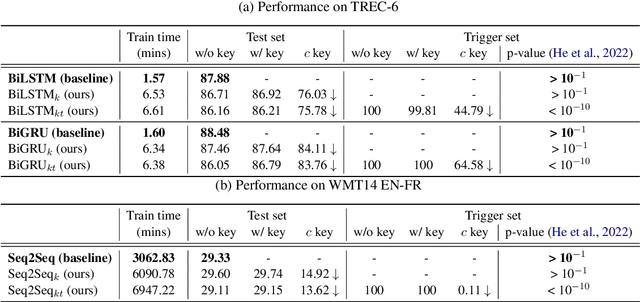
Capitalise on deep learning models, offering Natural Language Processing (NLP) solutions as a part of the Machine Learning as a Service (MLaaS) has generated handsome revenues. At the same time, it is known that the creation of these lucrative deep models is non-trivial. Therefore, protecting these inventions intellectual property rights (IPR) from being abused, stolen and plagiarized is vital. This paper proposes a practical approach for the IPR protection on recurrent neural networks (RNN) without all the bells and whistles of existing IPR solutions. Particularly, we introduce the Gatekeeper concept that resembles the recurrent nature in RNN architecture to embed keys. Also, we design the model training scheme in a way such that the protected RNN model will retain its original performance iff a genuine key is presented. Extensive experiments showed that our protection scheme is robust and effective against ambiguity and removal attacks in both white-box and black-box protection schemes on different RNN variants. Code is available at https://github.com/zhiqin1998/RecurrentIPR